

初めまして。きょぴおです。
お金稼ぎたい。そんな一心で仮想通貨の予測をしました。
目次
はじめに
とにかく話題の仮想通貨。2017年の年末には200万を超えたり、最近だと580億円分の不正流出が起きたりと、その話題が尽きることはありません。
そして、今や実用化のフェーズに達したディープラーニング。簡単に言うと、「今まで人間が与えていた特徴を自動で決定する」という仕組みです。ライブラリの充実により、比較的簡単に取り組むことが可能となりました。
最近では、AIを使った仮想通貨市場予測などサービス化も実際に行われています。
今回はディープラーニングを使って、仮想通貨の予測を行いたいと思います。
入力データを考える
まず、単純に過去の価格のみで予測を行うということが考えられます。
しかし、仮想通貨の価格変動は株価などとは違い、一日で10%以上変動する事が多く、過去の価格のみを入力データとして与えても、精度はそれほど上がらないことが予想されます。
過去価格+αのαをどうするか。。
そこで思いついたのがTwitter。
私も仮想通貨の取引は行っているのですが、取引中に思ったのが、Twitterインフルエンサーが「ビットコイン買い増し!!」みたいなツイートをすると、価格が上昇する傾向があるということ。
そこで入力データは「過去価格+ツイート」とします。
ツイートをどう取り込むか
ツイートはテキストデータなので、どのように学習データとして取り込むかを考える必要があります。
テキストデータをコンピュータに理解させる方法として、例えば以前紹介した、Word2Vecというというものがあります。
単語をベクトル化することで、単語をコンピュータが扱いやすい表現に変換する方法です。
こうすることで、同じような文章で使われる「犬」と「猫」は似たベクトルを持つというように、コンピュータに理解させることが可能となります。
しかし、ツイートは文章なので、例えば「ビットコイン上がりそう」みたいな文章があったとき、キーワードの「ビットコイン」だけでは価格の変動がわかりません。
文章ではキーワードの単語とその前後関係も考慮したい。
これを解決する方法として、Doc2Vecというものがあります。
Doc2Vec
Word2Vecを応用したもので、単語レベルではなく文章レベルでベクトル化するというものです。
応用例として、
- 感情分析
- スパムメール判定
などがあります。
これにより、「ビットコイン○○円で買った」と「ビットコイン買い増し」みたいなのが同じ意味で理解できるようになります。
とりあえずDoc2Vecを使ってみた
実際に入力データとして取り込んで価格予測する前に、まず、ツイートのベクトル化がうまくいくかを検証します。
Doc2Vecでベクトル化する手順は大まかに以下の通り、
- ツイートを取得し、テキストファイルとして保存
- 単語に分解
- Doc2Vecで学習
- 結果出力
ツイート取得
まず、仮想通貨界隈で影響力がありそうなインフルエンサーを数名ピックアップします。そして、その人達のビットコイン、仮想通貨関係のツイートをテキストファイルとして保存します。この時、学習に悪影響を与えそうなノイズのツイートを除く処理も行います。

学習データ例

テキストファイルとして保存
単語に分解
Doc2Vecで文章を学習させるには単語に分解する必要があります。
この時、日本語の形態素解析ライブラリMecabを使用します。形態素とは意味をもつ持つ最小単位です。
また、精度を上げるために今回は動詞・形容詞・名詞にしました。
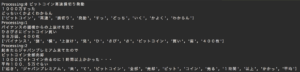
MeCab処理後
Doc2Vecで学習
次に形態素解析を行った文章を使って、学習を行っていきます。Doc2VecはPythonのライブラリgensimから使用することが可能です。これにより、簡単に実装が行なえます。
学習自体はホントあっという間に終わってしまいます。びっくりしました。
学習結果出力
学習がうまく言っているかを検証します。
「ビットコイン買い」というポジティブなツイートに似ているツイートを検索します。
すると以下のような結果になります。
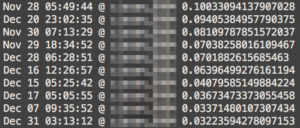
Doc2Vec出力結果
右側の数字が大きいものが、類似度が高いことを意味します。実際に類似度が最も高い文章を見てみます。
最も類似度の高いツイート
このように「ビットコイン買い」と全く同じ意味のツイートが得られました。
他のツイートもほぼ同じ意味だったので、学習は上手くいっているということにします。。
実際に価格予測をする
Doc2Vecの学習が大体上手くいったので、実際に仮想通貨の価格予測を行います。
仮想通貨といってもたくさんの種類があります。その中でも一番有名なビットコインを対象にしました。

