

日本経済新聞社が主催するカンファレンス「AI/SUM」が東京 丸の内にて2019年4月22日から24日にかけて開催されました。今回は100以上のセッションの中から「〜AIの最大難関 自然言語への挑戦〜」の内容をお伝えします。
このセッションは、国内で先駆けて自然言語処理技術をサービスに活用しているストックマーク株式会社 代表取締役社長の林 達 氏がモデレーターとなり、自然言語処理の研究に精通する3名の方々を交えて自然言語処理の「今と未来」、さらに海外の方々から見た「本質的な自然言語の壁」について話し合われました。
- Jordi Torras 氏
Founder and CEO, Inbenta
- Vijay Daultani 氏
Assistant Manager, Natural Language Processing Team, Rakuten
- 榮藤 稔 氏
大阪大学教授/株式会社みらい翻訳 株式会社コトバデザイン CEO
AIを実現するためには、機械に自然言語を理解させることは避けることのできない道です。この記事を通して、自然言語処理の可能性を感じるだけでなく、課題についてもしっかり把握し、今後の発展についても理解を深めていきましょう。
自然言語への挑戦を行う技術の「今」
まず、林氏より、セッションの初めに自然言語を扱う技術の全体像について語られました。
林 達 氏:自然言語処理技術を活用したものとして、現在「チャットボット」や「機械翻訳」などがビジネストレンドととして挙げられます。しかし、これらの技術は画像処理技術などと比べると未だ発展途上であり、マーケットシェアとしても35%しか占めていません。

林 達 氏(ストックマーク株式会社 代表取締役社長)
言語処理技術がもつさまざまな壁
続いて、自然言語技術の発展において、異なる2つの観点から見た壁について議論されました。
国や地域による言語の壁
1つは、異なる国や地域間で生じる言語の壁です。
Jordi Torras 氏:言語のモデリングは、ある程度のパフォーマンスを実現しており、最低限1つの言語に対して一つのトレーニング手法を適用しています。
言語の壁というのは曖昧なものである。例えばスペイン語といっても、スペインで使われているスペイン語と、メキシコで使われているスペイン語、アルゼンチンで使われているスペイン語などがありますが、これらはすべて異なるものです。

Jordi Torras 氏(Founder and CEO, Inbenta)
Vijay Daultani 氏:言語モデルをサポートするのはとても大事なことです。
では、どのようにしてモデルを作るべきか?そして、複数の言語に対応できるモデルとはどのようなものか?
機械翻訳は、言語によって異なる課題をもつため、言語固有なものが必要になります。現在の自然言語処理技術では、その部分の研究は進んでいません。

Vijay Daultani 氏 (Assistant Manager, Natural Language Processing Team, Rakuten)
榮藤 稔 氏:ビジネスにおいて、どのようにして2つの文化間のギャップを乗り越えるか?
機械翻訳に対する評価を5点満点でつけたとき、3年前は3.5点だったものが1年前では4.5点に上昇しました。これはGoogleによる技術の向上によるものです。つまり、現在は人間の介在がなくても機械翻訳の技術は向上してきています。
10年前に現在何が起こっているのか予測できなかったように、将来何が起こるかを今予測することは難しいといえます。

