

2021年7月、LINE株式会社は世界初の日本語に特化した大規模汎用言語モデルを「HyperCLOVA」として発表しました。
近年、英語圏を中心に大規模な言語モデルの開発が積極的に行われています。この波は日本語圏にも及んでおり、LINEは2020年11月25日にいちはやく大規模汎用言語モデルの開発を発表しました。
2022年1月現在、パラメータ数が67億、130億、390億の3つのモデルが発表されており、820億モデルの開発が進んでいます。
今回は、LINE株式会社のNLP開発チームマネージャー佐藤敏紀氏に「HyperCLOVA」の開発の裏側に関してインタビューしました。
目次
HyperCLOVAとはなにか
まずは、HyperCLOVAについて概要をおさらいしておきましょう。
HyperCLOVAは、LINE株式会社とNAVER株式会社が共同で開発した世界初の日本語に特化した大規模汎用言語モデルです。
膨大なデータを学習させたモデルにより、少量の言語をインプットすることで、文脈にあった言語処理を可能にしたり、エージェントと人間の自然な対話が可能になります。
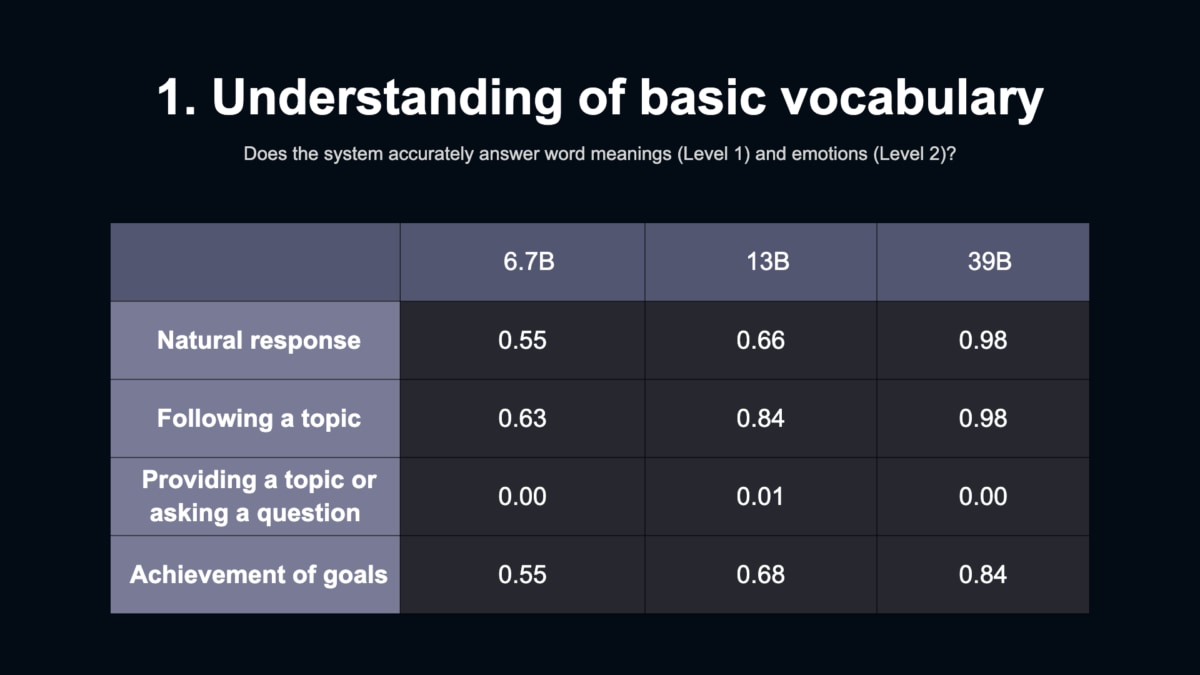
現在はパラメータ数が67億、130億、390億の3つのモデルがあり、390億モデルでは、会話の滑らかさ、そしてトピックの追従度は98パーセントの性能を誇っています。
提供:LINE株式会社
AINOWでは、LINE株式会社のAI事業に関してまとめた記事も公開しています。あわせてご覧ください。

