
最終更新日:

GoogleやMicrosoft、Adobeといったアメリカを代表するIT企業・AI企業が、MITと協力して、「画像」や音のない「動画」と、「音響」の「対応関係」を学習させたディープ・ラーニングモデルの研究開発を進めています。
これらのモデルは、音のない「画像」や(音声が記録されていない)「動画」ビデオ・データを(モデルに)入力すると、撮影対象の空間で流れていたと推定される音響・音声が、出力値として出てくるというモデルです。
このような、「画像」と「音響」の「対応関係」を学習させたモデルは、例えば、音声鮮明化のためのモデルとして、研究が行われているようです。
これは、周囲の雑音にさえぎられているなどの理由で、明瞭に聞き取ることのできない音声や人の声を、その音源となった「物の動き」や人の「口元の動き」を捉えた「動画」を参照することで、聞き取りやすいクリアな音声に変換するというものです。
この他にも、「画像」と「音響」の「対応関係」を学習させたモデルは、透明なガラスの壁面(窓など)を通じて内部を視覚的に捉えることのできる建物の居室内の「音」を推定し、再現するという用途でも研究が行われています。
これは、壁面ガラスが微細に振動する様子を収めた「動画」を解析することで、ガラスの微細な振動を生じさせた(建物内の)音波の周波数の時系列変化を逆推定するという仕組みを研究したモデルです。このモデルもまた、「ガラスの振動パターン」と「その振動をもたらす音響の時系列変動パターン」との間の「対応関係」を、学習したモデルです。
このような「画像」・「音のない動画」と「音響」・「音声」の「対応関係」を、ディープ・ラーニングモデルに学習させる研究に、Googleグループ(Google Research、Google DeepMind)やMicrosoft、Adobeは、MIT(マサチューセッツ工科大学)と共同して取り組んでいるようです。
各社がMITと共同で執筆した論文が複数、公開されていることから、その一旦を窺い知ることができます。論文に記されたモデルは、いずれもディープ・ラーニングを用いたモデルです。
この連載記事は、まず、GoogleやMicrosoftやAdobeが、MITと共同で行った研究の成果をとりまとめたこれらの公開論文を紹介します。
そして、これらの研究の結果、得られた”「無音の画像・動画」から「音響・音声」を推定するモデル”が、今後、GoogleやMicrosoft, Adobeの商用サービスに、どのような形で組み込まれて登場してくるのか、各社のビジネス戦略について、少し考えてみたいと思います。
なお、Gigazine(和訳版)の2018年07月09日付けの記事によると、Google、MicrosoftやAdobeが共同研究を行ったMITは、「ムービーに映っている楽器をピクセルレベルで識別したり、その楽器に関連付けられた音を抽出したりすることができ」(Gigazine記事)る「PixelPlayer」というモデルを論文で発表しています。
MITの研究室のページはこちらです。また、「PixelPlayer」モデルを使っている様子は、YouTubeで動画として公開されています。
この研究を行ったMITのコンピューター科学人工知能研究所(CSAIL:Computer Science and Artificial Intelligence Laboratory)を始め、MITの技術の動向について、今後、注目が集まります。
目次
- Google・Microsoft : ありえる技術の商用化シナリオの例
- 建物の外から直接、屋内の音声を推定する技術
- 植物の葉やポテトチップスの袋の「微細な揺れ」を感知する画像解析技術
- 屋外からの屋内音響推定技術としては、レーザーを用いる方法が知られていた
- レーザー盗聴では、カーテン等で遮られて屋内を視認できない場合も有効か
- (透明でない)壁越しに、屋内の物体の動きを取らせる技術も公開済み
- MicrosoftとAdobeだけでなく、Googleも複数の研究論文を公開済み
- 画像から物体の材質属性を推定する研究も進んでいる
- 米国大手各社の研究目的はなにか? ~ 今後の商用展開戦略を探る
- 物体の振動画像からの音響推定だけではない: 「画像シーン」から「シーンに対応した音響」を推定・生成する技術も。
- 音響のクラス分類の精度を、学習済みの「音響-画像対応」モデルを用いて引き上げる技術
- DeepMindは、少し毛色の異なる研究論文をとりまとめている
- 画像を用いて音響データの「鮮明化」処理の精度を上げる研究
- 「画像」と「音声」の対応関係を学習する技術:特徴ベクトル空間モデル
- 「画像」と「音響」の「対応関係」を学習したモデルは、GoogleやMicrosoftのサービスに、今後どう活用されるのか
