

こんにちは、AINOWインターンのゆかわです。
早速ですが、機械学習を勉強し始めたばかりの初級者の方は、機械学習に用いられている手法が多過ぎて、どれを知っておいた方がいいのかわからなくなっていませんか?
また、ある程度勉強を進めてきた中級者の方の場合は、実際に機械学習を使うにあたって、どのようにして手法を選択すれば良いか困っていませんか?
今回はそのような初級者、中級者の方へ向けた記事となっています。
目次
この記事の構成について
①チートシート
この記事ではまず、チートシートと呼ばれる、解決したい課題ごとにどの手法を使えばいいかが一目でわかる表を用意しています。
この表は中級者の方の手法選択の手助けはもちろん、初級者の方にとっても機械学習の手法の概観を捉えるものとして役に立つはずですので、ぜひご活用ください。
②手法選択のコツ
上で述べたチートシートを使って機械学習の手法を選ぶ際の、ポイントを簡単に書いています。こちらもぜひ参考にしてください。
③初級者が知っておくべき機械学習手法8選
初級者の方ならこれさえ知っておけば十分だと思われる手法について、簡単な文章で説明しています。自信のある方はここをざっと読んで、中級者向けのものに進んでいただいても構いません。
④中級者が知っておくべき機械学習手法5選
上級者が実際に使っているような、発展的な手法について解説しています。初級者の方でも、意欲のある方はぜひ読んでみてください。
チートシート
scikit-learn

機械学習のオープンソースライブラリとして、初学者の方にも馴染みのある「scikit-learn」では、機械学習アルゴリズムのチートシートが用意されています。個人・商用を問わず、誰でも無料で使用することが出来るので、機械学習の手法を実際に試してみたい方は、scikit-learnとこのチートシートを活用することで、さまざまな手法を体験することができます。
Azure Machine Learning

機械学習のクラウドプラットフォームとして代表的なAzure Machine Learningの公式ページにもチートシートが公開されています。
Azure Machine Learningに用意されている分類やレコメンド、クラスタリング、異常検出や回帰、テキスト分析などのアルゴリズムを選択する際に、活用することができます。
また、その他にも機械学習のアルゴリズムの選択方法を解説した記事も公開されています。
SAS Institute Japan
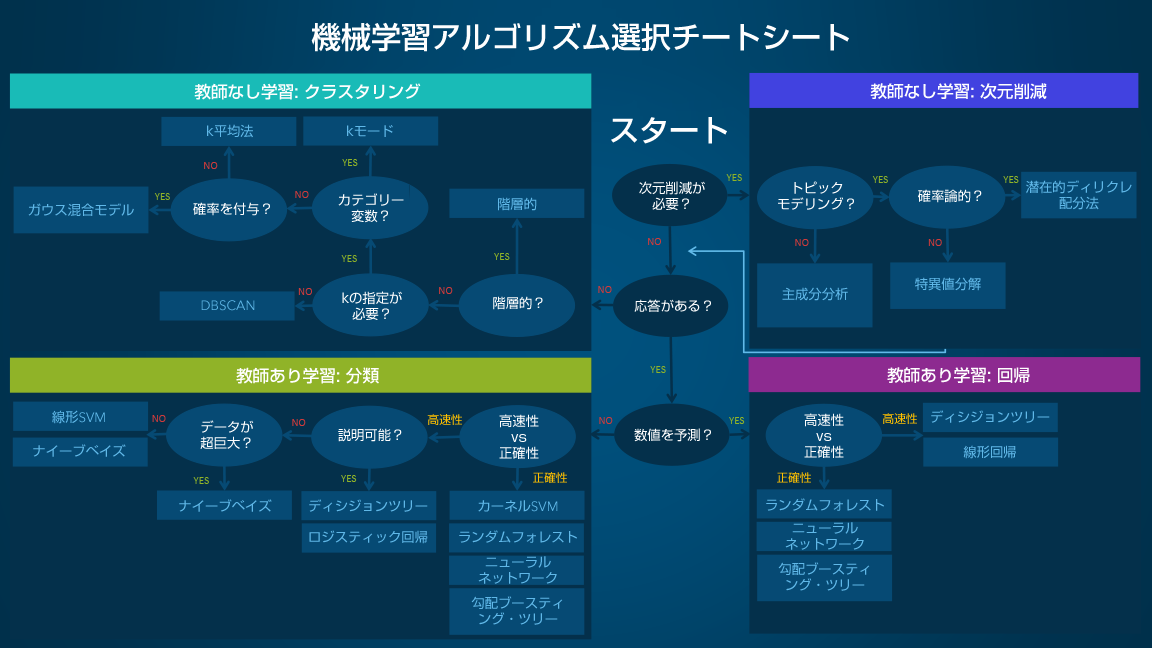
SAS Institute Japanは、同社のブログにて、機械学習アルゴリズム選択チートシートを翻訳・編集し、公開しています。
Yes / No か 高速性/正確性 の2択が用意され、最終的にたどり着いたものが推奨されるアルゴリズムになるわかりやすいデザインになっています。
初心者レベルのデータサイエンティストが対象とされているので、初学者の方はぜひ参考にしてみてください。
[btn]機械学習アルゴリズム選択ガイド手法選択のコツ
まずはじめに大事なことは、与えられたデータがどのような種類であるのか、どのようなタスクを行いたいのかを確認することです。
例えば手元のデータが、どのクラスに属するか分かっていて、未知のデータがどのクラスに分類されるか知りたいなら、上のチートシートに従って、ロジスティック回帰やNN、勾配ブースティング木などが候補になることでしょう。
ここで、候補が複数ある場合、どのモデルが最も良いかを判断するのはそう簡単ではありません。
もちろん上の表を使えば、例えば特徴量が少ないようなデータに対しては、NNのような複雑なモデルを使うと過学習を起こしてしまうので、構造がより単純な、ロジスティック回帰やSVMなどを使ってみようとするでしょう。
