

2018年5月17日 神保町にある一橋大学 一橋講堂にて機械学習工学研究会(以下MLSE)のキックオフシンポジウムが開催されました。
急激に社会に浸透しはじめている機械学習技術は、従来のソフトウェア開発とは相異なるものです。
機械学習技術ではデータの整備の重要性、プロジェクトの長期化、他にもさまざまな課題があり、それらを適切に解決しないといけません。
MLSEは機械学習システムにおいて、「機械学習工学」ともいうべき、新たな体系が必用だとの意見に基づき、日本ソフトウェア科学会の研究会のひとつとしてMLSEを発足させました。
この日は、そのキックオフイベントということで、ソフトウェア工学の権威から第一線を走るデータサイエンティストなど、多くのスペシャリストが登壇し、機械学習の重要性や課題を多方面から説きました。
今回は、キックオフ当日に行われた基調講演の内容をみなさまにお届けします。
目次
ソフトウェア工学における問題提起と機械学習の新たなあり方

また登壇してくださったのは、工藤卓哉さん(アクセンチュアUSA Data Science Center of Excellence グローバル統括 / ARISE analytics CSO))です。
「AI/機械学習は活用の時代へ」
機械学習は社会に実装され、活用される時代になります。これは分散処理やディープラーニングの活用により、画像・音声認識の精度やスピードが大幅に向上したことが理由としてあげられます。また、IoTデバイスが増えたことで、大量のデータを取得できるようになり、オープンイノベーションが進んだことで、最新の研究を誰もが気軽に使える環境も揃っています。
従来のプログラミングは、ルールをコーディングしていましたが、機械学習技術では、教師データと呼ばれる正解データを与えることでルールの生成を自動化してしまっています。