- 2次元画像から、3次元画像を推定する技術
- 画像から「音」・「素材の材質」・「3次元立画像」を推定できる技術は、今後、商用サービスにどう組み込まれていくのか
Google・Microsoft : ありえる技術の商用化シナリオの例
“「無音の画像・動画」から「音響・音声」を推定するモデル”の商用化のシナリオについては、次回以降の記事であれこれと仮説を提案したいと思いますが、「アイデア」(GoogleやMicrosoftが公式に発表した商用化シナリオではなく、新開が勝手に「ありえる例」として「予想」したもの)としては、例えば次の3つがあります。
商用シナリオ(1)
まず。可能性としてありうるのは、GoogleMapなどの地図アプリ上で、レストランをピンで立てて表示する際に、”ジャズ音楽が流れているイタリアン・レストラン”という詳細情報を追加するという「アイデア」です。
Google Street View撮影車が、レストランの外観の景観を撮影するときに、先述のモデルを使って、ガラス越しに「このレストランは、この時間帯は、客席ホールにジャズ・ミュージックを流している」などの情報を取得して、地図上で表示させることができます。
得られたデータは、Google Street View上で、360°視点を動かしているときに、正面にレストランを捉えたときに、「ジャズ・ミュージック」のアイコンをAR(拡張現実)的なUXで、付加情報として表示させることもできると思います。
Microsoftも、レストランのオススメ店舗をレコメンドする際に、”ジャズ音楽が流れているイタリアン・レストラン”といった検索カテゴリを、システム内で生成することができると思います。
商用シナリオ(2)
他の例としては、インテリジェント防犯カメラへの活用が考えられます。
AIを搭載したインテリジェントな防犯カメラや監視カメラというと、しゃがみこんだり、不審な動きをしている人物を、(画像解析によって、姿勢や体の動き方を「正常」・「不審」に分類・判別することで)検知する機能を組み込んだものが知られています。
このカメラに、会話内容が怪しげな人(「爆弾」とか、「殺せ・殺(や)れ」、などといった指定キーワードを含む発話をしている人など)を検知する機能を追加することが、考えられます。
ここでも、集音マイクで捉えたぼやけた肉声を、口元の動きを捉えた動画データを頼りに鮮明化するという、すでに述べた「画像パターン」と「音声パターン」の対応モデルが活躍します。
商用シナリオ(3)
マイクで拾った発話音声データを、口元や頬の動きの画像データを参照することで、クリアに鮮明化するというこの技術は、ATMなどの遠隔電話お問い合わせサービスで、不明瞭なお客様の声(の音声データ)を、お客様を撮影しているビデオカメラの画像を参照することで鮮明化するというニーズにも、活用することができそうです。
キャッシュレス時代の到来により、ATM自体が不要になるのではないかということが取り沙汰されている中で、ATMの事例は、すでに時代遅れかもしれませんが、あらゆる遠隔音声サービスに、こうしたニーズは存在していると思われます。
以上、先取り的に、画像から音声を推定する技術の商用実用化のイメージを、3例ほど、思い描いてみました。
それでは、次の節から、GoogleやMicrosoft,やAdobeによる技術の研究開発の動きを、ひとつひとつ追いかけて見ていきます。
建物の外から直接、屋内の音声を推定する技術
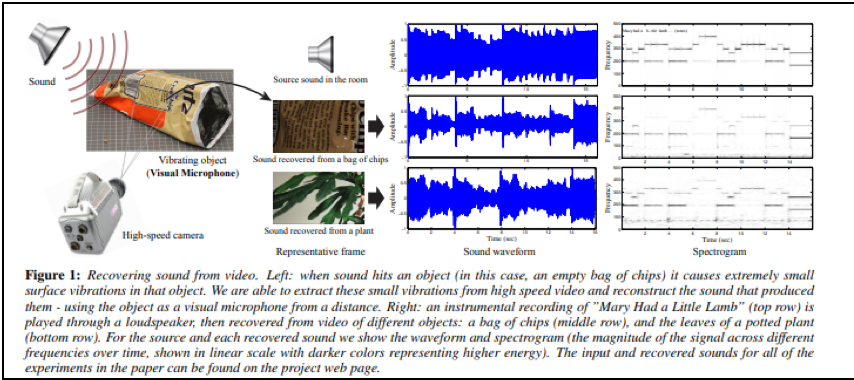
屋外に設置したビデオカメラから、屋内の観葉植物の葉やポテトチップスの袋の動画を一定時間、透明なガラス越しに撮影する。そして、撮影した動画に画像解析を施して、動画中の葉っぱや袋の微細な揺れを分析することで、屋内に生じていた音響の時系列変化を推定し、室内で聞こえていたはずの音声を再現してみせる。
2014年に、MITがMicrosoftとAdobeの2社と共同で、こうしたチャレンジに取り組んだ結果をまとめた学術論文が公開されました。
この論文は、Engadget誌(英語記事・和訳版記事の両方)や一般の報道でも取り上げられました。
この研究は、屋内に盗聴器を設置しないでも、屋外から、(透明な)ガラス越しを通して、屋内にある観葉植物の葉やポテトチップスの袋といった、空気を伝わる音波に押し引きされて微細に振動する物体させ撮影することができれば、屋内の音声や音響状況を推定できるようになる技術を確立させようとするものです。
- MIT News(2014年8月4日付け)Extracting audio from visual information
ガラス越しに捉えた観葉植物の葉の動きの動画から、室内に生じていた音声を推定(再現)した様子は、以下のYouTube動画に収められています。
