

機械学習を学ぶ上で、統計学は切っても切り離せない存在であると同時に、内容が似ていることか境目のわからないものとされています。
では、重回帰分析は本当に機械学習手法でしょうか?
機械学習的手法と統計学的手法の目的をハッキリとさせることで、うまく使い分けていきましょう!
本記事では、機械学習と統計学の違い、統計学の必要性、おすすめ書籍を紹介しています。
目次
機械学習と統計学(統計解析)の違い
機械学習と統計学には、はっきりとした違いがあります。
文字通りに捉えると、「機械学習」は、機械が自動的に学習するものであるのに対し、「統計学」は、データのルールやパターンを統計的に判断するものだと言えます。
ここでいう“統計的に”とは、確率的に正しいかどうかを判断するという意味です。
▼AIについて詳しく知りたい方はこちら

▼強化学習について詳しく知りたい方はこちら

統計学とは
私たちの周りには多くのデータが存在し、さまざまなデータを得ることができます。
しかしながらデータそのものは理解しにくいものであり、単純なデータから有益な情報を得ることはできません。
統計学とは、データに対してその性質を調べたり、母集団から抽出した標本を調べることで母集団の性質を推定する処理や分析の統計的方法を研究する学問のことです。
▶関連記事|AIのための数学について解説|3つの学習方法や学習ステップも紹介!>>
統計学は3つに分類される
統計学は3つに分類されます。
以上の3つについてそれぞれ解説していきます。
①記述統計学
まずは記述統計学について解説していきます。
記述統計学は、統計の手法の一つで、データの傾向や性質を把握するために使われる手法です。具体的には、データの平均や分散を計算し、傾向を掴むといったことを行います。
しかし、どのように傾向をつかむのでしょうか?
ただデータの平均や分散を計算するだけではできません。
そこで傾向をつかむために、計算したデータのグラフ化を行います。
記述統計学の例として、テストの平均点や、平均年齢、平均身長などが挙げられます。
上記にある通り、これらのデータの傾向をつかむためにはある基準がなければいけません。身長や年齢のデータを並べただけでは、わかりづらく比較をすることができません。そこで基準となっているのが「平均値」です。
平均があることで、データ同士を比較することが簡単になります。そして、比較したものをグラフ化することにより「目で見てわかる」状態にすることができます。
記述統計学とは、「複雑なデータをわかりやすくする」ということです。
②推計統計学
次に推計統計学について解説します。
推計統計学は、母集団から抽出した標本によって母集団全体の特徴を推測する学問です。
母集団が大きい場合に、全体を調査することは費用や時間が掛かります。
そこで、母集団から抽出した標本を元に、母集団の特徴を推測します。
代表的な推計統計学の例としては、テレビの視聴率や不良品予測などが挙げられます。
テレビの視聴率を求める場合に、日本全国の全世帯からデータを収集するのは困難であり、非効率です。
一部を抽出し全体(母集団)を推定するのが推計統計なのです。
③ベイズ統計学
最後にベイズ統計学について解説していきます。
ベイズ統計学は、推計統計の一種で、記述統計と推計統計と違い必ずしも標本を必要としません。そのためベイズ統計学では主観確率を扱います。
確率には客観確率と主観確率の2つがあります。
客観確率は、人によって答えの変わらない確率です。
サイコロを振って1が出る確率は、1/6です。これは誰が言っても変化することない確率であるため、客観確率だと言えます。
一方で、主観確率は人によって答えの変わる確率のことです。
例えば、Aさんという人が犬を飼っている確率はどのようになるでしょうか。
このような確率は、客観的に判断することができず、1/3や1/10など主観的な確率になります。
これが主観確率で主観確率を扱うのがベイズ統計学です。
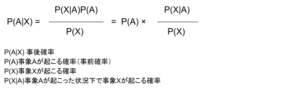
先ほどのようにデータ不十分であっても、設定した確率は事前確率といいます。
また、新たな情報が得られるたびに確率を更新していき、設定した場合を事後確率といいます。
新たに情報を得たことで、確率を更新していくことをベイズ更新といいます。
本来発生し得る確率を導き出していきます。
ベイズの定理(Bayes’ theorem)
出典:AINOW編集部
なぜ機械学習に統計学が必要なのか
機械学習をする上で必ずしも統計学の知識が必要な訳ではありません。
豊富なライブラリや学習済みモデル、データセットなどがネット上に存在するので、簡単な機械学習なら調べながら行うことができるでしょう。
しかし、機械学習の学習を進めるならば、データの処理や分析方法の理解が必要になっていきます。
機械学習のベースとなっているのは数学や統計学であるため、これらの学習が必要になるのです。
▶関連記事|機械学習のための数学について解説|おすすめの書籍や講座も紹介!>>
機械学習と統計学の関係性
機械学習と統計学には深い関係性があります。
機械学習で扱われる用語である「決定係数」や「標準偏差」などは統計用語でもあります。
統計学は古くから存在している学問であり、国勢調査などにも古くから扱われていました。
統計学も機械学習もどちらもデータを扱い、数値を推定または予測することが目的とされているので非常に似ているものだと感じるでしょう。
そのため、統計学の学習を進めれば、機械学習の学習をスムーズに行うことができると言えるでしょう。
機械学習手法と統計学的手法の違い
機械学習的手法と統計学的手法には決定的な違いがあります。それは”データを扱う”目的”と言えます。
機械学習では、蓄積されたデータから予測をしていきます。蓄積されある特徴を持ったものは学習済みモデルと呼ばれます。その学習済みモデルが、別の新しいデータに対して予測を行います。そこで結果として出てきた予測結果は、予測の精度の高さを求められます。
一方で統計学では、ばらつきのあるデータから規則性や不規則性を見出し、データに根拠を持たせるために用いられます。
データを分析し、そのデータからまだ見ぬデータを予測していくことにも使用され、予測されたデータが妥当であるかどうか説明することを求められます。
つまり、機械学習は予測精度を高めるために、統計学は仮説を検証し、根拠をもって説明するという目的があります。
▼関連記事はこちら
▶機械学習におけるモデルとは?|モデルの種類や「よいモデル」とは何かについて>>
▶機械学習の代表的なアルゴリズム12選|機械学習の学習手法まで紹介!>>
機械学習モデルと統計モデルの使い分け方
機械学習と統計学は目的に違いがあります。
そこで、どのように機械学習手法と統計学的手法を使い分けるとよいのでしょうか?
機械学習は、予測精度を追及することに使用されます。
精度が高ければ高いほど良いとされるので、ユーザーレコメンドなどに使用されます。
ユーザーレコメンドとは、顧客に対して興味のありそうなものを勧めることです。
例として、顧客の購入履歴や閲覧履歴から、似た商品をおすすめの商品として勧めることを指します。この時、顧客の好みにより近いものが精度が高いとされます。
このように、ロジックはわからなくとも精度が高ければ良いという場面で利用されます。
一方で統計モデルでは、データを分析し新たな物事を導き出す場合に使用され、機械学習に比べて家庭が分かりやすいといった特徴もあります。
過程がわかりやすい、つまりアルゴリズムが単純であるということなので、不確実なデータや少ないデータから傾向をつかむことや、モデル全体を知りたい場合に傾向をつかんでくれるということができます。
統計学で機械学習を学べるおすすめ本3選
統計学で機械学習を学びたいと思う方におすすめの本を3つ紹介します。
それぞれ紹介していきます。
完全独習 統計学入門