しかし、この機械学習領域において、熟慮すべきソフトウェア開発における基礎的なエンジニアリングアプローチ、開発工学更には、運用設計が軽視される傾向が大変強いことに工藤さんは警鐘を鳴らしています。
機械学習ではその特徴的な手法ばかりに気を取られて、基礎的なエンジニアアプローチ、開発工学、そして運用設計が軽視される傾向が強いです。
機械学習はバラ色な技術ではありません。さまざまな壁があります。ほとんどの機械学習案件は仕様が決まってから、準委任契約で、発注側や受注側の知識不足で計画が頓挫してしまうことが多いです。モデルが実用的か検証するためのPoCを終えたあとにプロジェクトがなくなってしまうケースも大変多いといいます。
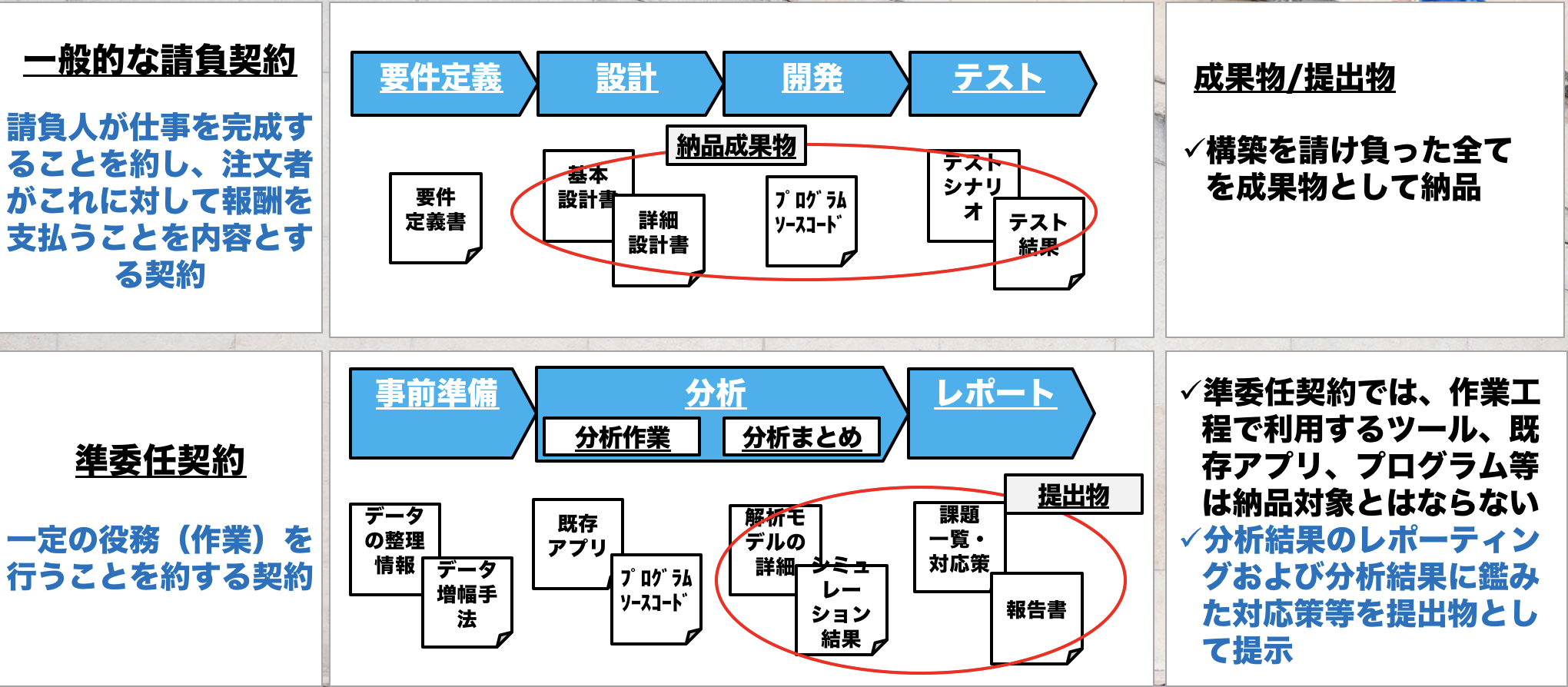
機械学習において盲点となりがちな基礎として
- 想定ユースケース
- 業務目線のKPI
- 開発工程管理のKPI
- ソフトウェア品質保証のKPI
- システム稼働におけるSLAのKPI
- モデルチューニングにおける完了基準のKPI
- サービス損益分岐点におけるコストサイド算出目線のKPI
- スコープ、リスク管理におけるKPI
などが重要です。
従来のソフトウェア開発工学における基礎としても
- リスク管理
- 要求管理
- 変更管理
などが非常に重要です。
では、機械学習案件と従来のソフトウェア案件の共通項はなんでしょうか?
それは、「期待値コントロール」です。
そのためにも
- 混合行列の精度追求
- 稼働判定におけるスケジュール通り、予算通りのサービスリリース
- データサービス利用率、顧客満足度の追求
などを心がけていかなければなりません。
機械学習適用の7つのステップ