- [You Tube] Abe Davis’s Research (2014/08/04に公開)The Visual Microphone: Passive Recovery of Sound from Video
以下、上記のYouTube動画から何点か切り取ったカットを掲載します。
以下のように、屋内にある植物の葉の微細な振動を取得することで、葉を揺らす原因である屋内の音響状態の時系列変化(音声信号)を逆推定します。
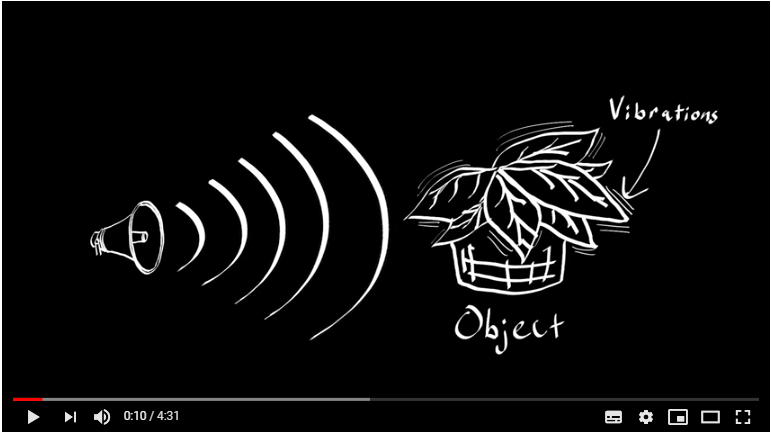
以下、屋外に設置したビデオカメラから、建物のガラス越しに、屋内にある植物の葉をビデオ撮影します。
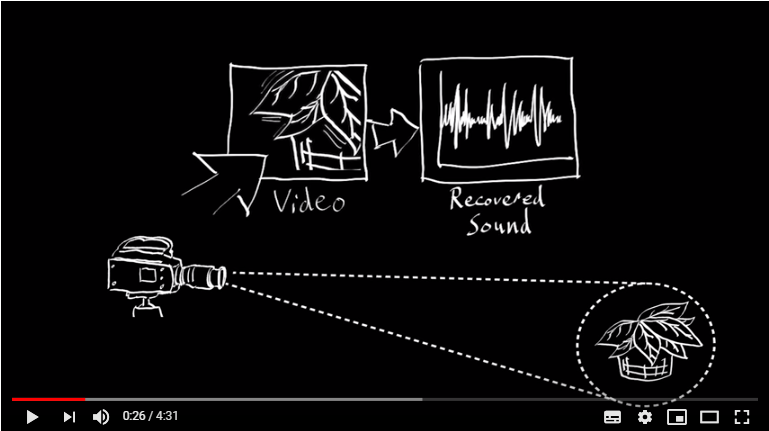
撮影された動画に映っている葉をズームアップします。 葉の細かな振動から、(振動の原因となった)葉の周囲の音響状態の時系列変化を推定します。
葉の細かな振動から、(振動の原因となった)葉の周囲の音響状態の時系列変化を推定します。
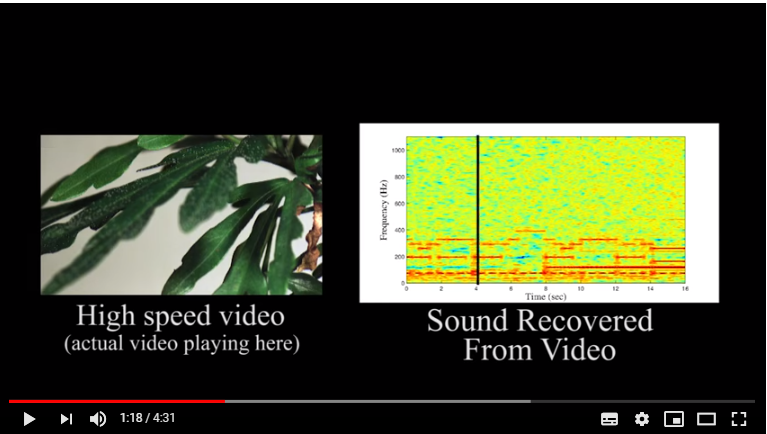
以下は、ガラス腰に室内のポテトチップスの袋を撮影し、画像に映る袋の振動の様子から、室内音を再現した様子です。

以下は、ガラス腰に室内のポテトチップスの袋を撮影し、画像に映る袋の振動の様子から、室内音を再現した様子です。

今度は、スマートフォンの振動(をとらえた動画)から、スマートフォン内のスピーカーから出る音声を再現した様子です。
(以上、YouTube動画からの転載おわり)
以上のYouTube動画に収められた試みの詳細は、以下の論文で報告されています。
・ [論文(MITウェブページ掲載版)] Abe Davis (MIT CSAIL)ほか, The Visual Microphone: Passive Recovery of Sound from Video,
本連載では、上記の論文を含む一連の論文の内容を解説していくことで、これらの研究に取り組んでいるGoogleやMicrosoftなどの企業が、今後、蓄積した技術を自社のサービスや製品にどう組み込み、どう商用展開していくのかについて仮説を提示していきます。
初回記事の今回は、論文の詳細についての解説は後回しにして、いくつか論文に採録された図表を眺めていく飲みにとどめたいと思います。
(以下、論部から転載)
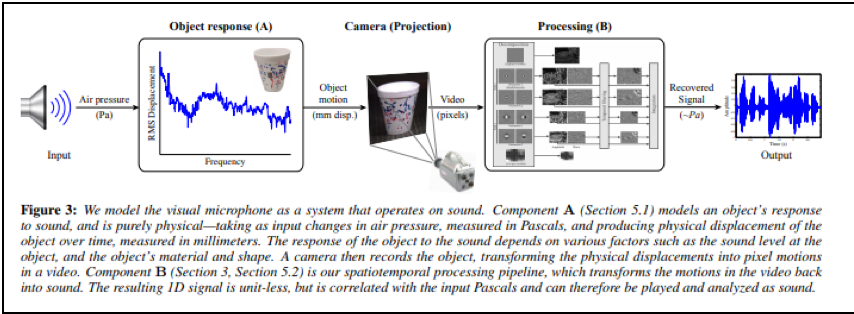

(転載終わり)
植物の葉やポテトチップスの袋の「微細な揺れ」を感知する画像解析技術
植物の葉やポテトチップスの袋の「微細な揺れ」を感知することを可能とする画像解析技術については、上記の研究が行われた(2014年の)2年前に発表された以下の論文で解説されています。
- MIT News(2012年6月22日付け)Researchers amplify variations in video, making the invisible visible
上記のMIT Newsの記事の中では、この研究によって、たとえば、画像に映りこんだ人間の肌の血管の振動を解析することで、人間の心拍数の時系列変化を推定することが可能になることが、述べられています。
なお、この、画像から脈拍を推定する技術については、MIT Technology Review誌(邦訳版記事)のなかで、ダートマス大学の専門家のコメントが掲載されています。
- MIT Technology Review 「テクノロジーが変える『現実』の概念 – 私たちは何を信じるべきか」
この分野で世界トップクラスの専門家、ハニー・ファリド教授(ダートマス大学)は、あるシーンが立体的にどう復元されるのかを示し、身体的に不自然な点を発見した。またファリド教授は、人間の脈拍数など、映像のピクセル強度のわずかな変化を用いて、本物の人間とコンピューターが作った人間との違いを見つけられることも証明した。最近、以前ファリド教授の研究室にいた学生(現ニューヨーク州立大学オールバニ校教授)が、AIによって偽造された顔の正体を不規則な目のまばたきによって暴露できることを明らかにした。
なお、関連する論文としては、以下があります。
画像から人間の脈拍を推定する技術も向上している
- 西井 巧 「近赤外カメラを用いた画像脈波による非接触心拍推定」, 愛知県立大学情報科学部 平成 29 年度 卒業論文要旨
- 渡邊 汐・影山 芳之 「顔画像解析による色情報とストレスとの関連性について」, 東海大学紀要工学部 Vol.57,No1,2017,pp.51-57
- 小原 一誠ほか 「映像からの脈波情報抽出」
- [プレスリリース] 株式会社富士通研究所(2013年3月18日付け)「顔の画像からリアルタイムに脈拍を計測する技術を開発」
