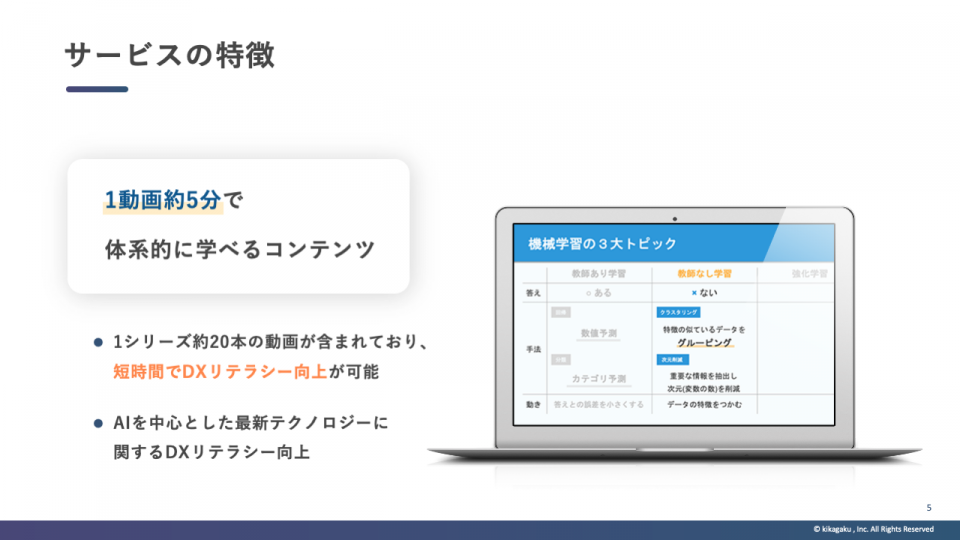
機械学習エンジニアのSayak Paul氏が行ったコンピュータビジョンに関する講演に感銘を受けたNeo氏は、この講演で語られたコンピュータビジョンにおける5つのトレンドをまとめた記事を公開しました。そうしたトレンドとは、以下の通りです。
- 高効率なAIモデル:AIモデルのサイズを抑制しながら、性能を劣化させない画像認識モデル開発。
- クリエイティブな生成系ディープラーニング:顔写真からアニメキャラを生成するようなクリエイティブな現場での応用が期待されるディープラーニングモデル開発。
- 自己教師あり学習:ラベルのない学習データで訓練する画像認識モデル開発。
- Transformerを活用した画像認識:CNNの代わりにTransformerを活用する画像認識モデル開発。
- 堅牢な画像認識:さまざまな脆弱性に対処した画像認識モデル開発。
以上の5つのトレンドは、AI技術全般における今後の課題をまとめたAINOW翻訳記事『人工知能を次のステージに導く5つのディープラーニングのトレンド』およびAINOW記事『NEDOが「人工知能(AI)技術分野における大局的な研究開発のアクションプラン」を公表』と一部内容が重複しています。これらの記事も閲覧することで、AI技術が克服すべき課題がより幅広く理解できることでしょう。
なお、以下の記事本文はBenedict Neo氏に直接コンタクトをとり、翻訳許可を頂いたうえで翻訳したものです。また、翻訳記事の内容は同氏の見解であり、特定の国や地域ならびに組織や団体を代表するものではなく、翻訳者およびAINOW編集部の主義主張を表明したものでもありません。

目次
機械学習エンジニアのSayak Paul氏によるコンピュータビジョンのキートレンドの紹介
コンピュータビジョンは、現実世界で膨大な価値のある人工知能の魅力的な分野だ。この分野では10億ドル規模のスタートアップ企業が続々と登場しており、Forbes誌は同市場が2022年までに490億ドル(約5兆4,000億円)規模に達すると予想している。
コンピュータビジョンの目標
コンピュータビジョンの主な目標は、コンピュータに視覚を通して世界を理解する能力を与え、その理解に基づいて判断を下すことにある。
この技術を応用することで、人間の視覚を自動化したり、拡張したりすることができ、その結果として無数のユースケースが生まれる。
AIがコンピュータの思考を可能にするならば、コンピュータビジョンはコンピュータの視覚、観察、理解を可能とする。- IBM
使用例
コンピュータビジョンの使用例は、運輸から小売店まで多岐にわたる。
運輸での典型的な使用例は、Tesla社で見られる。同社は、コンピュータビジョンモデルで駆動するカメラだけを頼りに電気駆動の自動運転車を製造している。
また、スマートセンサーとコンピュータビジョンシステムを使ってレジなしで買い物ができる「Amazon Go」プログラムのようなものが現れたことで、コンピュータビジョンが小売業界に革命をもたらし、利便性をさらに高めている。
コンピュータビジョンは実用的なアプリケーションに貢献するという点で、明らかに多くの可能性を秘めている。実務者として、あるいはディープラーニングの愛好者として、この分野の最新の進歩に目を向け、最新のトレンドを把握することは重要だ。
コンピュータビジョンのトレンド
この記事では、Cartedの機械学習エンジニアであり、最近Bitgritで講演を行ったSayak Paul氏の考えを共有する(※訳註1)。彼については、LinkedInとTwitterでも見つけられる。
この記事は、講演のすべてを網羅しているわけではなく、あくまで講演の要約あるいは要点を提供するものだ。講演のスライドはこちらで閲覧できる。スライドには内容が類似しているトピックに関連する有用なリンクが付いている。また、この講演はYouTubeでも公開されており、それからより詳細な情報が得られる。
この記事の目的は、彼の講演と同様に、以下のようにして読者諸氏の役に立つことにある。
- これから取り組むべき、よりエキサイティングなことを発見する。
- あなたの次のプロジェクトのアイデアをインスパイアする。
- 現場で起こっている最先端のことをキャッチアップする。
・・・
トレンドを紹介する前に、まだ知らない読者もいると思われる、3,000ドル💵の賞金がかかった新しいデータサイエンスのコンペティションが発表された。
⭐バイラルツイート予測チャレンジ⭐
データサイエンスのスキルを磨くには絶好の機会だ。
大会は2021年7月6日に終了するので、今すぐ登録して腕試しをしてみよう!