2つ目のテーマは機械学習適用のステップについてでした。

開発プロセスへの機械学習開発の融合
機械学習やデータ分析モデルは、構築するまでどの程度の精度が出せるのかの見積もりがとてもむずかしいです。そのため、従来のような開発プロセスではなく、トライアンドエラーを繰り返すプロセスが、向いています。ソフトウェア工学で使われていたプロセスと機械学習でのトライアンドエラーを繰り返すプロセスを融合していく必要があります。
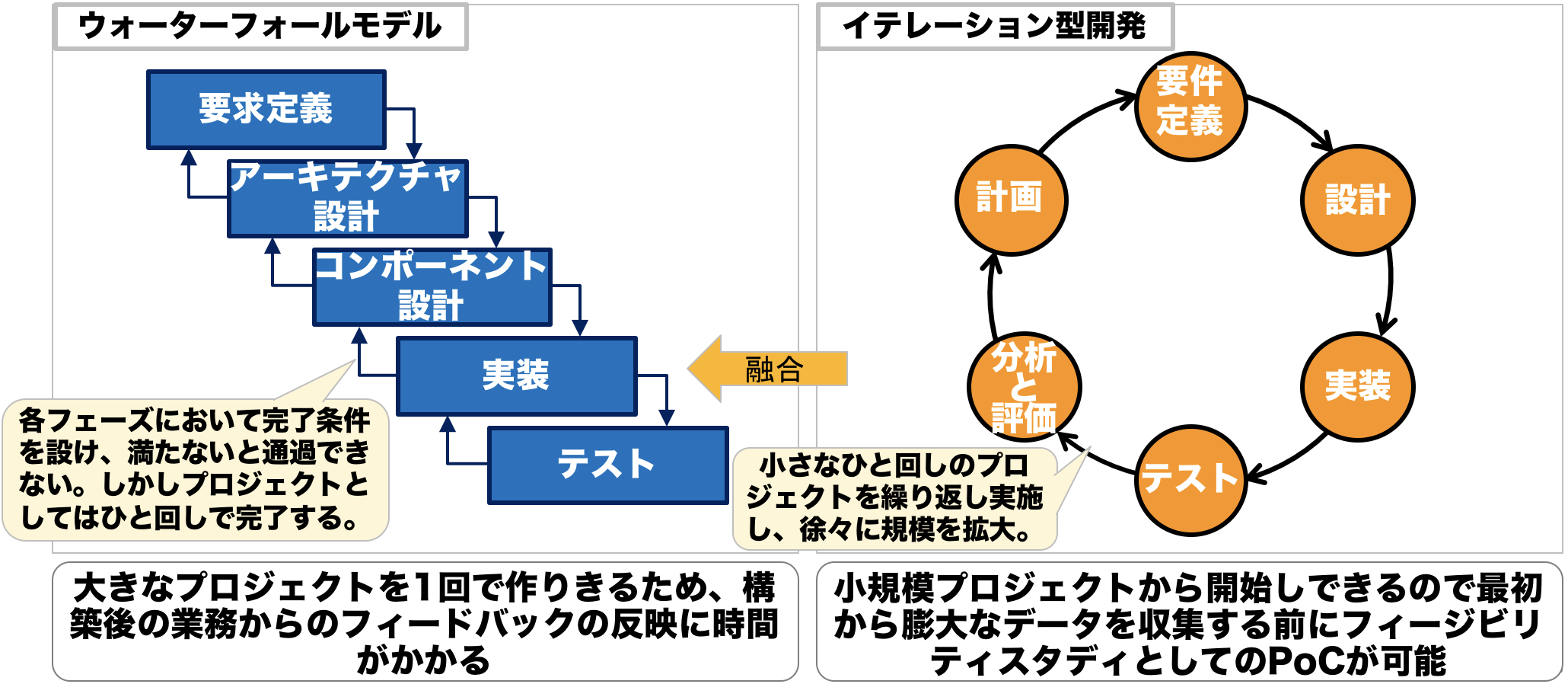
従来の開発プロセスは代表的なものがウォーターフォールモデルです。まず要件定義をして、そこから各フェーズに合わせた条件をクリアしていき、1回で大きなプロジェクトを作り上げます。この手法は、精度の予想しづらい機械学習には向いていません。
イテレーション開発では、小規模なプロジェクトから開発して、PoCという実証実験などを行い、ほんとうにそのプロジェクトが成功するのか否かを随時確認しながら進めていきます。
この2つの開発プロセスが融合すると以下の図のようになります。
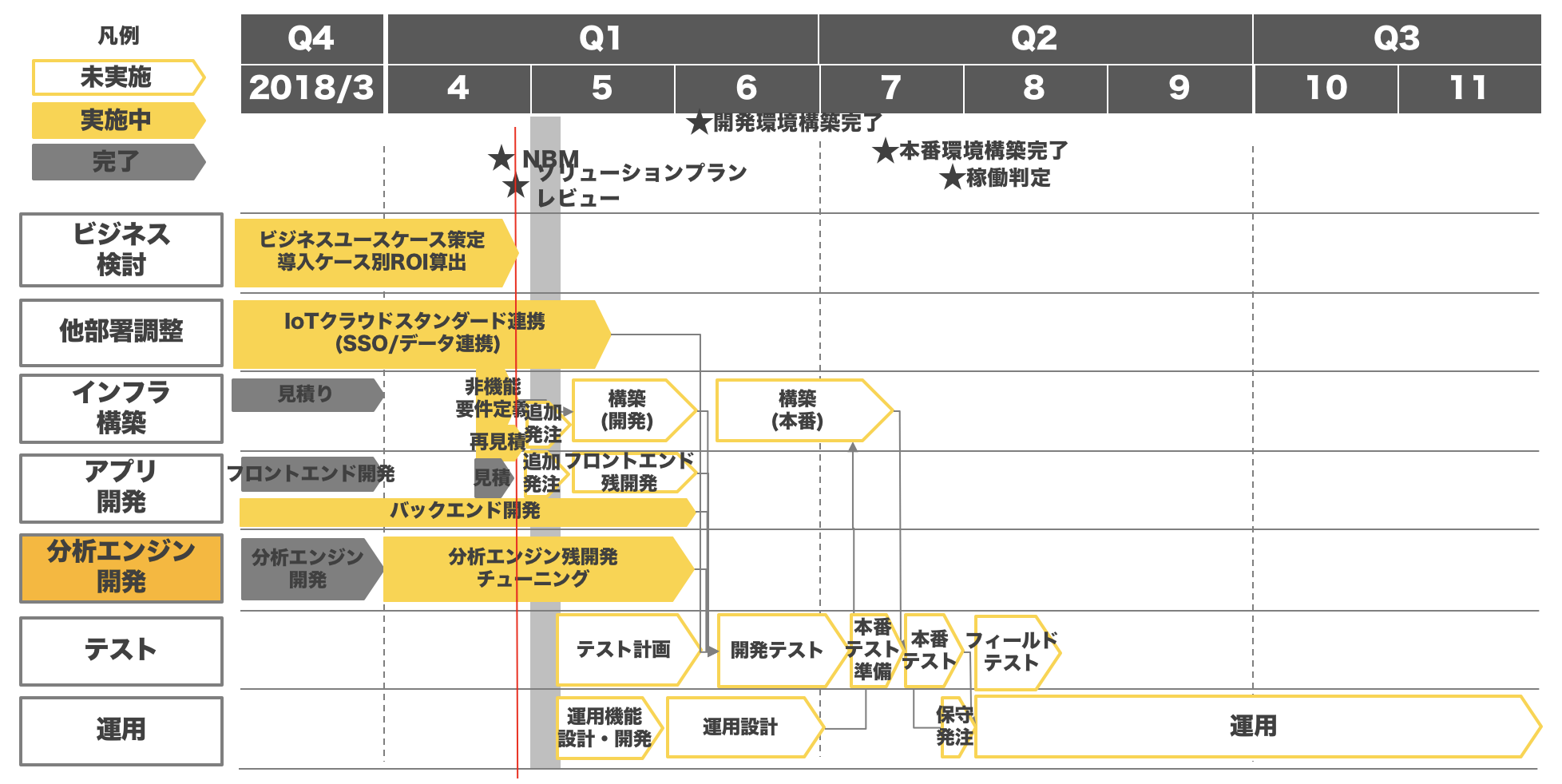
従来のようなウォーターフォールの中でも【テスト計画→開発テスト→本番テスト準備→本番テスト→フィールドテスト】と小さなステップで効果検証を繰り返します。
この検証において機械学習モデルを評価する指標はいくつもあります。ソフトウェア開発における試験に相当しますが、想定するターゲットに応じて適切に指標を選択することが必要です。分析技術と適用ドメインに関する双方の知識が求められます。
| 指標 | 説明 | 適合するシーン |
| Accuracy | 正解率のこと。予測結果全体と、答えがどれぐらい一致しているかを判断する指標