- 日経BP 松元 則雄(2017/05/18) 「スポーツ×テクノロジー最前線 人に触れずに心拍数を計測、パナソニックが動画解析技術」
- IMACEL ACADEMY (2016年9月14日 更新)「顔写真から心拍数が計測出来る『Pace Sync』」
「読唇術」で画像から、会話の内容を推定するAIも、人間を凌駕する精度レベルを達成している
なお、唇の動きを捉えた画像から、会話の内容を推定する(音声は推定しないが、音声の内容は推定可能)技術としては、AIによる「読唇術」の研究があります。少し脱線しますが、以下を取り上げておきます。
- 「グーグルのDeepMind、読唇術で人間の専門家に勝つ」
- TABI LABO (2016年11月23日付け)「人工知能が『読唇術』で会話をテキスト化。正解率は93.4%。」
- MIT Technology Review 「中国第2位の検索エンジンCEO、グーグルに「OEM提供」を提案」
MITテクノロジーレビューが取材をする少し前に、王CEOは北京の清華大学の学生たちに向けて講演をした。ソゴウは最近、清華大学に新たに開設されたAI研究所に資金を提供したのだ。講演では、最先端の機械学習を含むさまざまなプロジェクトが話題にのぼった。その1つに、読唇術で音声の自動文字起こしを支援するプロジェクトがある。スピーチやプレゼンを自動でリアルタイム翻訳するソフトウェアを提供している企業は中国に何社かあるが、ソゴウはそのうちの1社だ。
屋外からの屋内音響推定技術としては、レーザーを用いる方法が知られていた
話を戻します。
屋外から、ガラス越しに屋内の音響状態を推定・再現しようとする技術としては、これまでは、建物のガラス窓にレーザー光を照射する方法が、広く一般にも知られてきました。
レーザー光線を用いるやり方は、ガラスから跳ね返る光を解析することで、ガラスの微細な振動の動きが、時間とともにどのように変化していったのかをまず感知し、その「ガラスの振動」データが得られるような「室内の音響波長の変化」はどのようなものかを、計算によって絞り込み、推定することで、室内の肉声や物音を時系列で再現するという段階を踏むものです。(Googleで「レーザー盗聴」と検索すると、盗聴防止機器を販売する業者や、盗聴検知を請け負う探偵事務所の日本語ウェブサイトが、検索結果に、たくさんヒットします)
レーザー盗聴では、カーテン等で遮られて屋内を視認できない場合も有効か
レーザー盗聴(laser microphone)も、すでに取り上げた動画に基づくアプローチ(動画に映り込んだ物体の微細な振動から、その物体の周囲の空間の音響状況を再現しようと試みるもの)も、一般に用いることができるのは、対称とする建物の壁面にガラス素材を用いた部分が存在する場合に限定されると考えられます。
動画に基づくアプローチは、屋内の物体(音で振動する植物の葉や袋や服の生地など)が、無色透明のガラス越しに、屋外から視認できなければならないからです。
なお、ビデオカメラと建物のガラス壁面との位置関係については、原理的に光は直進するので、直線上に物体が見えなければなりません。しかし、ガラス壁面とビデオカメラとの間に、反射鏡をいくつか設置して、レーザー光を任意の角度に反射させることで、対称とする建物のガラス壁面の鉛直垂直方向に、直接ビデオカメラ機材を設置できない場合でも、この方法は利用可能となるかもしれません。
レーザー盗聴(laser microphone)も、ウェブ上の解説資料の多くは、ガラスにレーザーを投射し、ガラスの振動を感知するもの、と定義していています。(ウェブ上の)一部の資料は、カーテンにレーザーを照射し、カーテンの微細な振動を感知することで、カーテンの向こう側の屋内の音響を再現しうる、と述べているものも存在します。
もし、このような記述が事実だとするならば、カーテンは、透過性の高いレースのカーテンなどを除いて、多くの場合、透明ではないため、カーテンにさえぎられて屋内を視認することができないケースであっても、レーザー盗聴技術で屋内の音響を推定できる可能性は存在するのかもしれません。
(透明でない)壁越しに、屋内の物体の動きを取らせる技術も公開済み
なお、「音響」ではなく、屋内にいる人や物体の位置と、位置の変化(動き)を(透明ではない)壁越しに推定する技術についても、MITから論文が公開されており、MIT Technology Review誌やWired誌、Techable誌、Gizmo誌といった著名なオンライン・テクノロジー誌の記事として公(おおやけ)にされています。
- [論文] Through-Wall Human Pose Estimation Using Radio Signals
- [MIT Technology Review 邦訳版] 壁の向こうの人の動きを電波で「透視」、MITチーム