しかしながら上の表の評価はあくまでも目安であり、データとの相性によっては必ずしもこの通りでなかったりします。
またそもそも、どの程度の特徴量を持つデータなら複雑なモデルを使わなければいけないのか、などの絶対的な評価基準というものを見つけるのはなかなか難しいです。
結局のところ、タスクによって使うモデルを絞り込んだ後は、絞り込んだ中からある程度の目安に従ってモデルを選び、実際に動かして比較してみるということが一番大事です。
初級者が知っておくべき機械学習手法8選
教師あり学習
線形回帰
目標の値を予測するための式を、線形多項式(y=θ0+θ1×1+θ2×2+θ3×3のような式)を使って表す、非常にシンプルなモデルです。
回帰問題を解く上で最もシンプルなモデルの一つで、そのシンプルさゆえに、実装が簡単かつ学習にかかる時間も短いですが、難しい問題に対しては十分に学習できない恐れがあります。
ロジスティック回帰
名前に回帰とは入っていますが、このモデルが解くのは分類問題です。ややこしいですね。
このモデルは、線形回帰の時に使われたような線形多項式に、ロジスティック関数(もしくはシグモイド関数とも呼ばれます)を適用することで、分類問題を解けるようにしただけのものです。
なので、回帰問題に対して線形回帰モデルがそうであったように、分類問題に対して最も簡単なモデルの一つと言っていいでしょう。
サポートベクターマシン(SVM: Support Vector Machine)
こちらもロジスティック回帰と同様に、分類問題を解くモデルです。
※実はサポートベクターマシンは回帰問題にも使えるのですが、ここでは簡単のために分類問題で説明します
このモデルでは「マージン最大化」がキーワードです。
これはデータをクラスごとに分けるときに、境界とその近くの点との距離がなるべく大きくなるように境界を決めるというものです。
これにより、未知のデータに対しても、精度良く予測ができるようになります(これを汎化性能が高いと言います)。
この後で紹介するランダムフォレストと並んで、昔から人気の手法です。
決定木
決定木とは、ツリー状に条件分岐を繰り返すことによって分類するクラスを予測するモデルです。枝分かれ部分の条件は、データの変数を使って作ります。
こちらもサポートベクターマシン同様、回帰問題に使うこともできます。
ランダムフォレスト
これは決定木を大量に作成し、それぞれの決定木で得られた結果を平均したり多数決をとったりすることで、より汎化性能が高くなっているモデルです。
ここで、それぞれの決定木は似たようなものであっては意味がないので、訓練データを分割してそれぞれの木に別々に割り当てたり、枝分かれ部分で使う変数を木ごとに変えたりすることで、多様な決定木を作ります。
ニューラルネットワーク(NN: Neural Network)
2010年代にAIが注目される火付け役となったディープラーニング技術ですが、人間の脳の神経細胞のつながりを模したニューラルネットワークを多層に重ねることで、高度な画像認識などが可能になっています。まさに、AIのブームが起きた理由となっているのがこのニューラルネットワークです。
ニューラルネットワークの構造は、複数の入力を受け取り、それをもとに出力する「ノード」が、いくつも連なって一つの層を成し、その層がさらに何層にも積み上がることで、複雑な問題に対しても高い精度で予測できるようにするというものです。
層は基本的に、入力層、隠れ層、出力層に分けられます。このうち、隠れ層の層の数を増やす(層を深くする)ことで、より困難な問題が解決できるようになるという事例がいくつも認められていて、これがいわゆるディープラーニングへとつながります。
ナイーブベイズ
この手法はベイズの定理という、統計学では基礎として用いられている有名な定理を使って、それぞれのクラスに分類される確率を計算し最も確率の高いクラスを結果として出力する、分類問題を解くためのモデルです。