一般的にはAccuracy高いほど良いモデルであるということができるが、不均衡データでの利用には注意が必要 |
正例と負例の数が均衡している場合 |
| Recall | 正例をなるべくとり逃さずカバーできることを重要視した評価指標 | 病気の発見など、正例を逃してはならない業務要件の場合 |
| Precision | 分類結果がなるべく正しいことを重要視した評価指標 | 迷惑メールフィルタなど、間違って正例としてしまい重要な情報の破棄が許されない場合 |
| IOU | 不均衡データで正例が少ない時に、少数の正例をよく分類できていることを評価できる指標 | 異常検知など、正例が非常に少なく、不均衡データを対象とする場合 |
このように指標を設けても、テストにおいて十分な精度が出ない時の原因は2つ考えられます。しかし、どっちが 原因なのか判別するのは至難の技です。
- 十分な品質・量のデータがない
- モデル選択、チューニングが不十分
一般的には、上記のどちらかが理由です。
データが原因であるケースでは、PoC実施時に利用した学習データが、その後実務に適用したときに発生したデータの分布を網羅していない場合、実適用時に外挿問題が発生して、一般に外挿に弱いモデルは十分な精度がでません。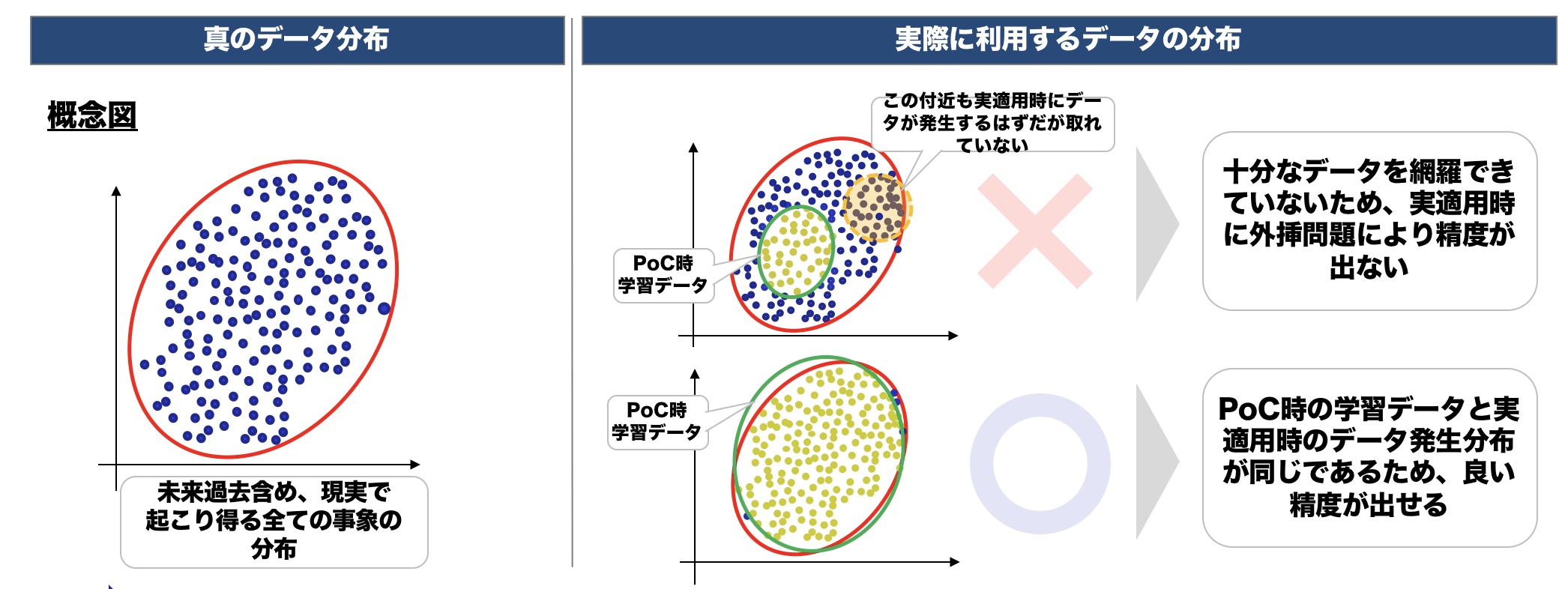
これを避けるために実務についての理解を深めることや、データの収集と確認をしっかりと行っていくことが大事です。そうすれば、網羅性を十分にもったデータを集めることができ、高精度のモデル構築が可能になります。
また開発リソースの管理として、従来のようなソースコードバージョン管理、開発環境管理、継続的インテグレーションに加えて、データバージョン管理や予測精度の結果管理が必要です。