- [Wired 邦訳版] (2018年6月22日付け) 人の動きを壁越しに“透視”する技術、その秘密は「電波」にあり
- [Techable] (2018年6月15日付) デジタルの力で壁を透視!MIT CSAILが開発した新技術
- [Gizmo誌] (2018年6月19日付け) MITが壁を透視する技術を開発。これは完全に近未来SFの世界だ…
以下、上記の論文から転載した図版をみてわかるように、壁越しに屋内の物体の動きを推定した(推定)画像によって、人物の骨格の位置を確認することができるため、人物や動物の姿勢を理解することができます。これにより、屋内の人物が何を行っているのかを、身体の姿勢からごく粗く推し量ることが可能になる可能性があります。
しかし、服の色や表情の様子までを捉えるまでには、至っていないようです。
(以下、上記論文から転載)

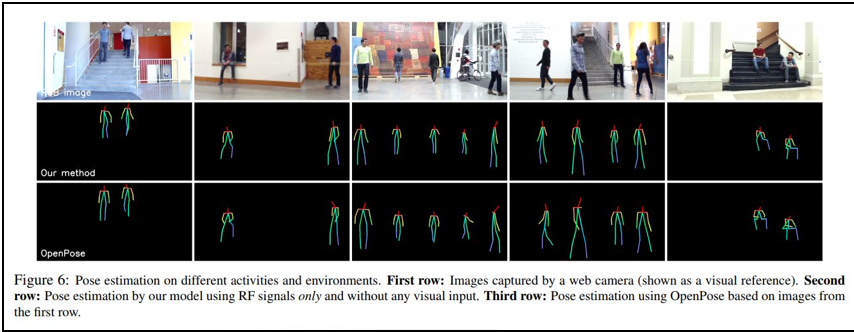
深層ニューラル・ネットワークモデルのひとつである「Encoder-Decoderモデル」を用いているようです。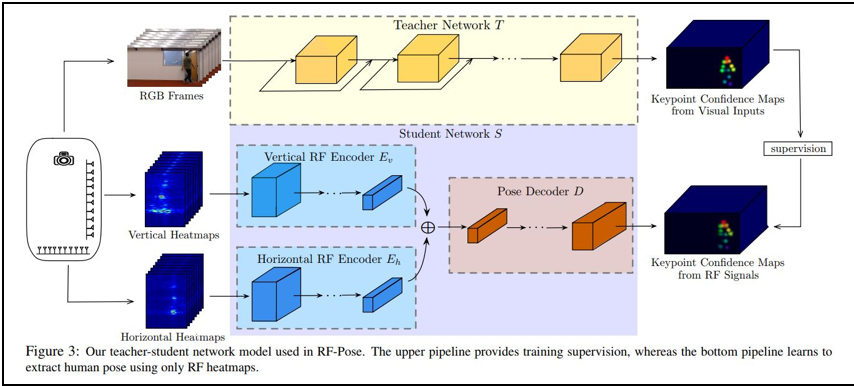
(以上、転載終り)
今後、レーザー盗聴技術が、カーテンよりも堅い(普通の建物の)壁の微細な振動を感知することで、室内の音響状況を推定できるようになった場合、(ガラス面を持たない)壁でさえぎられているために、屋内を直接視認することができない建物内の空間に関しても、屋内空間の「音」と「物の移動」の双方を、壁の外から推定できるようになるのかもしれません。
MicrosoftとAdobeだけでなく、Googleも複数の研究論文を公開済み
2014年のMITほかの研究は、これまで知られていた、レーザーを当てる方法ではなく、室内におかれた物体の時系列動画を撮影するアプローチを提案した点が、新しい点でした。
このアプローチについて、さらに調べてみたところ、Google Researchも、MITの別の研究者グループと組んで、この分野で複数の研究論文を執筆・公開していることがあらたに分かりました。
Google Researchは、(音のない)動画から音声を推定した上で、さらに、
推定した音の音色(ねいろ)から、画像中の物体の材質が持つ物理的な属性についても、推定することに取り組んでいます。
以下が、その論文です。
- Andrew Owens (MIT)ほか(2016), Visually Indicated Sounds
論文の内容については次回以降の記事で解説していきますので、この論文も、まずは図表のみ転載します。
(以下、同論文から転載)
まず、音のない動画から、音響の時系列変化を推定します。
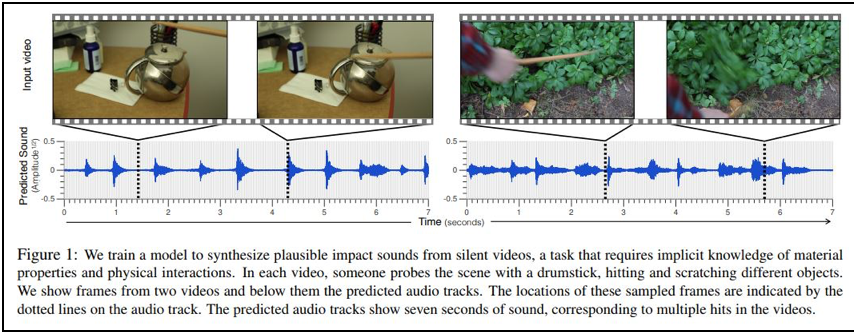
次に、推定した音響の時系列変化から、物体の材質がもつ属性を推定します。


なお、この論文は、Abstract(概要要約)の文章では、リカレント・ニューラル・ネットワークモデルを用いていると述べていますが、以下をみると、CNNとLSTMを用いています。

画像から物体の材質属性を推定する研究も進んでいる
なお、画像から物体の材質属性を 推定することに特化した研究としては、以
推定することに特化した研究としては、以
下があります。
以下の論文は、石ころや岩や土や沼地など、地形の材質状況を地形の画像データから推定する課題に取り組んだ論文です。用途としては、地形を移動するロボットで役立てることを念頭においているようです。
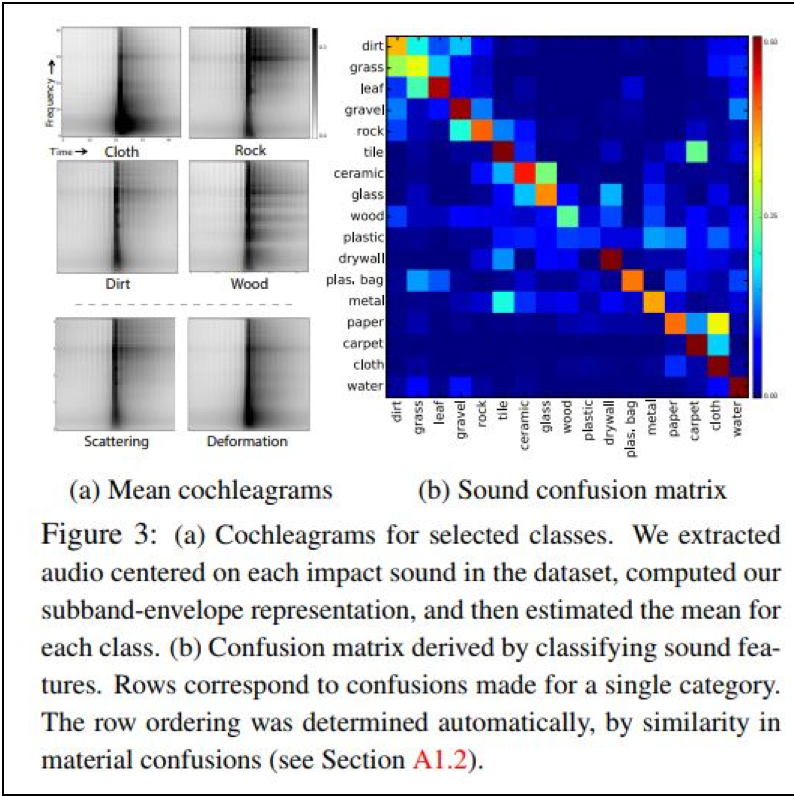
・ [論文] Deep Texture Manifold for Ground Terrain Recognition
また、次の論文は、人間の着ている洋服の各部位の素材や、居室内のソファーや机や壁などの素材を推定する課題に取り組んでいます。
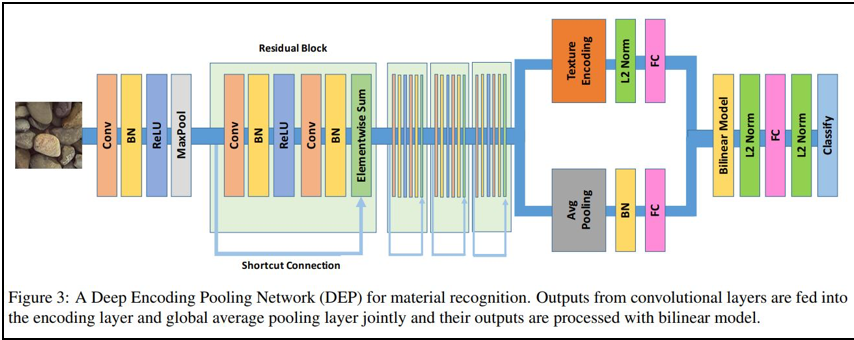
・ [論文] Recognizing Material Properties from Images
(以下、同論文から転載)




このモデルも、深層ニューラル・ネットワークを用いているようです。
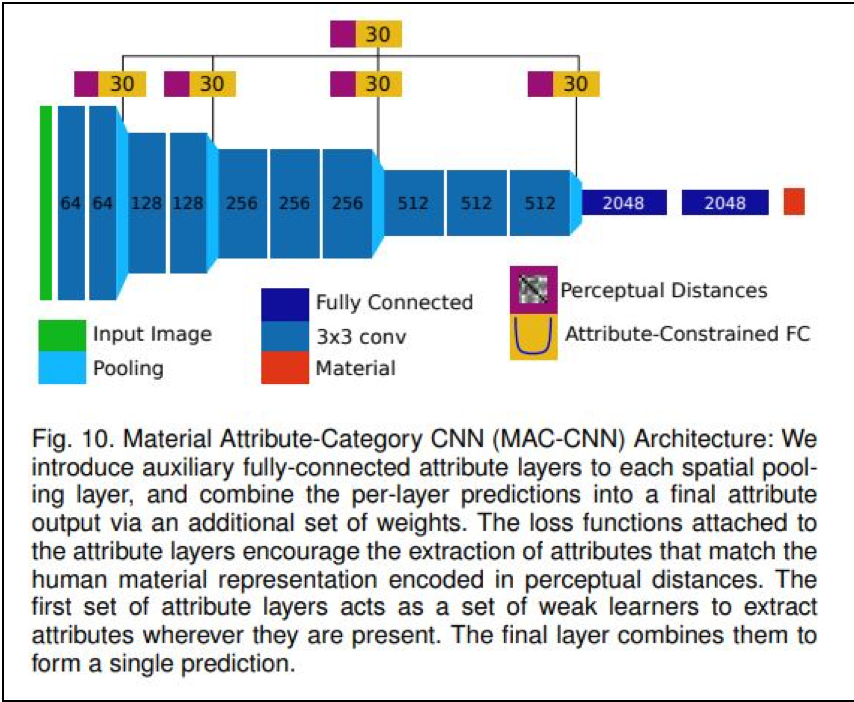
材質の属性の遠近距離で分類された各材質の関係図です。
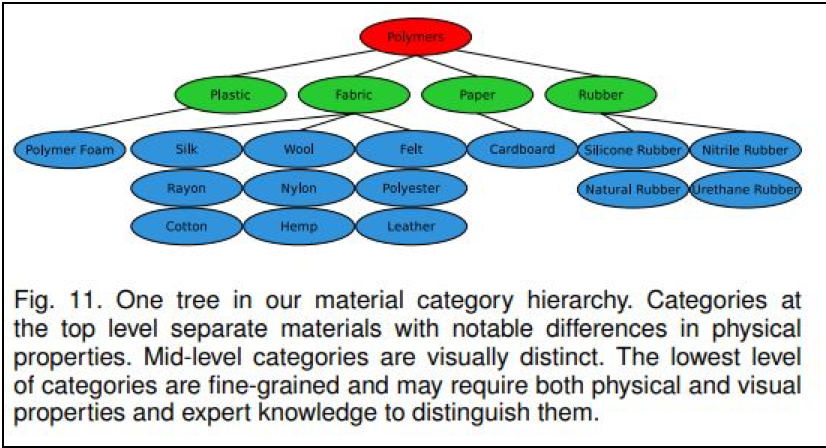
こうした研究は、例えば、以下の商用サービスや行政サービスでの活用が期待できそうです。
- 自動運転車やドローンが、衝突が避けられない場合に衝撃が最小化できる(人や動物でない)周囲の物体を探す。