では、コンピュータビジョンのトレンドを見ていこう。
・・・
トレンドI:リソース効率化モデル
トレンドになる理由
- 最新のモデルは、携帯電話やRaspberry Piなどマイクロプロセッサーが搭載された小さなデバイスを使ってオフラインで実行することが非常に難しい場合がある。
- 重いモデルはレイテンシー(ここでいうレイテンシーとは、1つのモデルがフォワードパスを実行するのにかかる時間のこと)が大きくなる傾向があり、インフラコストに大きく影響する(※訳註2)。
- (コスト、ネットワーク接続性、プライバシーへの懸念などにより)クラウドベースのモデルのホスティングが選択肢にない場合、使えるモデルはどのようなものか。
構築プロセス
1.スパース・トレーニング
- スパース・トレーニングとは、ニューラルネットワークの学習に使用する行列にゼロを導入することである。これができるのは、すべての次元が他の次元と相互作用しているわけではなく、言い換えれば(ある特定の次元が特に)重要だからだ。
- パフォーマンスは落ちるかも知れないが、結果的には乗算回数が大幅に減り、ネットワークの学習時間が短縮される。
- 非常に関連性の高い技術として、ある閾値を下回ったネットワークパラメータを破棄するプルーニングがある(閾値のほかにも破棄する基準がある)。
2.トレーニング後の推論
- Deep Learningで量子化を使い、モデルの精度を(FP16からINT8に)下げてサイズを小さくする(※訳註3)。
- 量子化認識トレーニング(Quantization-Aware Training:QAT)では、精度を下げることによる情報の損失を補える(※訳註4)。
- プルーニング+量子化は、多くのユースケースで最高の効果を発揮する。
3.知識蒸留
- パフォーマンスの高い教師モデルを訓練し、その「知識」を抽出して、教師から得られたラベルと一致するように別の小さな生徒モデルを訓練する。
モデル実装までの行動計画
- より大きく、高パフォーマンスの教師モデルを育成する。
- 知識蒸留を行い、できればQATを使用する。
- 知識蒸留したモデルをプルーニングし、量子化する。
- 実装する
・・・
トレンドII:クリエイティブなアプリケーションのための生成系ディープラーニング
トレンドとなる理由
- 生成系ディープラーニングは、本当に進歩している。
- thisxdoesnotexist.comには、生成系ディープラーニングで実現できる事例が掲載されている(※訳註5)。
アプリケーション
1.画像の超解像
- 監視カメラなどの用途に合わせて画像(の解像度)をアップスケールできる。
2.ドメイン転移
- 画像を別のドメインに転移する
- 例:人間が写った画像を漫画化する、あるいはアニメ化する
3.外挿
- 画像中のマスクされた領域に対して新規のコンテクストを生成する。
- 画像編集などのドメインで使用され、Photoshopアプリに見られる機能をシミュレートする。
4.暗黙的なニューラル表現とCLIP
- キャプションから画像を生成する機能(例:「ニューヨークの街で自転車に乗る人間」というテキストからその内容の画像を生成する)
- GitHubレポジトリ
![]()
画像出典:deep-dazeのGitHubレポジトリ
モデル実装までの行動計画
- 以上のような製品を研究し、実行してみる。このステップは省略しても構わない。
- エンド・ツー・エンドのプロジェクトを開発する。
- 生成系ディープラーニングで使われている要素を改良してみると、もしかしたら何か新しい発見があるかも知れない。
・・・
トレンドIII:自己教師あり学習
自己教師あり学習では、グランドトゥルースのラベルを一切使用せず、代わりにプリテキストタスクを使用する。そして、ラベルのない大量のデータセットを使って、モデルにデータセットを学習させる(※訳註7)。
自己教師あり学習を教師あり学習と比較すると、どうなるだろうか。
教師あり学習の限界
- パフォーマンスを上げるためには、膨大な量のラベル付きデータが必要。
- ラベル付きのデータは準備にコストがかかるうえに、偏りが生じる可能性もある。
- このような大規模なデータの場合、トレーニングの時間は非常に長くなる。
ラベルなしデータでの学習
- 同じ画像の異なるビュー(見え方)に対してモデルが不変であることを求める。
- 直感的に言えば、このモデルは2つの画像(例えば猫と山)を視覚的に異なるものにするための内容を学習する。
- ラベルのないデータセットを用意した方が、はるかに安上がりだ!
