
2018年5月、同団体は将来誕生するであろうヒトの意思決定を支援するAIシステムとして「ディベートAI」というアイデアを発表しました。このシステムは、任意の論題についてふたつのAIがディベートした後にヒトがどちらのAIが正しいか判定する、というものです。例えば、「次の休暇で行くべき旅行先は?」とヒトが尋ねると、AI「アリス」は「アラスカ」と答える一方で、AI「ボブ」は「バリがいい」と答えます。そして、アリスとボブがそれぞれの答えの妥当性をめぐってディベートすれば、それぞれの答えの論拠や強みと弱みが明らかになります。こうしたディベートをふまえてヒトが最終的な判断をくだせば、最良の答えにたどり着けるはずです。
以上のようなAIシステムを実現するためには、解決すべき難問が立ちはだかります。その難問とは、ヒトは質疑応答における言葉遣いや内容によって判断基準が揺らいでしまうという現象にどのように対処していくか、ということです。例えば、質問のなかに「道徳的に」という言葉があるか否かによって、判断が正反対になるという調査結果が報告されています。曖昧で移ろいやすいヒトの意思決定メカニズムやバイアスを考慮したAIを設計することは、少なくとも現在の技術レベルでは極めて困難です。
こうした困難を解決する第一歩として、同団体はAIが果たす役割をヒトが代替することによって、問題を洗い出したり教訓を得るというアイデアを提案します。このアイデアをディベートAIに適用すると、まずヒトどうしのディベートをヒトがジャッジするテストを繰り返して、そのテストから得られた教訓をAIに移植する、となります。しかしながら、ヒトだけで構成されたテストを設計するには、AIに関する知識ではなくヒトの心理や意思決定に関する知識が要求されます。そえゆえ、同団体は倫理的なAIを実現するために社会科学者に協力を呼びかけるのです。
価値観や倫理をめぐるヒトの振舞いをAIに移植しようとする同団体の試みは、「AIはどうあるべきか」あるいは「どんなAIを禁ずるべきか」という原理的なガイドラインに関する議論をさらに進めて、「倫理的なAIを作るには何をしたらよいのか」という具体的な方法論に踏み込んでいると言えるでしょう。
なお、以下の記事本文はOpenAIプレス担当者Jack Clark氏に直接コンタクトをとり、翻訳許可を頂いたうえで翻訳したものです。
わたしたちは、現実に生きているヒトがAIと関係しているときにAIと連携するアルゴリズムが首尾よく動作することを保証するために、AIの安全性に関する研究には社会科学者が必要である、と論文に書きました。ヒトの価値観と適切に整合がとれている高度なAIシステムにはヒトの合理性、感情、およびバイアスの心理学に関連する多くの不確実性を解決することが求められます。この論文が目指しているのは、機械学習と社会科学の研究者のコラボレーションを喚起することです。そして、OpenAIでこの問題にフルタイムで取り組む社会科学者の雇用を計画しています。
人工知能(AI)の長期的な安全性に関する目標は、高度なAIシステムがヒトの価値観と整合することを保証することです。すなわち、ヒトがAIにしてほしいことをAIが頼もしく行うことが目標なのです。こうした目標を達成するためにOpenAIでは、ヒトに何を求めているかについて質問し、ヒトが求めていることに関するデータにもとづいた機械学習モデルを訓練し、そして学習したモデルに従ってうまく動作するようにAIシステムを最適化していきたいと考えています。このような研究活動に関する事例にはヒトの選択からの学習(※註1)、討論を通したAIの安全性(※註2)、そして反復増幅を伴う複雑な目標に関する学習が含まれます(※註3)。
残念なことに、ヒトに自らの価値観について尋ねた時に得られる回答は信頼できないかもしれません。ヒトは知識や推論能力に限界があり、反省してみると首尾一貫していないことがわかる様々な認知的バイアスと倫理的信念を持っていることが露呈します。様々な質問方法が様々な仕方でヒトの偏見と相互作用するので、質問の仕方によって良質な回答が得られたり、あるいは質の低いそれしか得られないことが予想されます。例えば「道徳的」という言葉が質問に現れるかどうかによって、行動がどれほど間違っているかについての判断が異なったり(※註4)、また提示されるタスクが複雑な場合、ヒトはギャンブル間で矛盾した選択をする可能性があります(※註5)。
(※註4)アメリカ・ダートマス大学の研究員Ross E. O’Hara氏らが2010年9月に発表した論文『倫理的判断における単語の効果』では、トロッコ問題をはじめとした複数の倫理的判断を問う質問に関して、「道徳的に」という文言の有無によってヒトの判断が異なるかどうかに関して実験を行った。その結果、「道徳的」という文言が含まれた場合、人命を犠牲にするような嫌悪を伴う行動を「許容できる」と答える割合が多くなったことを報告している。