- 救急隊員が入り込めない入り組んだ場所や瓦礫の下に潜り込んだ(東京消防中の特別レスキュー隊が常備しているような)救助ロボが、対象者の周囲に、どのような材質の物体がどのような配置で存在しているのかを確認する。
- ロボットが、物を掴んだり操作したりする場合に、材質の硬さや弾力性を認識して、力の入れ方を最適化する。
なお、日本の大学からは、以下の研究成果が公開されています。
- [電気通信大学の論文] DCNN特徴を用いたWebからの質感画像の収集と分析
- [千葉大学のスライド] 画像情報に基づく物体の質感解析
また、物体を触ったり、投げたりしていじっているうち、物体の重さや硬さ、弾力度合いや摩擦度合いなどをじょじょに学んでいくモデルは、Google DeepMind社が研究に取り組んでおり、以下の論文が出ています。こちらも、すでにテクノロジー・メディアによって取り上げられています。
- [Gigazine解説記事] Google「DeepMind」の人工知能は赤ん坊のように「触って覚える・判別する」能力を学習したとの発表
- [解説記事] 【グーグル】「DeepMind」の人工知能(AI)が触感を獲得
- [論文] “Learning to perform physics ezperiments via deep reinforcement learning”
米国大手各社の研究目的はなにか? ~ 今後の商用展開戦略を探る
Microsoft ResearchやAdobe Researchだけでなく、Google Researchもこの手の研究に取り組んでいる目的は、一体何でしょうか。今後、これらのアメリカを代表するテクノロジー企業が、こうした技術を、検索エンジンやSNSサービス、パーソナル・アシスタント・アプリや、Intelligent IoTデバイスといった各種の自社サービスに、どのように組み込んで商用事業化を図っていくのか、いまのうちから頭の体操をしていく必要がありそうです。
物体の振動画像からの音響推定だけではない: 「画像シーン」から「シーンに対応した音響」を推定・生成する技術も。
画像から音響状況を推定する研究について、調査を進めていくと、屋外から屋内の音響状態を推定するために画像解析技術を用いるというテーマだけでなく、個々の「画像シーン」が、どのような「音響」と「対応(”to correspond”)付けられる」のかを深層ニューラル・ネットワークなどで学習させる研究も、MITやGoogle DeepMindによって行われていることが見えてきました。
1つだけ、論文を先取りして紹介すると、MITからは、以下の論文が公開されています。
- Yusuf Aytarほか (2016) SoundNet: Learning Sound Representations from Unlabeled Video
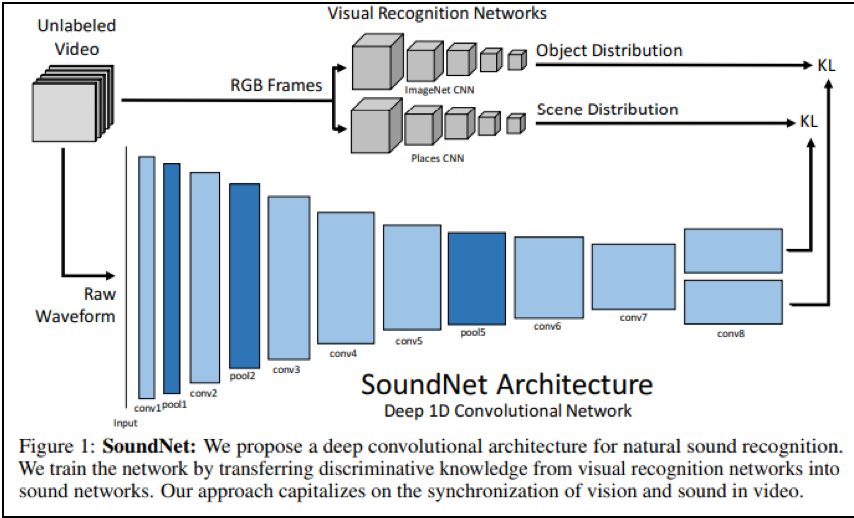
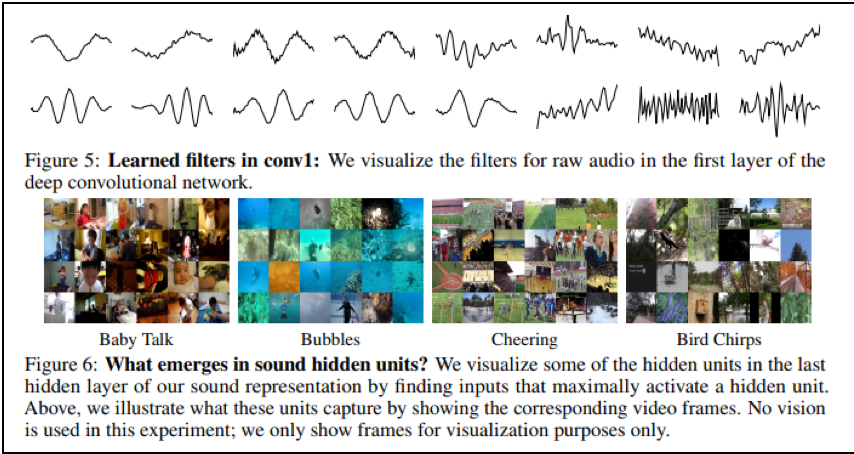

音響のクラス分類の精度を、学習済みの「音響-画像対応」モデルを用いて引き上げる技術
また、Google傘下のDeepMInd社は、深層ニューラル・ネットワークを用いて、音響データと画像データの2つのデータの間の対応関係(”correspondence”)を学習させたモデルを用いて、音響データのクラス分類精度を高める研究を行っています。
その研究では、音響データに加えて、(その音響が生じた様子を撮影した)画像データを併せて用いることで、音響のカテゴリ分類の精度が、(音響データだけを用いて音響データをクラス分類したときに比べて)改善されたという結果が得られていると、論文では報告されています。
DeepMindは、少し毛色の異なる研究論文をとりまとめている
- Relja Arandjelovicほか (2017) Look, Listen and Learn
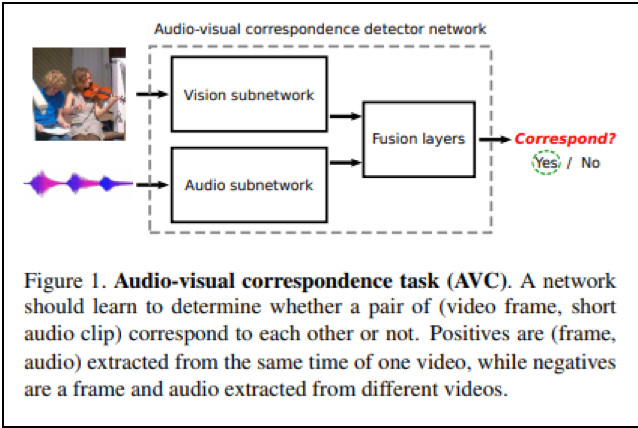
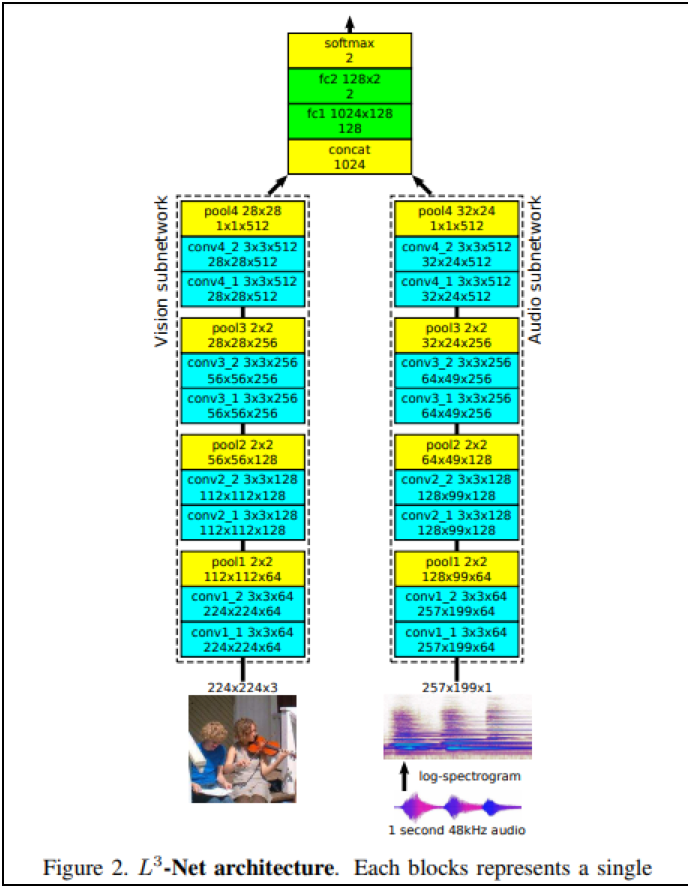
画像を用いて音響データの「鮮明化」処理の精度を上げる研究
また、以下のエルサレム・ヘブライ大学の研究者は、周囲の雑音によって不鮮明になった人の歌声や声を、人の口の動きや表情の様子を捉えた画像データを用いて、鮮明化させる研究に取り組んでいます。
・Aviv Gabbayほか (2017) Seeing Through Noise: Speaker Separation and Enhancement using Visually-derived Speech
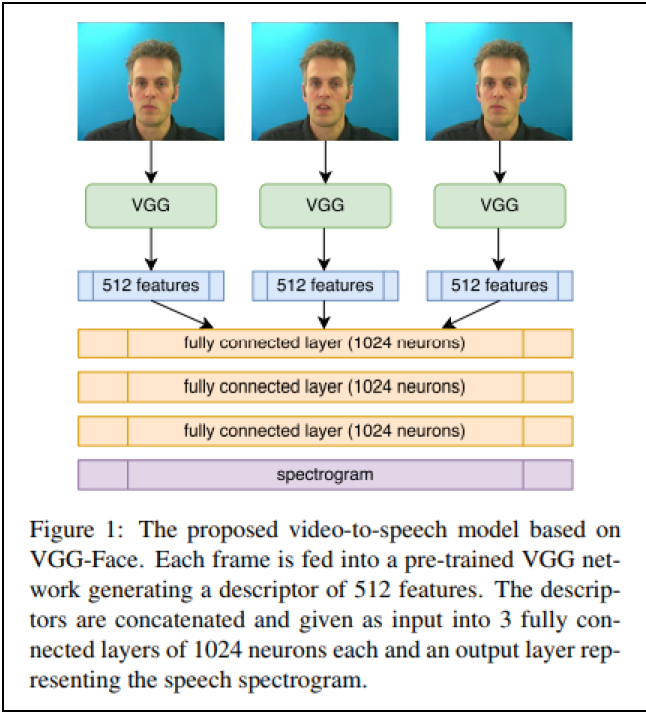
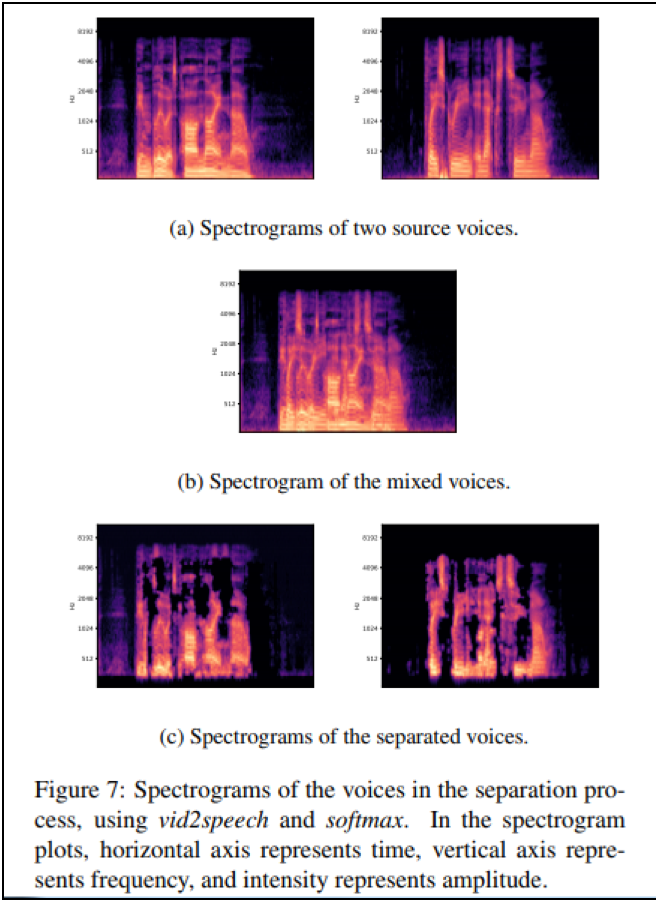
