
はじめに
はじめまして、私はHmcomm株式会社R&Dセンター主任研究員の廣岡と申します。これまで大学の研究員として超高層物理学、地震先行現象の研究に取り組んできました。大学の研究では主にニューラルネットワークを用いた機械学習による信号処理の研究に従事しておりましたが、近年のディープラーニングの発達、音声による精神疾患の予測・診断補助技術の確立に興味を持ち、Hmcomm株式会社にて音を通じて社会へ貢献する道を選びました。
それでは、近年注目される音声認識の現状から、Hmcommの取り組み、これから実現しようとしている未来社会について紹介させていただきたいと思います。
音声認識の現状
近年、音声認識システムの精度はディープラーニングの導入により飛躍的に向上しています。このことにより、スマートフォンアプリの普及や音声案内ロボット、スマートスピーカーが大変な注目を集めています。
ディープラーニングの基礎となるニューラルネットワークの研究は1940年台から開始され、F・ローゼンブラットによるパーセプロトン(視覚や脳の機能をモデル化したもの)の発表で多くの期待を集めましたが、その後のM・ミンスキー, S・パパートによりパーセプロトンの限界が指摘されることで第一次ブームは終焉を迎えました。
その後、D・ラメルハートによるバックプロパゲーションの発明により、第2次ブームが起きます。しかしながら、ここでネックになったのはニューラルネットの多層化による効果が実際にはそれ程期待できなかったことと、学習データの不足でした。この状況が変わり始めたのは2000年代後半になってからです。いわゆるビッグデータの利用が可能になり、2006年のJ・ヒントンによるディープニューラルネットワーク、A・ングによるディープラーニングの提唱により、初めは画像認識の分野で既存手法に比べ圧倒的な精度を叩き出し、いよいよ世界の注目が集められます。
その後、ディープラーニングは多方面に応用され、音声認識にも導入されるようになりました。音声認識では長年にわたってGMM-HMMという手法が使用され、多くの先人達の努力により少しずつ認識精度が向上してきましたが、残念ながら製品レベルでは多くの人々を満足させることは出来ていませんでした。図1に音声認識精度(単語誤り率)の変遷を示します。
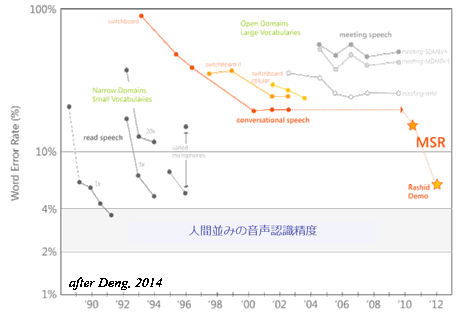
図1
会話音声(赤線)に注目すると、2000~2010年頃まで単語認識誤り率はほぼ横ばいでしたが、2011年頃ディープラーニングの登場による技術的な大転換点がありました。その後もディープラーニングをベースとした音声認識アルゴリズムの改良は世界中で精力的に進められ、現在人間並みの認識精度(単語誤り率4 %以下)にせまるレベルに至っています。
現在、皆さんが使用されているスマートフォン端末の音声認識アプリやAIスピーカーはこのような長年にわたる研究開発が実を結んだ結果と言えます。
Hmcommの取り組み(次世代音声認識システム:End-to-End音声認識AIの実用化)
弊社は今から5年前、国立研究開発法人産業技術総合研究所(産総研)の研究成果を社会へ普及させるため保有する知的財産を核とした技術移転を図る制度を利用し、厳正な審査の後「産総研技術移転ベンチャー」に認定されたことで本格的に音声認識の分野に参入しました。これはディープラーニングによる音声認識の技術的大転換が起きた直後の出来事です。
弊社では現在、産総研の技術移転を受け、弊社独自技術とともに音声認識と自然言語処理を組み合わせた、コールセンター向けシステム(VContact:大手プロバイダー事業者様、都内テレビ通販事業者様にて導入)や顧客管理(VCRM:某大手銀行様で導入)、音声案内ロボット向けシステム(VRobot:某旅行大手様で導入)、会議録作成システム(VMeeting)など多様な製品群を展開しています(http://hmcom.co.jp)。