出典:Amazon
完全独習統計学入門は、非常にわかりやすく統計学に関して説明がされている一冊です。統計学を勉強する上で重要な穴埋め問題や練習問題が解説付きで初歩から説明されてます。
データサイエンスのための統計学入門

出典:Amazon
データサイエンスのための統計学入門は、統計学と機械学習に関する基本概念、R、Pythonのコードが書かれています。データ分類、分析、モデル化、予測という一連のデータサイエンスのプロセスにおいて、統計学の基本と実績的なデータサイエンスの技法を効率よく学ぶことができます。
ベイズ推論による機械学習

出典:Amazon
ベイズ推論による機械学習は、ベイズ推論を最短経路で学ぶことができる一冊です。ベイズ推論を勉強し始めた初心者向けに、一から丁寧に書かれています。
▼関連記事はこちら
▶【2021年版】AI関連のおすすめ本15冊をランキング形式でご紹介>>
▶ディープラーニング関連オススメ書籍TOP20&テーマ別38冊を紹介!>>
▶機械学習インターンとは?業務内容や受かるためのスキルなど徹底解説>>
まとめ
今回の記事では、機械学習と統計学の違いやおすすめの本を紹介しました。
機械学習と統計学は、どちらも多くの企業や機関で用いられており、重要な分野だと言えるでしょう。
これらの違いをハッキリと確認し、機械学習と統計学の勉強を進めてみてください。



