- コンピュータビジョンの分野では、SEER (self-supervised model ) は、オブジェクト検出やセマンティックセグメンテーションにおいて、教師あり学習のモデルよりも優れた性能を発揮する(※訳註8)。
自己教師あり学習の難点
- 自己教師あり学習は、画像分類のような実世界のタスクでうまく機能するためには、非常に大きなデータ領域が必要。
- 対照的な自己教師あり学習は、やはり計算量が多い。
参考文献
・・・
トレンドIV:TransformerとSelf-Attentionの活用
トレンドとなる理由
- Attentionは、対となるエンティティの相互作用を定量化することで、ネットワークがデータ内の重要なコンテクストを揃えることを学習する。
- Attetionというアイデアは、コンピュータビジョンでは様々な形で存在する。GCブロック、SEネットワークなど。しかし、その成果はわずかなものであった。
- Self-Attentionブロックは、Transformerの土台となる。
Transformerを活用する長所と短所
長所
- 事前的帰納性(※訳註10)が低いため、さまざまな学習タスクのための一般的な計算プリミティブと捉えられる。
- パラメータの効率化により、CNNと同等の性能を得られる。
短所
- TransformerはCNNのように明確な事前的帰納性を持たないため、大規模データの組成が事前学習の際に最も重要となる。
もう1つのトレンドは、self-attentionをCNNと組み合わせると、強いベースラインを確立することである(BoTNet)。
Vision Transformerの探求
- Facebook Research/deit
- Google Research/vision transformer(※訳註11)
- Jeonworld/Vit-pytorch
- Vision Transformerを使った画像分類(Keras)
・・・
トレンドV:堅牢なビジョンモデル
ビジョンモデルは、その性能に影響を与える多くの脆弱性に晒されている。
ビジョンモデルが直面する問題
1.摂動
- ディープモデルは、入力データのわずかな変化にも脆い。
- (摂動に起因する誤認のせいで)歩行者が誰もいない道路と予測された場合を想像してみよう!
2.破損
- ディープモデルは、高周波領域(※訳註13)に容易に固定されてしまうため、ブラー、コントラスト、ズームなどの一般的な破損に対して脆い。
3.分布外(Out of Distribution)データ
分布外データには、以下のような2種類がある。
- ドメインシフトしてもラベルはそのまま – モデルには、学習内容に応じて一貫した性能を発揮することが望まれる。
- 例外的なデータポイント – 例外的データポイントに直面した時には、モデルには(例外的なデータに応じて)低信頼度な予測が望まれる。
堅牢にするには
堅牢なビジョンモデルを構築するために、以上のような特定の問題を扱う多くの技術がある。
1.摂動
- 敵対的訓練:ビザンチンフォールトトレランス性に類似しており、基本的には絶対的な最悪の条件に直面したときに、システムが自分自身を処理できるように準備する。
- 論文
)とは、分散コンピューティングにおいて生じる故障を許容するアルゴリズムのこと。代表的なBFTの実用例として、ブロックチェーンがある。
引用された論文「敵対的な事例が画像認識を改善する」では、学習データにあえて敵対的なデータを加えることで画像認識モデルの性能を向上できることが論じられている。この論文がBFTに似ていると言われるのは、BFTでは故障という敵対的な現象を許容するからである。
2.破損
- 整合的正則化 – ノイズの多い入力に対してモデルが整合性を持つようにしたい。
- 整合的正則化を実装した事例:RandAugment、Noisy Student Training、FixMatch
- RandAugment:モデルやデータセットのサイズに合わせて正則化の強度を調整。
- Noisy Student Training:知識蒸留実行時にノイズを加えることで、生徒モデルの汎化を向上させる。
- FixMatch:一貫性のある正則化(consistency regularization)と疑似ラベル付けを活用して半教師あり学習(Semi-supervised learning)を実行。
3.分布外データ
- 例外的なデータポイントをすぐに検出。
- 論文(※訳註16)
堅牢なモデルに関する原理について、George Box(※訳註17)の有名な名言をもじって作った気の利いた名言を引用したい。
「すべてのモデルは間違っているが、間違っていることを知っている一部のモデルは有用である」- Balaji Lakshminarayanan(※訳註18)(NeurIPS 2020)
・・・
以上で今回の記事を終える。お読み頂きありがとうございました!この記事をお読みになって、何か新しいことを学んで頂ければ幸いです。このような記事がお好きな方は、ぜひBitgrit Data Science Publicationをフォローしてください。
・・・
📱 Bitgrit’s socialsをフォローして最新情報をゲットしよう!
Twitter
LinkedIn
Instagram
Facebook
YouTubeチャンネル
Telegramコミュニティ!
原文
『5 Computer Vision Trends for 2021』
著者
Benedict Neo
翻訳
吉本幸記(フリーライター、JDLA Deep Learning for GENERAL 2019 #1取得)
編集
おざけん