また、弊社では非常に先進的な技術開発にも挑戦しています。弊社は今年、国立研究開発法人新エネルギー・産業技術総合開発機構(NEDO)によって公募のあった「次世代人工知能・ロボット中核技術開発/次世代人工知能技術分野」(調査研究)において、「多様話者・多言語に対応可能な“End-to-End音声認識AI”の実用化」という研究テーマで最優秀賞を受賞しました(http://www.nedo.go.jp/news/press/AA5_100828.html, 図2)。
本研究は平成31年3月までの計画で、現在学術レベルで盛んに研究が進められているEnd-to-End音声認識システムの精度向上、プロダクト化を目指す、極めて先進的なプロジェクトです。現状の一般的な音声認識システムは音響モデル・言語モデル・発音辞書により構成され、それぞれディープラーニング等による学習、パラメータの設定、人手による言語資源(辞書)の追加など、多大な開発・導入コストが必要になります。また、日本語においては形態素解析(品詞など言語において意味を持つ最小単位への分割)を行う必要がありますが、我々が開発中のEnd-to-End音声認識システムでは辞書作成や形態素解析を必要としません。これによって、開発・導入コストを大きく抑えられるほか、多様話者(多様な言語、方言)に容易に対応可能になります。その結果、「中小企業のコールセンターでの導入の促進」、「僻地遠隔医療の普及・高度化」、「インバウンドの促進」、「方言に対応した国産スマートスピーカーの開発」が可能となります。図3に本研究の社会実装イメージを示します。

図2
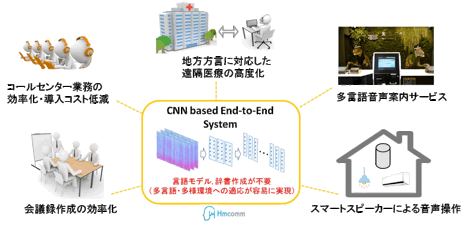
図3
Hmcommの目指す未来社会
弊社では、これまで蓄積してきた技術と3で紹介したような先進的技術を組み合わせ、我が国が抱える社会問題の解決に大きく貢献することを目指しています。
現在、一部の企業に限られている音声認識システムを中小企業での導入を促進することで、業務効率の改善による収益向上のみならず、電話対応の自動化、無人化によって深刻な人材不足の解消が期待されます。また、英語をはじめとした主要言語以外を母語とする外国人にとって、安心して観光を楽しむ環境が整うことで、観光業を中心としたビジネスチャンスの拡大が予想されます。
このような環境整備は、2020年東京オリンピックを控え急増が予想される世界各国からの旅行者の利便性向上や、東南アジア、アフリカなど今後さらなる発展が見込まれる国々とのビジネスチャンス拡大にもつながると考えられます。加えて地方在住高齢者に対する遠隔医療の高度化により、今後さらに進む高齢化社会においても安心して暮らすことができる社会を実現できると考えています。
また、音声の変化から精神疾患の予測・診断補助が行える可能性が複数の研究で指摘されています。現代社会において、うつ病に代表される精神疾患は多くの方が一生に一度は罹患する可能性のある疾患であり、早期かつ継続的な治療がなされなければ、本人だけでなく社会的損失も甚大なものになります。Hmcommとしても、このような問題に対応すべく、音声を一種のバイオマーカーと捉え、定量的に疾患の早期予測・診断ができるシステムの構築を進めていきたいと考えています。
さらに将来的な発展として、音声と画像と動画データを統一的に扱うフレームワークの構築を構想しています。音声だけでは判断しにくい表情の変化や、画像だけでは判断が困難な声の変化を定量的に評価することで、医療、防犯、エンターテイメントなど様々な分野でのイノベーションの促進が期待されます。
おわりに
これまで述べてきたように、Hmcommでは音声認識を通じて単なる利便性の追求だけでなく、社会が抱える様々な問題を解決し、人々が安心して暮らせる社会実現の一助となるべく、今後も研究開発に邁進してまいります。



























