
DATUM STUDIO株式会社はAIを使った文書校正ツールの提供を「マイクロソフトが展開するクラウド検証環境構築サービス「Microsoft Cloud Everywhere」に開始いたしました。
本ツールはマネックス証券に導入されている実績のあるツールを一般化して拡販するものです。これにより、文章校正の自動化を検討する全ての企業に、より手軽にサービスを利用していただく事ができるツールとなっております。
以下では、マネックス証券での構築事例から本ツールの仕組みを解説いたします。
ツールの解説
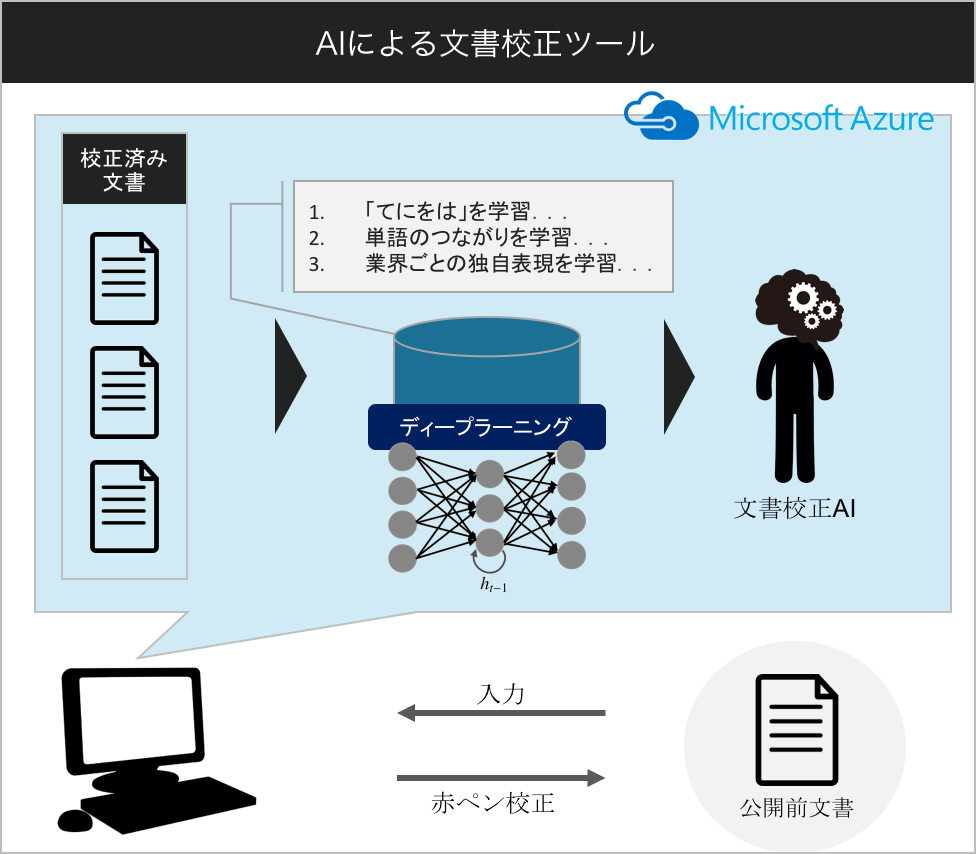
文書校正ツールの仕組み
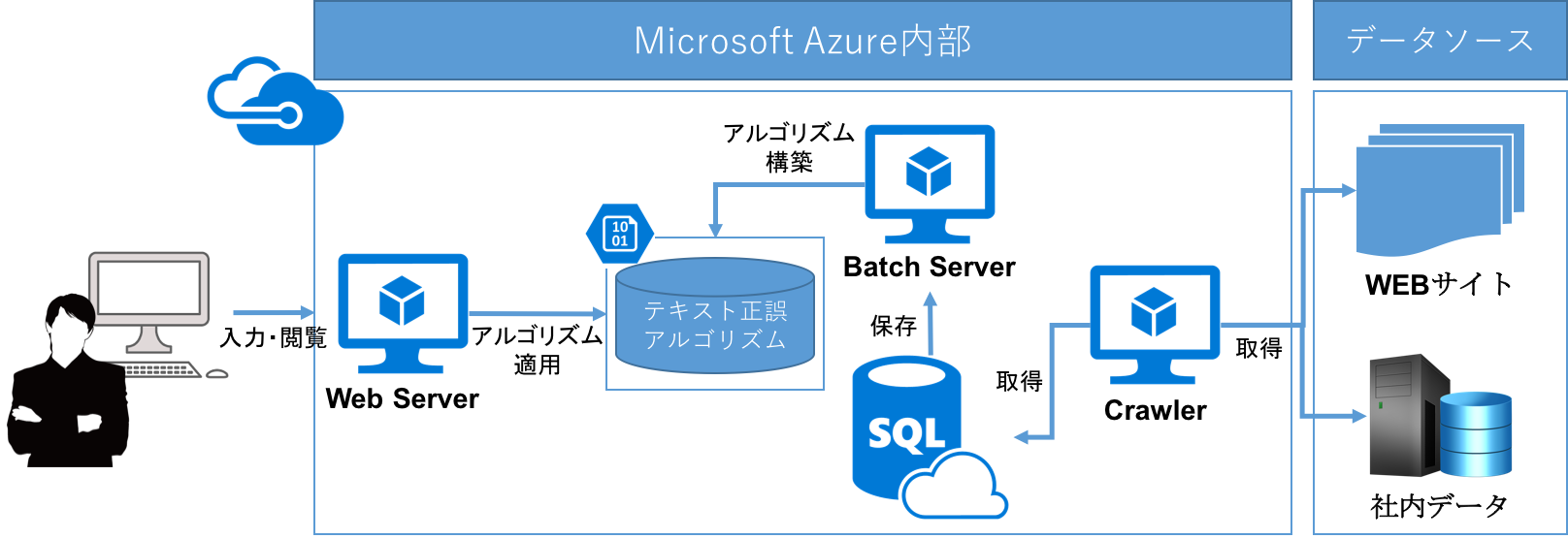
システム構成図 on Microsoft Cloud Everywhere
業界独自表現も短時間で校正
本ツールの特徴として、日常的な文章から特定の業界に特化した表現方法まで、あらゆる文章を短時間に校正可能であることが挙げられる。これはルールベースに依らずに既存のテキストデータから文章に出現する語句の関係を学習するAIならではの特徴と言えます。
AIの教師データには、校正したい文章カテゴリで、すでに校正済みであると考えられるインターネット上のコンテンツやメールマガジンのテキストデータを使用する。学習させる表現の幅にもよるため一概に必要なデータ数を明言することは難しいが、数千個のテキストデータで十分に学習できることもあります。
いざ導入を検討したとき、社内に公開済み(校正済み)文章が保存されていない場合があるかもしれない。そんなときにはデータソースをクローリングして学習データにすることができます。取得したデータをクラウド上のデータベースに保存し、アルゴリズム構築のための教師データとします。
保存した教師データ、または社内に保存されていたテキストデータに対して、まずは正規化、ストップワードの除去などの前処理をかける。また、出現頻度が一定以下の文言については、予測することは難しいと判断して削除する。学アルゴリズムは時系列データに特化した深層学習アルゴリズムであるLSTM(Long Short Time Memory)を使用し、ドロップアウトなどのパラメータチューニングを徹底的に行い学習させるデータの形式は、単語と形態素の2パターンで作成したN-gramであります。
