

おざけんです。
今回の記事は自然言語処理技術に着目します。
自然言語処理技術はAI・人工知能技術の中でも特に注目されています。自然言語という人間が生活の中で使う言語を機会が解釈することができれば、その活用の幅は飛躍的に広がるでしょう。
特に注目されているのはチャットボットの技術です。新しいインターフェースとしてスマートフォンを凌ぐ技術だとされ2016年あたりから話題になった技術です。
AI関連の展示会では相変わらずチャットボット系のサービスの展示が多いものの、世間的にはチャットボット技術はまだ下火と言えそうです。それは自然言語技術にはまだまだ発達の課題があるからです。
今回は、Uberで自動運転のプロジェクトに携わった後、自然言語処理に当たる教師データ作成を行う株式会社Gengoに参画したチャーリーワルター(以下チャーリー)にインタビューしました。

目次
自然言語処理とは?
自然言語とは生活のなかで人間が使っている日本語や英語などの言語のことです。今までは機械に解釈できなかった自然言語を、AI・人工知能技術で理解させようと研究が進められています。
自然言語処理では、大きく分けて3つの段階に分けられます。話しかけられた言葉の意味を理解し、適切な行動を決定し、ユーザーが理解できる言語で反応する3つの段階です。
チャーリー「自然言語処理技術には大きく3つのパートがあります。 【理解】【行動】【反応】です。
まずは人間が何を言いたいのかを理解しなければなりません。それがNatural Language Understandlingとも言われる自然言語理解の部分です。
そして、人間の言ったことを理解した上でアクションを起こします。例えば、AmazonのスマートスピーカーAlexaに『トイレットペーパーを注文して!』と言ったら、その意図を理解して注文をしますよね。それが行動、アクションに当たる部分です。
そして最終的には反応をしなくてはいけません。Alexaにトイレットペーパーを頼んだのであれば、発注をした上で『トイレットペーパーを買いました!明日届く予定です。』のように反応をすることですね。」

自然言語処理の研究ではこの中でも【理解】と【反応】の部分で研究開発が行われています。アクションの部分は、アプリケーションに関わる部分であり自然言語処理とは関連が低い部分です。意味の理解、そして反応=発話が大きな研究テーマとなっています。
自然言語処理の難易度 なぜまだチャットボットは話せないのか?
自然言語処理技術は多くの企業・団体で研究されている技術です。しかし、まだ人間と同じレベルの会話技術を持っているとは言えず、決まったようなフレーズにしか対応できていないものが多い現状です。
チャーリー「人工知能が判断能力を得るには、たくさんのデータを学習し、その中から規則性を得ないといけません。しかし、会議の録音データや普通の文章データなどの生データは、人工知能のモデルに入れることはできません。文章のデータの一つひとつにタグを付けをして、学習できるようにしなければならないんです。
また、日本語は英語のように単語と単語の間にスペースがありません。音声解析では日本語と英語の違いは少ないのですが、文章の場合は日本語は言葉の分割が必要になります。その言葉を分割した上でタグ付けをしていく必要があるため、データを集めることがとてもむずかしいんです。」

タグ付けの様子。「備えた」をVERB(動詞)とタグ付けをしたり「11月」をDATE(日付)とタグ付けしていることがわかる。また同じ「クイーン」という単語でもクイーンサイズの”クイーン”なのか、女王の”クイーン”なのかを正確に推定している点に注目。
「また、エンティティ・アノテーションというのですが、『私 は チャーリー です』という文章があった場合、チャーリーという単語が普通の言葉ではなく人の名前だというタグを付けないと、自然言語処理技術の精度は上がりません。
GengoAIでは、機械が学習できるデータにするために多くのクラウドワーカーのコミュニティを構築して、言語のプロにタグ付けをしてもらっています。Gengoのクラウドワーカーは日本語の記事などの文章をもらって、その記事の中でどれが人の名前でどの単語が組織の名前なのか、どの単語が場所の名前でどれが会社の名前なのかのタグを付けているんです。
言葉の関係も重要になってきます。どれが主語でどれが述語なのか。どれが副詞なのか。そういうタグを付けることも大切です。
また、もう一つ重要な点として感情分析が大切です。特にチャットボットを作るときに、感情分析ができないと、【反応】が変わってきます。同じ行動でも反応の仕方が変わってくるので感情もタグ付けして学習していくことが大切なんです。」