ブログデータが対話精度向上に|HyperCLOVAの開発の裏側
ーー日本語圏では前例も少ない大規模汎用言語モデルを開発する上で苦労した点はありましたか?
英語や韓国語のノウハウが日本語のモデルに直接使えないところが大変でした。
モデルの構築は、67億、130億、390億とパラメータを小さいサイズから順番に積み上げています。130億の時、精度がガクンと落ちてしまったんですが、データを整えるなどの試行錯誤をしていくと390億の時に突き抜けて高くなったんですね。
このように、宝探しやハッカソンのように実際に試してみないとわからないことがとても多く、そのうえ、1回の試行錯誤に2週間〜1ヶ月必要だったのが大変でした。
またコーパス作りも大変でした。モデルを学習させるデータは基本的には権利関係を明確にしながら、法律面だけでなく感情面的なところにも深く配慮してコーパスを作りました。

ーー学習させたデータの中で1番比重の重いデータはどのようなものでしたか。
390億モデルですと、ブログのデータを1番多く学習させました。
ブログのデータでも対話の精度向上につながることが意外でした。
HyperCLOVAを使った対話システムを人工知能学会 言語・音声理解と対話処理研究会主催の対話システムライブコンペティションに出させていただいて、「ペルソナ一貫性の考慮と知識ベースを統合した雑談対話システム」がオープン/シュチュエーションの両方のトラックで1位という良い成績を残すことができました。
その時、他社様は言語モデルに対してTwitterのデータをたくさん入れられていました。他方で、私たちのモデルはTwitterのデータをほとんど入れずに戦ってみたのですが、対話システムとしてHyperCLOVAを使ったシステムの方が性能が評価されたんです。
今回のコンペティションの様な評価を行う対話システムを作る際に必要な要素として、対話データ以外のデータの方がより必要とされていたのかもしれません。
ブログやニュースの方がしっかりとしたインタビュー記事が入っており、会話として成り立ちやすい文がたくさん含まれているのかもしれないですね。
今構築中の820億モデルになると、基本的にログインを必要としない日本のWebサイトや、390億モデルを構築した後に許諾を頂いたデータをお持ちの企業様からお借りしているデータを利用させて頂いてます。
HyperCLOVAがもたらす社会的インパクト|倫理とビジネスの両面性
ーーHyperCLOVAのようなモデル社会にも大きなインパクトを与えると思います。社内のビジネス開発メンバーとはどのように議論されましたか?
LINEのビジネスサイドのメンバーと話すだけでなく、他社様とPoC、技術開発目的のトライアルの意味で契約させていただいて、一緒に技術を作ることにチャレンジしています。
また、同じZホールディングス配下の別の会社とは、より踏み込んだ技術開発ができないかと話が進んでいます。
ただ、どの会社様も現実に今、直面している課題があって、その課題をHyperCLOVAを使用することで改善できないかという発想からスタートされることが多いです。
ここで問題なのが、大規模で汎用的な言語モデルを使いこなせる人材がたくさんはいないということです。そのため、実際にHyperCLOVAは何ができるのか、ということを各社様だけでは把握できないという問題があります。
昔、検索エンジンが出てきた時、検索エンジンはなんでも知っているからなんでも答えてくれるはず、みたいに思っている人がいた時期があったと思うんですが、それの言語モデル版が今起こっているんだと思います。
ーー 大規模な言語モデルとなると、倫理の問題なども深く議論しなくてはいけません。倫理面はどのようにカバーしていますか?
AI倫理を実装する時、AI倫理そのものをシステムが持ち、倫理を体現するみたいなシステムを作ることは難易度が高いのが現状です。今は、アウトプットやインプットが適正かどうかを検査するための、フィルターの開発を進めています。
1番最初のコアの部分はルールベースでスタートするんですが、どこまで作っていくのか問題が大変です。
例えば、同じ単語でもドメインが違うだけで意味が変わってしまう場合があります。そのため、どのドメインにはどの情報を入れないかなど、目的によって違ってしまうところが大変だったりします。
もう1つ違う話で、言葉の掛かり方によっては、全く無害な単語でも組み合わさるとおかしくなる場合があります。
例えば、「もやし」「ごぼう」は全く問題ない単語ですが、「もやしっ子」「ごぼうのような男」になると貧弱そうな男性を比喩する言葉になってしまいます。人間は複雑に言葉を発しますのでいろんな言葉の掛け方ができます。
この掛かり方によっては、とある倫理観を満たないような表現になってしまうケースなどがあるので大変です。
次のステップでさらに広い範囲の倫理的な条件を満たしていこうと考えています。
ーーHyperCLOVAを実際に開発してみて、どのように社会にインパクトを与えると考えていますか。
HyperCLOVAのような大規模汎用言語モデルを活用する場合、個別の全くバラバラなリクエストをうまく処理するより、長いスパンでたくさんの人に使ってもらえるような、知的データを作るためのお手伝いをする方が効果的だと考えています。。
人間にとって、データをたくさん作ったり、作り続けたりする作業はつらいです。HyperCLOVAにそれらの作業を手伝ってもらうと、人間には把握しきれない規模のテキストデータから作ったモデルを基にして、さまざまな課題に対する答えの候補を生成してくれます。
例えば、一般的なクイズの正解率を軽くベンチマークしたところ、約70%程度を達成することがわかっています。ということは、HyperCLOVAをクイズの回答の生成に利用した場合は、人間は30%程度の正解することができなかった問題だけに集中できます。具体的には、人間がわかる範囲で間違った回答が出ている事例を取り除いたり、新しい方向性で回答が可能である事例を深く調べたりなど、効率よく取り組むことができます。このように、より深い課題の解決に集中することで、行き詰まっていた課題を改善し前に進めることが可能になると思います。
また、データオーグメンテーションにも活用できます。ビジネス活用の1番最初のところで、データが全く無いところから新たなモデル構築体制を早く立ち上げたい時にはHyperCLOVAは有益だと思います。多少間違っているとしても新たなデータを大量に作れる点は便利だと思います。
これに加えて、テキストの生成、要約でも活躍すると思います。
例えば、説明文を要約してキャッチフレーズを生成したり、座談会の議事録を要約して3行程度でまとめるなど、いろんなパターンがあると思います。
人間が読んだら読めないような雑然としたテキストを適切なアウトプットをすることによって人間が読みやすいテキストかつ特定の方向性でまとめることもできると思います。