機械学習のモデルはよく生物に例えられることも多いですが、更新し続けなければ精度を保つことはできません。その点でデータのバーションを管理した上で予測精度を追っていくことが大切になります。
また、開発環境の管理とその展開はとても重要なテーマです、分析結果の再現性を保つために、ライブラリのバージョンの組み合わせを維持することがとても重要で、そのひとつの手段としてDockerなどの仮想環境などを活用することも大切です。
機械学習は間違える前提で設計する
指標をきちんと評価しても、精度が100%になるケースはほとんどありません。そのため、モデルがもしも誤ってしまった時の対応をきちんと定義しておくことが大切です。機械学習は、バグではありませんが本質的に間違いを伴います。この認識が必要です、
また、間違ってしまったときにどのように対処するのか、リカバリーの方法を含めたシステム設計をしなくてはいけません。誤ることが前提なので、完全に機械学習モデルに依存するのではなく、人間の判断の介入の余地を与えることも大切です。
機械学習モデルは、既存の業務を超えることを評価で確認した上で、業務に適用します。現場に導入したとして、しっかり運用が周るのか、事前に入念に検討しておくことが大切です。
機械学習工学研究会の今後の活動
機械学習工学研究会は今後、定期的にイベントを開催していきます。
2018年度 人工知能学会全国大会
企画セッションKS-1
『機械学習工学とは − 機械学習システムを創り上げるための工学的課題 −』
| 日程 | 2018年6月8日(金)12:00-13:40 |
| 開催場所・指定宿泊先 | 鹿児島県鹿児島市(城山観光ホテル) |