このアルゴリズムからは、「ある語の入力についてその次の語として出現する確率のスコア」が出力される。このスコアを高い順に表示し、最もスコアが高いものを次の語の候補とする。このとき、スコアの閾値が一定以下の学習結果は使わない。予測スコア上位10位内にはないものが実際の入力文書に出現していた場合には、「間違っている入力」の候補として赤字で強調する。予測スコア10位内にあるものが実際の入力文書に出現した場合を「正解」と定義すると、サンプルデータ上では8割〜9割の安定した正解率を実現しています。
また、現状のツールではできないこととして、時事的な語句や商品名など固有名詞は予測できない(赤字で指摘される)可能性が高いです。 その他、一般的に使用される助詞の後や句読点の後の語句は予測が難しく、やはり赤字で指摘されることが多いです。
このように、教師データに含まれない語句に頑健ではないことがAIを使用している本ツールで対応できないこともあります。
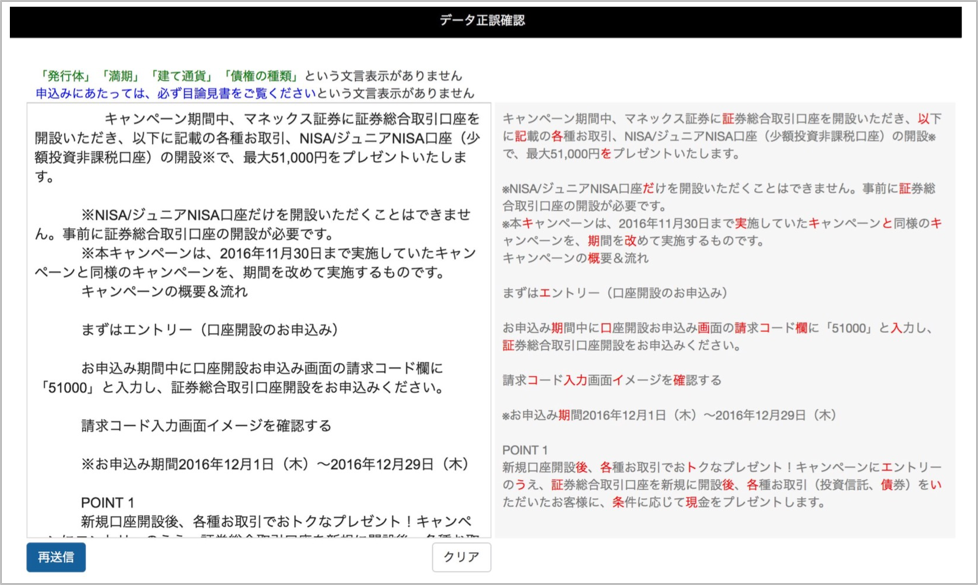
文書校正ツールの出力例
ツールの使い方について
本ツールは校正部門の人間を一掃することを目的とした、またはその橋頭堡となるツールではなく、あくまでも校正部門で働く人間の業務効率化を意図したものであります。今までは文章の上から下まで目を皿にして確認しなければならなかったが、このツール導入後は赤字で指摘される部分のみを確認すればよいことになっています。AI全般に言えることですが、AIの出力を人間が確認し、最終的なジャッジを人間が下すことが重要です。
真の業務効率化とは全てAIや何らかのツールに業務を一任することではなく、人間とAIにそれぞれの得意分野を生かした役割分担を課すことであると考えています。
本ツールがその一助となれば幸いであります。
著者 : DATUM STUDIO㈱ データアナリスト 塩見 佳大



