計算量が少なく処理が高速であるため、大規模データにも対応できますが、やや精度が低いといった問題があります。
スパムフィルターなどの、テキスト分類のタスクで使われることが多いです。
教師なし学習
k-means
クラスタリングという、与えられたデータを似たもの同士でグループ(クラスタ)に分けるときに使われる手法です。
仕組みとしてはまず、指定された分類数に基づいて適当に各データにクラスタを割り当てます。
その後、それぞれのクラスタで重心の位置を計算します。
するとデータによっては、元々指定されていたクラスタよりも、他のクラスタの重心の位置の方が近い、ということが起こります。
そのようなデータは重心が近い方のクラスタを割り当てなおし、また重心を計算して〜…を繰り返すと、最終的に距離の近いデータ同士が同じグループに分けられるようになります。
主成分分析(PCA: Principal Component Analysis)
機械学習を行う上で、データに与えられた特徴量が多すぎると、過学習を起こしてしまったり、学習時間が長くなってしまうなどの問題があります。
そこで、不必要な特徴量を減らし、より少ない特徴量で予測できるようにする、次元削減というものが必要になります(次元とはデータの特徴量の数のこと)。
次元削減をすると、元々のデータが持っていた情報はある程度失われてしまいますが、主成分分析hそうした損失を抑えるために、特徴量の分散などを使って計算します。
中級者が知っておくべき機械学習手法5選
決定木の進化系(アンサンブル学習)
決定木とは初級編でも説明した通り、条件分岐を繰り返して予測するツリー上のモデルでしたが、このモデルの精度を高める方法に、アンサンブル学習というものがあります。
アンサンブル学習とはモデルを複数用意して、各モデルの出力をまとめることで、より良い予測をさせようというものです。
実は初級編でも触れたランダムフォレストは、このアンサンブル学習のうちの一つ、バギングという手法を使っています。
アンサンブル学習には他にもブースティングやスタッキングといった手法があり、ここではその二つについて説明していきます。
ブースティング
近年ランダムフォレストを超える人気を見せており、kaggleなどのデータ分析コンペでの上位入賞者にもよく使われているのが、LightGBMやXGBoostといったブースティングを使ったモデルです。
ハイパーパラメータの調節や過学習対策の難しさはありますが、NNなどと並んで現在最も強力な手法の一つと言っていいでしょう。
ランダムフォレストが使っているバギングという手法との違いは、バギングがモデルを独立に増やしていくのに対し、ブースティングは逐次的にモデルを増やす(あるモデルが間違えた問題に対して正解しているモデルを追加していくなど、前のモデルの結果を受けて次に足し合わせるモデルを決める)という点です。
これによって、バギングよりも高い精度を得られるようになりました。
ただし、モデルの数を増やすと汎化性能が高まるバギングと違い、ブースティングの場合はモデルを増やしすぎてしまうと過学習に陥ってしまうので、どこまで増やすかには注意する必要があります。
また、ブースティングはバギングと違って並列処理ができないので、時間も多くかかってしまいます。
スタッキング
こちらもブースティング同様、Kaggleの上位入賞者などに愛用される強力な手法となっていますが、ブースティングかスタッキングのどちらかを選択して使うというものではなく、同時に用いられることが多いモデルです。
というのも、スタッキングとは複数のモデルを積み上げる手法で、どの積み上げるモデルの一つにLightGBMやNNなどが用いることで、高い精度を出すことができるのです。