| プログラム | 【講演】 タイトル未定 12:00-12:40 榊原彰(日本マイクロソフト)【パネル】 『機械学習システムを創り上げるための工学的課題』 12:40-13:40 石川冬樹(国立情報学研究所) 丸山宏(Preferred Networks) 太田満久(ブレインパッド) 山田敦(日本IBM) 榊原彰(日本マイクロソフト) |
第1回機械学習工学ワークショップ(MLSE2018)
| 日程 | 2018年7月1日(日)~2日(月) |
| 開催場所・指定宿泊先 | マホロバマインズ三浦・本館 〒238-0101 神奈川県三浦市南下浦町上宮田3231 https://www.maholova-minds.com/ |
| 主催 | 日本ソフトウェア科学会 機械学習工学研究会 |
| URL | https://mlxse.connpass.com/event/83360/ |
| 問い合わせ | mlse2018sws@wsf.jp |

おざけん
■AI専門メディア AINOW編集長 ■カメラマン ■Twitterでも発信しています。@ozaken_AI ■AINOWのTwitterもぜひ! @ainow_AI ┃
AIが人間と共存していく社会を作りたい。活用の視点でAIの情報を発信します。




























機械学習は夢の技術と思われがちですが、100%の精度が必ず保証されるわけではありません。例えば医療のようにその判断の重要性が極めて高い場合など、2%のご認識でも致命的です。
この前提が抜けると、機械学習の信頼度が落ち、現場で使われないという問題が発生してしまいます。
必ず失敗することがあるという前提のもとで、この記事にあるようなステップを参考にしてほしいです。
その上で、人間の判断とハイブリッドにするなど、機械学習がすべきことと人間がすべきことの棲み分けが今後大事になってくるでしょう。