わたしたちは、ヒトの価値観の背後にある論拠に焦点を当てようとする方法論をいくつか持っています。そうした方法論には先述した反復増幅を伴う学習や討論を通したAIの安全性に関する議論が含まれているのですが、これらの方法論が現実的な状況でヒトに対して果たしてどのくらい通用するのかはわかりません。ヒトと連携するAIアルゴリズムに関する問題が、複雑な価値を含む質問に関する自然言語の議論のなかでしか現れないとすると、この問題を解明するには現在の機械学習では力不足かもしれません。
以上のような機械学習の制限を回避するために、わたしたちは機械学習エージェントとヒトがそれぞれの役割を担っている状況を完全にヒトだけで構成されたそれに置き換える実験を提案します。例えば、AIがヒトと連携する能力をディベートを使って開発するアプローチとして、ふたつのディベートAIとヒトの審判員から構成されたゲームが考えられます。こうしたゲームは、二人のヒトの討論者と一人のヒトの審判員に置き換えることができます。わたしたちが望んだどんな質問に関してもヒトはディベートすることができるうえに、ヒトのディベートから学んだ教訓は機械学習に移植することができるのです。
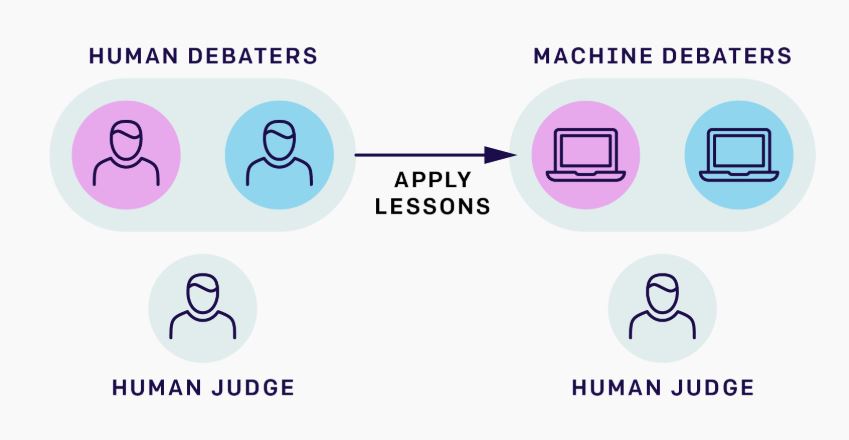
AIとヒトの連携を解明するためにディベートを使うというアプローチをした時、わたしたちの最終目標は機械学習の討論者と人間の審判員というシステムを完成させることにあるが、機械学習は多くの興味深い仕事に対してまだ原始的すぎる。それゆえ、わたしたちは機械学習の討論者をヒトの討論者に置き換え、このヒトだけの状況で討論を最もうまく行う方法について学び、わたしたちが学んだことを後に機械学習とヒトが参加する事例に適用することを提案する。
こうしたヒトだけで構成された実験は機械学習アルゴリズムによって動機付けられますが、機械学習システムが含まれることはなく、実験に参加するヒトが機械学習に関するバックグラウンドを持っていることも必要とされていません。件の実験をヒトがどのように考えるかに関する既存の知識にもとづいて建設的に組み立てるためには、注意深く実験を設計することが求められるでしょう。ほとんどのAIの安全性に関する研究者は機械学習に焦点を当てていますが、機械学習に焦点を当てるだけでは以上の実験を実行するのに十分な環境を満たせるとは考えられません。
AIの安全性に関する実験にはAIに関する工学的知識だけでは十分でないというギャップを埋めるためには、ヒトの認識、行動、倫理、そして厳密な実験を慎重に設計した経験のある社会科学者が必要なのです。というのもわたしたちが答える必要のある問いかけは学際的であり既存の研究とはあまり関係のない類のものであるので、多様な分野の社会科学が解決に役立つと考えられるからです。そうした多様な社会科学には実験心理学、認知科学、経済学、政治学、そして社会心理学が含まれます。神経科学と法学のような隣接する研究分野も含まれるでしょう。
私たちは、社会科学者と機械学習研究者のあいだで密接に協力することが、AIとヒトの連携に関する人間的側面の理解を深めるために必要になると信じています。協力関係を構築する第一歩として、OpenAIの何人かの研究者は、Mariano-Florentino Cuéllar氏、Margaret Levi氏 そしてFederica Carugati氏が率いるスタンフォード大学の行動科学における先端研究センター(Center for Advanced Study in the Behavioral Sciences:略してCASBS)におけるワークショップを組織することを助け、社会科学とAIとヒトの連携に関する問題を議論するために定期的に彼らと会合を開き続けます。わたしたちは、彼らの価値ある洞察と彼らとの会話に参加できることを感謝しております。

スタンフォード大学の行動科学における先端研究センター(Center for Advanced Study in the Behavioral Sciences:CASBS)のロゴ
わたしたちの論文は、AIの安全性に関する社会科学者への呼びかけでもあります。OpenAIではこの研究はまだ始まったばかりで途上にあり、実験を前進させるためにフルタイムで働く社会科学者の採用活動を進めています。もしこの職域で働くことに興味があるならば、ぜひ応募してください!
原文
『AI Safety Needs Social Scientists』
著者
Geoffrey Irving(OpenAI AIセーフティチームメンバー)
Amanda Askell(OpenAI 倫理と政策に関する研究担当)
翻訳
吉本幸記(フリーライター、JDLA Deep Learning for GENERAL 2019 #1取得)
編集
おざけん



