仕組みとしては、まず一層目にいくつかのモデルを用意し、それぞれのモデルからの出力を、次の層(これもまた選ばれたいくつかのモデルからなります)への入力として用い、その出力をまた次の層への入力とし〜…を繰り返すことで、最終的な予測値を得るというものです。
過学習などに気をつけながら、どのモデルをどの層に使うかなどを考えなければならず、非常に難しい手法となっていますが、その分とても強力です。
NNの進化系
ディープラーニングが注目されるのに伴い、ニューラルネットワークもタスクやデータの形ごとに特化したモデルが様々提案されてきました。
今回はその中でも基本的な、CNN、RNN、GANについて触れていきたいと思います。
CNN(Convolutional Neural Network)
CNNは、画像関連のタスクにおいて非常に効果的なモデルです。
例えばあの有名な、Googleが猫の画像をコンピュータに見せて猫の画像を認識させた、というのもこのCNNのモデルが使われました。
CNNの大きな特徴は、畳み込み層とプーリング層です。これらの層がどういった操作を行なっているかということについては割愛します(興味がある人はオライリーの「ゼロから作るDeep Learning」を読んでみてください)が、これらの層を何層にも重ねていくことで、入力画像からより抽象的な情報を抽出することができるようになり、そうして抽出された情報をもとに、複雑なタスクに対しても、高いパフォーマンスを出しています。
RNN(Recurrent Neural Network)
RNNは、時系列データの解析や自然言語処理といったタスクにおいて効果的なモデルです。
時系列データとは、例えば株価のように、時間の経過とともに値が変化するようなデータのことを指します。
一方で自然言語処理とは、私たちが普段使う言葉に関するもので、文章の意味を理解したり、ある言語から違う言語へ翻訳したりといったことを目的にします。
ここで時系列データにとって、ある時刻の情報とそれ以前の時刻の情報の関係が重要であるように、自然言語にとっても、文章中のある言葉とその前の言葉の関係(例えば主語の後には動詞が来るとか)が重要になります。
RNNはそのような過去の情報も考慮した計算ができるので、上で述べたようなタスクに対して有効となっています。
GAN(Generative Adversarial Networks)
これは今までにご紹介した手法とは異なり、入力されたデータから新しいデータを作り出して出力する、生成モデルと呼ばれるモデルの一つです。
本当はもっと詳しい数学的理論がありますが、簡単に仕組みを説明すると、GANは生成器と識別器という二つの部分からなります。
生成器はより本物に近いデータを作ることを、識別器はそれが本物かどうかをより正確に見分けることを目的にし、お互いに学習していきます。結果として、よりリアルなデータを生成できるようになるのです。
一時期世間を騒がせたDeepFakeも、このGANを使っていたように、GANをめぐっては現在様々な研究が行われています。今後もGANを用いて、さまざまなことが実現されていくでしょう。
おわりに
この記事では紹介できてない手法も多々あります(特に教師なし学習などに関しては、教師あり学習ほどの人気はないことを考え、基本的なもの以外は割愛しました)が、初級者中級者の人ならばこれさえ知っておけば十分だろう、というものを大方網羅しました。
皆さんの今後の学習の助けになれば幸いです。
今回は様々な手法をご紹介するということが一番の目的だったので、詳しいところまでは触れていませんが、実際にモデルの原理となっている数式やアルゴリズムを知り、腹落ちさせれば、より深い理解が得られるはずです。
もし余裕があれば、理解できそうな簡単なモデルからでもいいので、ぜひ詳しい仕組みを調べてみてください。



