チャーリーが言うように、タグ付けがされたデータセットはまだ多くありません。非常にコストがかかることが原因なようです。
チャーリー「大きいデータセットは、さまざまな機械学習に適用したりできるんですが、やはりデータの質は大切なので、目的にあったタグ付け、データの作成が必要になります。そこでコストがかかってしまいます。
また、チャットボットにおいては会話のフォーマットのタグ付けされたデータが少ないんです。日本の新聞の記事を読んでデータを作っても、会話ではないため、あまり使えません。また、不動産やパソコンなど特定の分野のチャットボットであればその分野特有の会話データがないと精度が上がらないんです。
卵が先か鳥が先かになってしまいますがチャットボットの会話のレベルが高くないから、ユーザがあまり使わない、使わないからデータが増えずチャットボットの会話のレベルが上がらないという問題があり、その解決方法を見つけるのが今の大事なポイントです。」
チャットボットは自然言語処理への依存度が非常に高いため、自然言語処理の限界から制約を受けてしまいます。現在最も優れた自然言語処理ですら、人間の会話能力には及びません。
ユーザーは、コミュニケーションが円滑にできるのであればチャットボットを使いますが、
コミュニケーションに違和感を感じるのであれば使われなくなってしまいます。現在の自然言語処理では、チャットボットは言葉を理解することはできても、言葉の意味まで理解できるとはかぎらないのです。つまり、チャットボットのさらなる普及には、自然言語処理が大きく進歩する必要があります。
日本語と英語の違い
日本語と英語で、自然言語処理技術の違いはあるのでしょうか?
チャーリー「AIという文脈ではデータの量がキーになりなすので、データの量が多い英語のほうがどちらかというと有利になります。日本語よりも英語を話している人のほうがもともと多いですし、AIの研究を強化している会社「Amazon」や「Apple」 「Facebook」は英語圏の会社です。ただ、”どこの会社の技術がよい”とか、”どの言語がすごい”ではなくて、ただ誰が一番データを持っているかが重要だと思います。
日本語では、言葉を分割しなければならないというハードルもありますが、その影響は少ないと思っています。 」