「画像」と「音声」の対応関係を学習する技術:特徴ベクトル空間モデル
以上、見てきた事例は、「画像」と「音声」の対応関係を大量のデータセットから統計論的学習モデルの1つとしての深層ニューラル・ネットワークモデルを用いて学習させることで、新たに入力された「画像」から、その「画像」に対応すべき「音声」を推定結果として出力したり、「音声」分類を行うにあたり、(「音声」データだけを頼りにするのではなく)それと紐づく「画像」データを参考情報として用いることで、分類正解率を高めようとするものです。
これらは技術的にはどれも、「画像」と「音声」という異なる属性のデータ間で、「対応関係」を「学習」したり「推定」することを可能とする「特徴空間ベクトル」モデルに基づいています。
Word2Vecや、RNNやLSTMなどの時系列ディープ・ラーニングモデルといった、いわゆるディープ・ラーニングモデル(深層ニューラル・ネットワークモデル)の要素技術が急速に改良されたことで、私たちは、静止画や動画、音声、さらには、文章や、温度・湿度・加速度といった、種類の異なるデータを、(数学上の)高次元のベクトル空間内の「ベクトル」というひとつの共通フォーマット(データ形式としては、数字の羅列)に変換(「写像」, mapping)して表現することができるようになりました。
それにより、例えば、文章どうしの意味の類似度を計算したり(Word2Vec, Paragraph2Vecなど)、画像どうしの類似度を計算(CNNモデルなど)したり、音声どうしを合成して新たな音声を生成する(DeepVoice1モデル~DeepVoice3モデル)ことができるようになり、
同じ種類のデータどうしで意味内容の近さ・遠さを定量的に演算したり(コサイン距離の算出などにより定量化)、同一種類の複数のデータを混ぜ合わせたり、加工したりすることが(計算機上のベクトル演算によって)可能になりました。
また、同じ種類のデータどうしでなく、異なるデータどうしについても、こうしたことができるようになりました。
例えば、静止画や動画を文章に変換することで、動・画像のキャプション文を生成したり、文章を(文章を読み上げる)声に変換すること(DeepVoice1モデル~DeepVoice3モデル)で、文章の自動読み上げソフトを開発したりすることができるようになりました。
異なる種類のデータを、「特徴ベクトル」という共通のデータ形式に変換することで、Word2VecモデルやLSTMモデル、DeepVoiceモデルやSeq2Seqモデル・EncDec(Encoder-Decoder)モデルの中で、「ベクトル演算」によって処理することができることは、以下のスライドの27スライド目で分かりやすく表現されています。
- [スライド] Yuya Unno (Preferred Infrustructure)「深層学習による機械とのコミュニケーション」
(以下、転載)
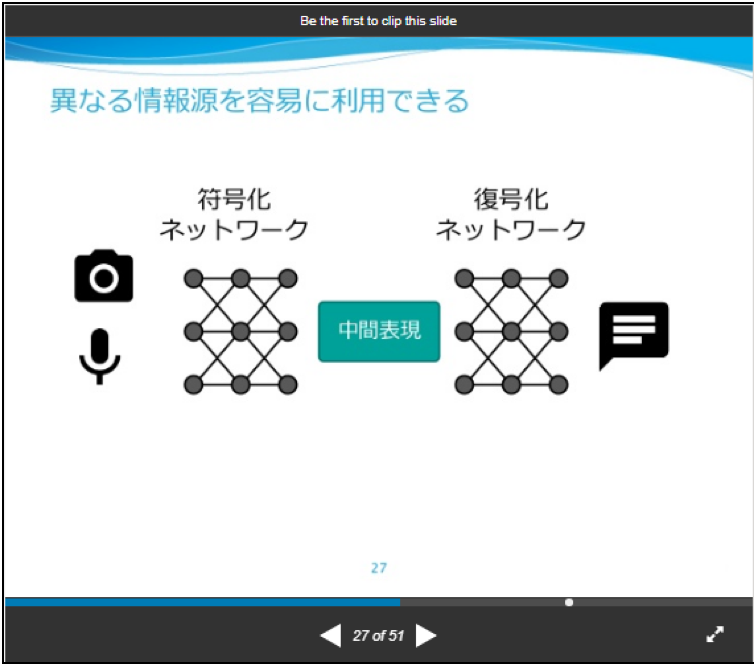
(転載終了)
新しい試みとしては、日本語や英語などの「言葉」で指示を出した通りに、ロボットを動かすために、言葉(語句や文、文章)を行動に変換する次の論文も、早稲田大学に在籍する日本人の研究者によって提案されています。
- Tatsuro Yamadaほか(2017), Representation Learning of Logic Words by an RNN: From Word Sequences to Robot Actions
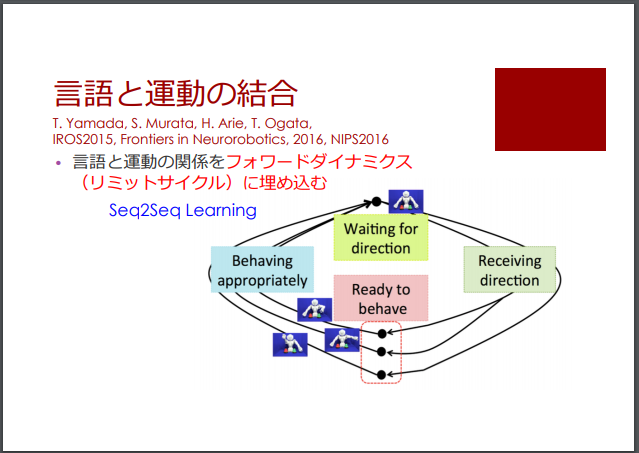
このモデルは、「言語と運動の結合モデル」として、ディープ・ラーニング技術の最近の進化の動向を評価した以下のスライドの31スライド目で取り上げられています。
・ [スライド] 尾形 哲也 「ディープラーニングの実世界応⽤と今後の可能性」
(転載)
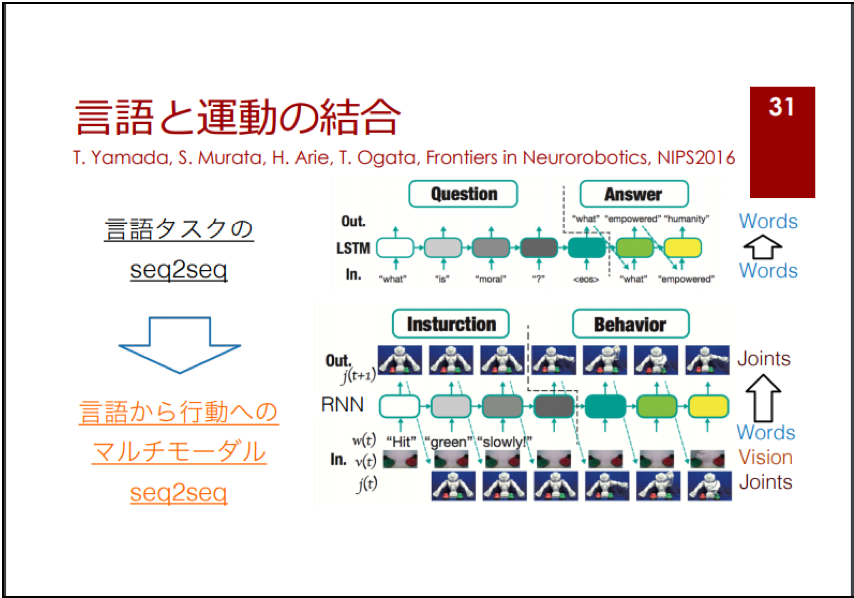

(転載終了)
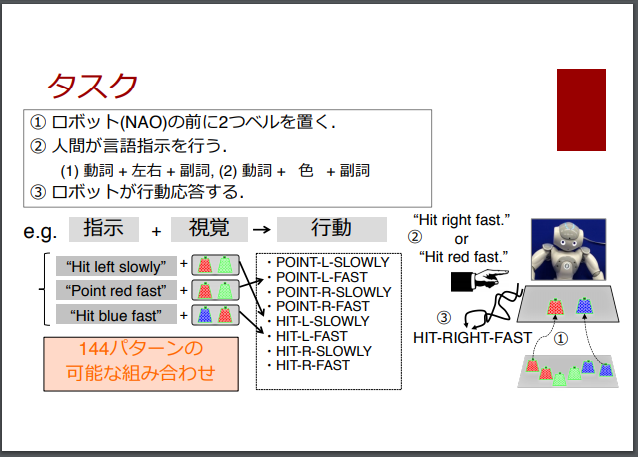
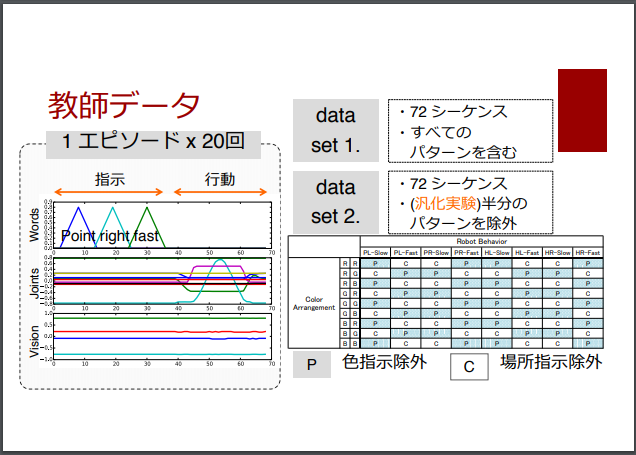
また、以下のスライドでも、36~40スライド目でも取り上げられています。
[スライド] 尾形 哲也 「ディープラーニングのロボティクス応⽤の可能性」
(転載)

このように、日本語や英語などで与えられた言語指示を、(ロボットがとるべき)行動系列に変換する、異種データ間のデータ変換モデルの提案事例としては、DeepMind社からも、以下の研究成果が論文として公表されています。
- [論文] Karl Moritz Hermannほか (2017), Grounded Language Learning in a Simulated 3D World