過去価格のみで予測(重回帰分析)
比較のためにまず、過去の価格のみで予測を行います。
以下を参考にしました。
仮想通貨取引所のPoloniexからAPI経由でデータ取得し、ディープラーニング(Chainer)で翌日の価格予測をしよう@Qiita
仮想通貨の価格を取得するには、取引所のAPIを使う必要があります。今回は、CryptowatchのAPIを使用し、bitflyerのBTC/JPYペアの価格を使用しました。
ディープラーニングを使う前に、重回帰分析で価格予測を行います。
使う価格データは2017/8〜2018/2のおよそ半年分。
使用する価格データ
トレーニングデータとテストデータに分け、重回帰分析で予測すると以下のような結果になりました。
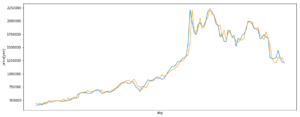
トレーニングデータに対する予測結果
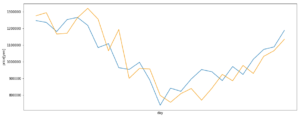
トレーニングデータに対する予測結果
ピークがずれてしまっています。
1サンプル前のデータを反映させているような感じ。これではだめです。
機械学習においては、「回帰」と「分類」があります。
回帰は主に連続するデータの予測に用いられます。連続した数字を出力します。今回のような価格予測などが例としてあります。
回帰の例
分類は予め与えられたクラスを出力とします。犬と猫を区別するとかそんな感じです。
分類の例
重回帰分析はその名の通り、回帰です。回帰問題のまま進めようかと思いましたが、精度はそれほど出ないだろうと予想されるため、分類問題に帰着します。
1つ前の価格から、すごい上がる・上がる・下がる・すごい下がるの4分類にします。
まず、前日との価格差をヒストグラムで確認します。
単純に価格の差分を取ると、人間の大小感覚とずれてしまうため、対数化を行います。また、オーダーが小さい値となるので、100倍にしてあります。
得られたヒストグラムを参考に、閾値は分散を計算した結果から、±5%とします。
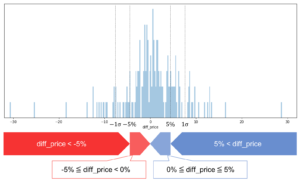
前日との価格差のヒストグラム
以下が±5%の閾値で4分類を行った比率になります。
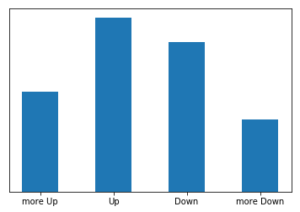
分類比
これで分類を行う準備ができました。
過去価格のみで予測(分類・LSTM)
今回は、LSTM(Long Short-Term Memory)というモデルを使用します。
再帰型ニューラルネットワーク(RNN)のひとつで、自然言語や動画など、時系列も考慮する場合に用いられます。
過学習抑制のため、Dropout層も入れてあります。
モデル構造は以下のようになります。

過去価格のみで予測するモデル
価格データのうち9割をトレーニングデータ、1割をテストデータとしました。
評価の際、すごい下がる、下がる、上がる、すごい上がるの4クラス分類の正答率に加え、価格の増減のみ正答率も評価します。

評価方法
価格データはそのまま入力データとして与えると、値が大きすぎるためか、学習が上手く進まないため、0〜1の範囲で正規化を行っています。
以下がテストデータに対する評価結果です。
| 4クラス分類の正答率 | 2クラス分類(増減のみ)の正答率 |
| 20% | 67% |
ついにTwitterデータも入れる
いよいよこの時が来ました。
ベクトル化したツイートを入力するために2入力のモデルを作成します。
モデル構造は以下のような2入力1出力となります。
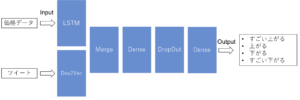
過去価格とツイートで予測するモデル
Doc2Vecはベクトル化した際の次元数の指定が出来ます。今回は400次元としました。
結果は以下の通りになります。
| 4クラス分類の正答率 | 2クラス分類(増減のみ)の正答率 |
| 13% | 60% |
入力に価格データを用いた場合と比較し、正答率が低下してしまいました。
まとめ
入力データにツイートも考慮することで精度が向上するかを検証しました。
結果として、正答率が低下してしました。入力データの種類を増やすことで、単純に精度が向上するというわけではないようです。ツイートデータの整形やモデルへの入力方法について少し考える必要がありそうです。
仮想通貨の価格は基本的に上昇傾向であって、常に予測結果を「上がる」にしても6割ぐらい出そうです。
今後は、モデル構造、他のデータも含めることで精度が向上するかを検証していきたいと思います。



