データの量がキーワードになるのは、他のAI関連の技術と同じのようです。そして、他のAI関連技術と同じように自然言語処理においても、データの質を上げることもネックになっているようです。
チャーリー「的確なタグ付けをする必要があります。タグをつけるのも失敗しやすく難しいです。例えば副詞とか動詞とか、誰でも正確ににラベリングできるわけではないですよね。文法に詳しい人でないと、AIに使えるデータを生み出すことはできません。」
自然言語処理のための質の高いデータを生み出すプラットフォームを築いたGengoAI
これまで述べてきたように自然言語処理技術の発展のためには、生のデータに対して正確にタグ付けをしていく必要があります。Gengoは、これまで約9年間に渡って翻訳に特化したクラウドソーシングプラットフォームを構築してきました。その知見を自然言語処理技術の向上に活かそうと2018年4月2日にスタートしたサービスが「GengoAI」です。
GengoAIでできること
自然言語処理に特化したGengoAIはデータの収集から学習データ(AIに学習させるために使うタグ付け済みのデータ)の作成、学習データの再編集を担ってくれるサービスです。
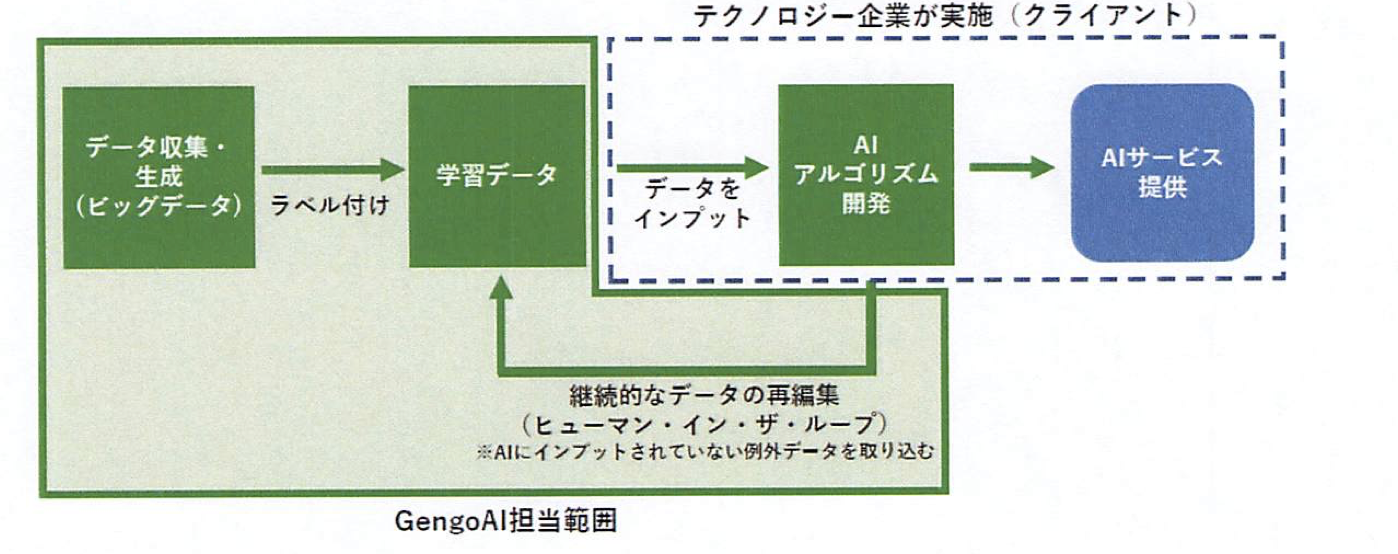
具体的には以下の3つに対応します。
- ビックデータの収集
TwitterなどのSNSの投稿や音声データなど、言語に関連したビッグデータを独自に収集 - ビッグデータの学習データ化
AIが学習できるように、データ一つひとつに意味をもたせるラベリングを行う - 学習データの再編集
AI開発後、すでに読み込んでいるデータだけでは処理できない情報が出てきた際に、新しくデータを再編集するプロセスを繰り返す「ヒューマン・イン・ザ・ループ型」を採用。精度を高めるために、例外ケースに対して、人間が保管することで人間により近づけることができます。
しかし、膨大なデータに正確にタグ付けをするのはなかなか困難なこと。GengoAIは独自の言語のプロのクラウドワーカーのコミュニティを活かしてその打開を目指しています。
チャーリー「GengoAIでは学習データにタグ付けする作業を世界中にいる22000人ほどのクラウドワーカーで担当する言語ごとに分配することで効率化を図っていることが特徴です。そのクラウドワーカーもテストを受けて言語能力が高い人が選ばれています。
クラウドワーカーには『スコア』が用意されていて、テスト合格後も常にスコアが上下するようになっています。スコアが低いと仕事の分配量が減る仕組みになっています。」
多くの分野に対応できるのが強み
GengoAIでは約22000人という膨大な人数のクラウドワーカーがいることは前述の通り。そのクラウドワーカーたちは、それぞれ国や分野・業界がバラバラで多様性があることが特長だといいます。そのため、さまざまな業界やさまざまな言語に対して対応することが可能です。
チャーリー「翻訳やタグ付けは、それぞれの業界の知識がないと難しくなってしまいます。GengoAIではさまざまな業界の知識がある人や、さまざまな言語の知識がある人が集まるため、学習データを柔軟に作ることができることが特長です。」
さまざまな業界に対応できるため、専門用語が多い業界でのチャットボットの作成でも、GengoAIは力を発揮できるといいます。

タグ付けの手順 テキストを取り込み、単語を選択、タグ付けなどを行っていく。それぞれの業界の知識が必要になる。
まとめ
特に印象的な部分はデータ量を抑えた物が自然言語処理を制するという部分です。どの企業が強いかはデータ量が大きく関わります。
しかし、そのデータも質が悪くてはAIとして活用することはできません。自然言語処理のデータの質(ラベル付けの質)を担保するには、しっかりと言語に精通した人がデータを整備する必要があります。
GengoAIは22000ほどのクラウドワーカーを常にランク付けし、評価を行っています。それに応じて、仕事の配分量が変わる仕組みは画期的だなと感じました。
これから自然言語処理は人間のように言葉を理解することができるようになるのでしょうか!?GengoAIがその実現の一役を担うかもしれません。
■AI専門メディア AINOW編集長 ■カメラマン ■Twitterでも発信しています。@ozaken_AI ■AINOWのTwitterもぜひ! @ainow_AI ┃
AIが人間と共存していく社会を作りたい。活用の視点でAIの情報を発信します。



