業界業種の壁
もう1つは、自然言語処理の発展には業界や業種で固有にもつ専門用語に対する壁です。
Jordi Torras 氏:銀行や政府、電力会社など、業界別にも言語があります。
お客様からの問い合わせに対応するカスタマーサポートでは、お客様目線の言葉に合わせる必要があるのです。
しかし、人間の業種というのはきちんと定義されていないため、機械に対して業種ごとの区別を考慮させることは難しいです。
Vijay Daultani 氏:ある特定のタスクについて話している際に使用される語彙は、業種によって完全に異なっています。つまり、別のタスクを違う業界のために行う場合には、使用する言葉が全く異なってしまうのです。
業種別の語彙は、データの生成と表現方法がそれぞれ異なる。現在は、この違いを対処するための良い提案方法がないため、ある特定の業種やドメインに合わせた対処がされています。
本来は、その言語にあった固有のソリューションが必要なはずです。
自然言語処理の日本市場における課題と今後
最後に、現在の自然言語処理技術がもつさまざまな課題を踏まえて、今後期待することについて意見をいただきました。
Vijay Daultani 氏:日本の人たちに、自然言語処理で有益なものを作りたいと思います。この技術を用いて問題を解決し、日本人の生活をよりよく変えられたらいいです。
日本にいる70歳以上の多くの高齢者に対して、自然言語処理を用いて、手助けすることができるはずです。つまり、自然言語処理はこれからの日本において、とても重要な要素となり得ると思います。
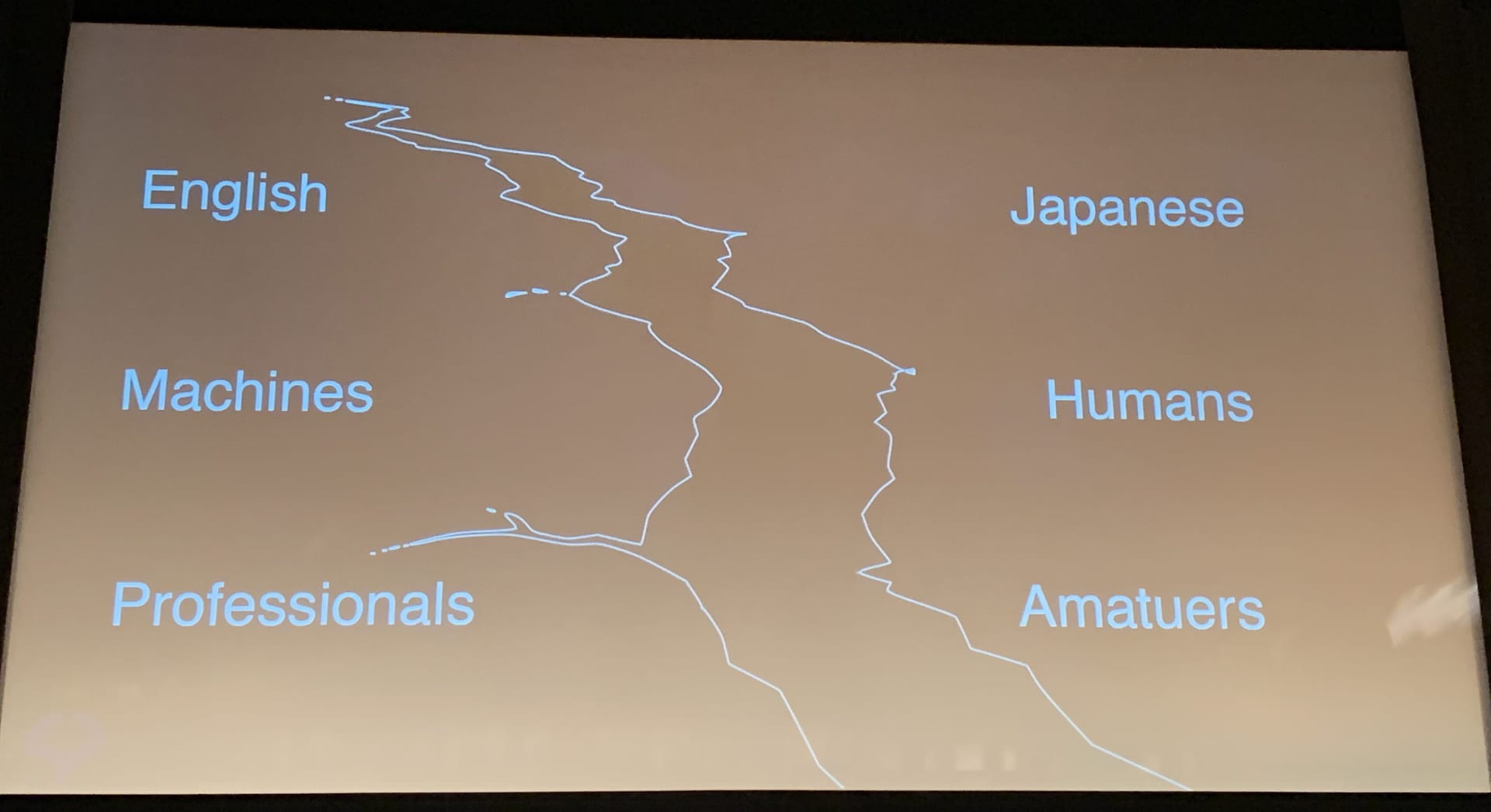
榮藤 稔 氏:大きなギャップが存在しているところにはビジネスチャンスがあります。このギャップを埋めるのが、自然言語処理です。ギャップには、「プロとアマ」「子供と大人」など、さまざまなものがありますが、いかにして大きなギャップを見つけるかが大事なことです。
日本はギャップだらけの国です。今後は、具体的には「機械と人間」や「法律家と犠牲者」といったギャップが埋められていくのではないでしょうか?
おわりに

私たち人間は、当たり前のように自然言語をコミュニケーションの手段として扱っています。
このセッションに参加して、自然言語を扱う人間の処理を機械に実現させるためには多くの課題が残されているということを鮮明に感じました。
そして、課題が多いからこそ、今後、自然言語処理による革命への期待を感じました。
まだ発見されてはいませんが、現在の自然言語処理技術向上の引き金となる有効なアプローチの提案されるのが楽しみです。
AINOWでは自然言語処理技術に関する記事も公開しています。ぜひご覧ください。


AI/SUM関連記事






■AI専門メディア AINOW編集長 ■カメラマン ■Twitterでも発信しています。@ozaken_AI ■AINOWのTwitterもぜひ! @ainow_AI ┃
AIが人間と共存していく社会を作りたい。活用の視点でAIの情報を発信します。



