なお、上記のDeepMind社の研究を先行研究とした後続の研究としては、Baidu(百度)社から、2018年に次の論文が発表されています。掲載先は、世界最高峰の国際論文誌ICLRです。
- Haonan Yuほか(2018), Interactive grounded language acquisition and generalizaiton in a 2D world
(以下、転載)

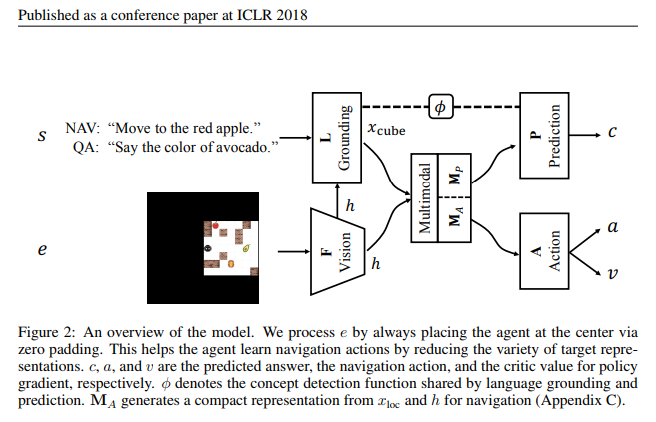
(転載終了)
以上、「文や文章」から「行動系列」にデータ変換(写像)する深層ニューラル・ネットワークモデルの紹介に脱線しましたが、異なる種類のデータどうしの対応関係を学習させたり、一方でデータを(種類の異なる)もう片方のデータに変換(写像)させたりすることが可能な「ベクトル空間モデル」という大きな技術の枠組みの中で、「画像」から「音響・音声・肉声」を推定・再現したり、「画像」を頼りに「音響」のクラス分類を行うモデルが提案されていることを、おさえておきたいと思います。
「画像」と「音響」の「対応関係」を学習したモデルは、GoogleやMicrosoftのサービスに、今後どう活用されるのか
この問いが、この記事が読者に問題提起したい論点です。
2次元画像から、3次元画像を推定する技術
2次元画像から、3次元画像を推定する技術の研究も進んでいます。
以下の論文があります。
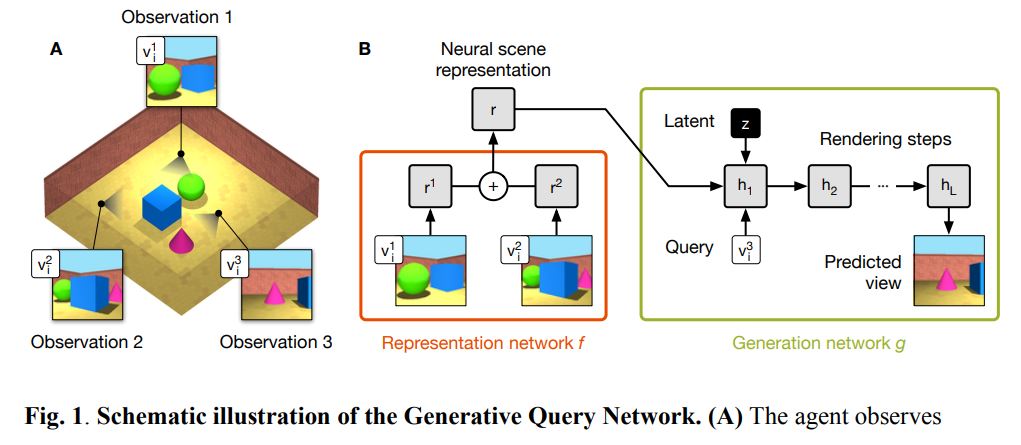
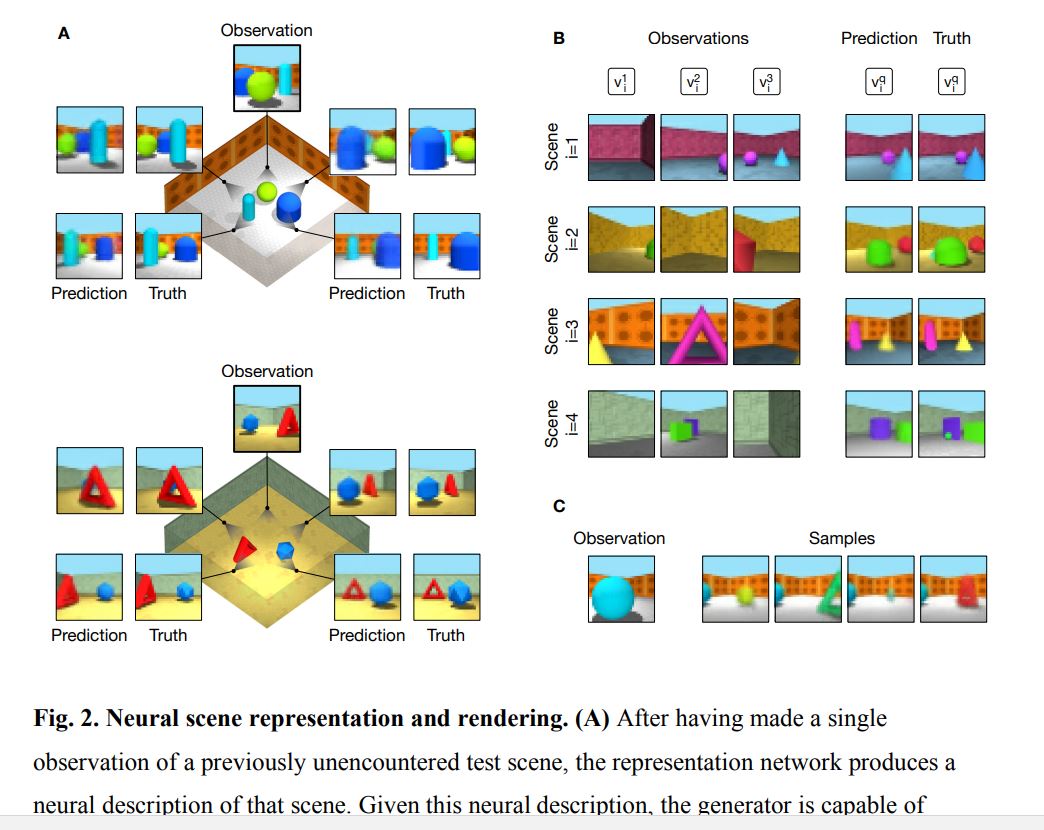
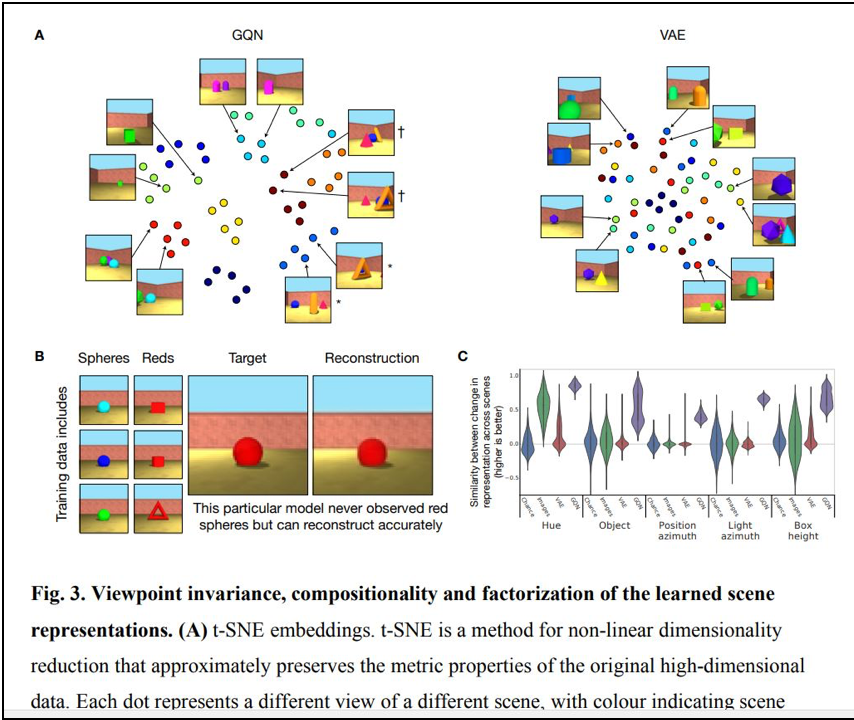
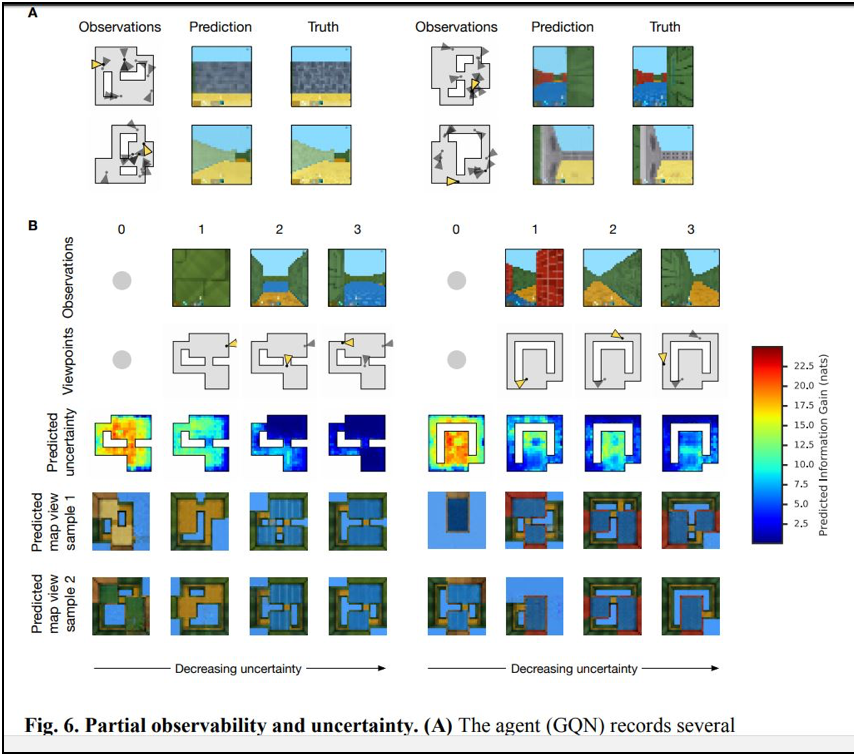
まずは、Google DeepMind社の論文です。 Generative Query Networkと呼ばれるモデルが提案されています。
この研究は、2次元画像から3次元画像を構築することを直接、主題にしたものではありません。そうではなく、ロボットが周囲の状況を少しずつ理解する際に、いま自分がいる場所からは、死角になって見えない部分を「推定する」というモデルです。
その意味では、「2次元画像から3次元画像を構築する」論文とは目的が異なるのですが、関連論文として、取り上げます。
- [論文] Neural scene representation and rendering
- [Gigazine解説記事] (2018年6月18日付け)目に見える情報から「見えない部分」を推測して3Dモデルを生成する「GQN」
- [解説スライド] [DL輪読会]GQNと関連研究,世界モデルとの関係について
- [解説記事] (2018年6月15日付け)Google DeepMind、マシンが周囲を認識するために、2D画像から3Dシーンを推定する教師なし視覚認識ニューラルネットワーク「GQN」を発表
- [解説記事] 【最新AI技術】Deep Mindが二次元データから三次元データを生成する技術を開発【GQN】
- [解説記事] DeepMind’s AI can ‘imagine’ a world based on a single picture
- [解説記事] 最先端のAIは、私たちの3D空間理解に近付いている
以下、論文より図表を転載します。
後続の論文としては、同じくDeepMind社から次の論文が出ています。
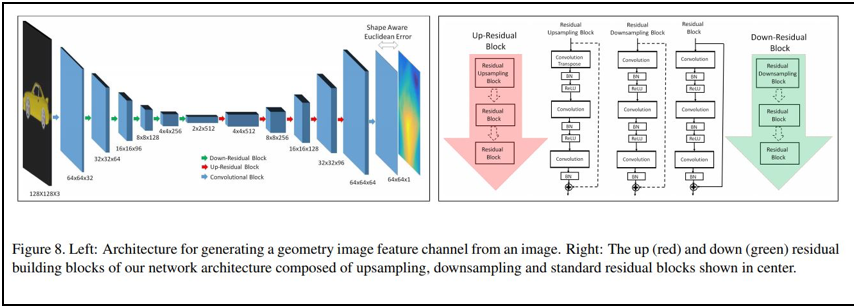
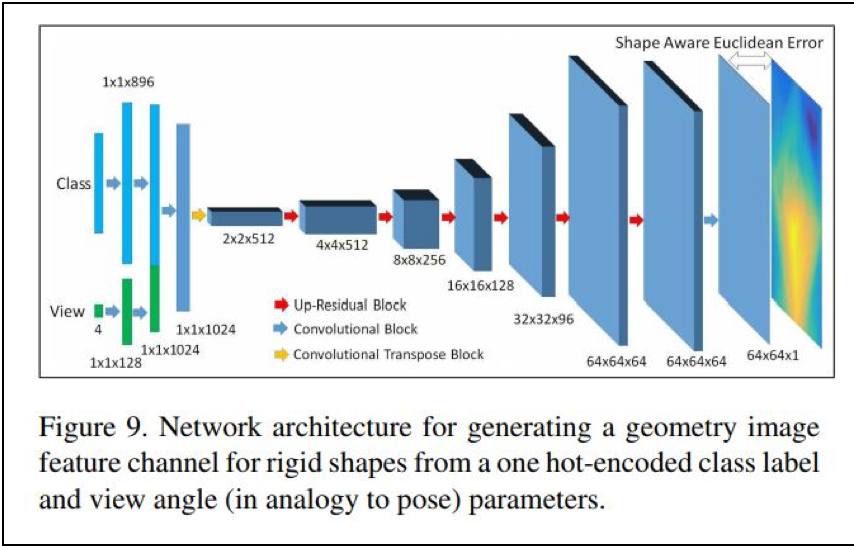
なお、2次元画像から3次元画像を構築する技術そのものについては、MITから、「SurfNet」モデルが提案されています。
- [論文] SurfNet: Generating 3D shape surfaces using deep residual networks
- [解説記事] 2次元画像を3次元モデルに変換するAIシステム「SurfNet」
以下、論文より転載します。

使われているモデルは、次の深層ニューラル・ネットワークモデルです。
画像から「音」・「素材の材質」・「3次元立画像」を推定できる技術は、今後、商用サービスにどう組み込まれていくのか
画像から「音」・「素材の材質」・「3次元立画像」を推定できる技術は、今後、商用サービスにどう組み込まれていくのでしょうか。
本連載シリーズでは、技術について少し立ち入って見ていくのとあわせて、今後、産業競争はどのような商用サービスや商品をめぐって、世界で戦われていくのか、この点を最大の関心事と位置づけて、可能な仮説を提示していきたいと思います。
