これからのHyperCLOVA|マルチモーダルも鍵に
ーー日本国内でも自然言語処理分野が盛り上がってきていますよね。
各社すごく苦労されているだろうと感じていますし、きっと私たちと全く同じ苦労をされている気がしています。
できるものなら一緒に悩みたいなと思いますが、ビジネス的には難しいと思います。
なので、HyperCLOVA以外で問題なく公開できるモデルに関しては、オープンソースにしていこうと動いています。
もちろんLINEが社内で利用しているモデルとオープンソースにするモデルとで性能に差はありますが、皆様が自由にご利用いただけるモデルが増えることによって、不可能であったことが可能になるのではないかと考えています。
皆様のお手元の実装やサービスが、今までよりも高い性能を発揮できるようなモデルを定期的に公開していきたいです。
ーー今後のHyperCLOVAの展望を教えてください。
モデルのサイズや性能は、今後も大規模化していく方向で進むと思います。
一方、最近のトレンドではDeepMindが発表したRETROなど「モデル自体は小さくても良い」という方向性も示されています。他方でもう1つわかっていることは、小さいモデルに性能を出させるためには、手元に巨大なデータがないと駄目ということもわかっています。
そこで2022年は2021年よりも力を入れてデータ集めやデータ作りをしっかりやっていこうと考えています。
マルチモーダルの方向性では、画像生成はすごくキャッチーだと思いますが、僕たちは逆に画像からテキストを作っていきたいニーズの方が大きいです。これに関しては「昔からあるじゃないか」と仰られる方もいると思いますが、昔からあるキャプション作りはすごく曖昧なものが多いんですよね。
キャプション作りもLINEのNLP開発チームが研究開発を担当していますが。解像度がすごく高く、そのまま人間に聞かせた時に、知り合いの人から話を聞いている気分になるぐらい滑らかなキャプションが作れてほしいなと思ってます。

さいごに
人間の知能は、さまざまな知覚から得られた情報を言語能力に結びつけて生まれていると言われています。言い換えれば、自然言語処理技術の発展がなければ、さまざまな知覚情報を結びつけ、汎用的に活用できるAIは生まれません。
自然言語は私たちの生活や仕事に不可欠な存在であり、これをシステムが人間と同等の扱いができるのかが技術発展において重要です。
しかし、言葉の意味の問題だけでなく法律面や倫理面の懸念点があり、今後、多角的な議論の中で汎用言語モデルのありかたを見定めていくことが重要でしょう。
AINOWでは、自然言語処理技術をビジネスサイドでもわかりやすく図解で解説したり、AIと倫理の分野の権威である東京大学未来ビジョン研究センター准教授の江間 有沙氏へのインタビューなども公開しています。


ぜひ、この記事をきっかけにAIの未来について考えてみてください。
AINOWライター。
大学ではHuman-Agent-Interactionや組織運営について学んでいる。



























