

近年、機械学習の一つの手法である、強化学習が注目されています。例えば、囲碁の世界チャンピオンを倒したAI「Alpha Go」も強化学習を採用しています。
強化学習とは、学習データに正解が与えられる教師あり学習、与えられない教師なし学習に並ぶ、もう一つの手法です。あなたは、その違いを説明できますか?
この記事では、その仕組みを環境やエージェントなど、強化学習に特有の用語も交えて、具体例とともに解説。さらに、活用事例や今後課題まで紹介します。
「強化学習について良く分からない」という方は、ぜひ読み進めてみてください。
強化学習とは
強化学習とは、機械学習の一つの手法です。
機械学習とは、「コンピュータに、大量のデータを取り込み、パターンやルールを発見させ、それを未知のデータの判別や予測に使う技術」のことです。
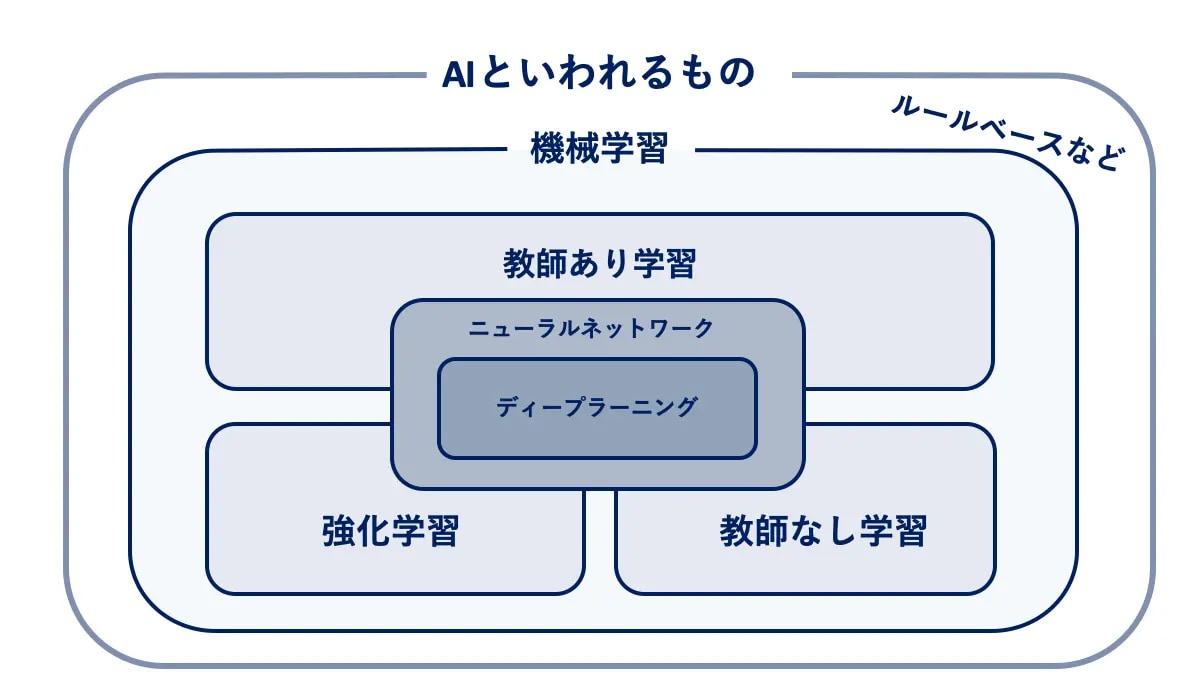
では、機械はどうやってパターンやルールを発見するのでしょうか。方法は3つあり、それによって機械学習は分類されます。
機械学習の分類
AINOW編集部作成
1つ目の方法は「教師あり学習」です。
ここで指す教師とは「正解のデータ」のことです。正解のデータを参照しながら、与えられたデータが正しいかどうかを学習させ、AIのモデルを作成します。
そのモデルに、未知のデータを与えると、正しいか間違っているか判定してくれます。
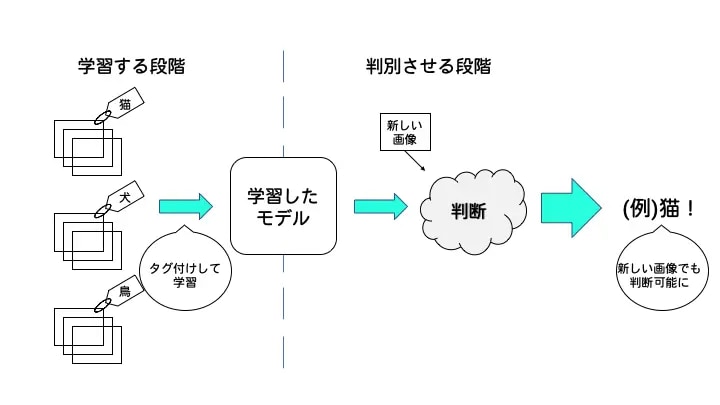
教師あり学習の代表例は、分類プログラムです。イヌとネコの画像データを大量に学習させたうえで、そのモデルに新しいイヌまたはネコの画像を与えると、自動で分類してくれます。
このように、学習のステップと、認識・予測のステップに分かれているのが一般的で、話題のディープラーニングもこの中の一つです。
2つ目の方法は「教師なし学習」です。
教師なし学習とは、教師あり学習とは異なり、正解のデータが与えられないまま、機械が学習する学習手法のことを指します。
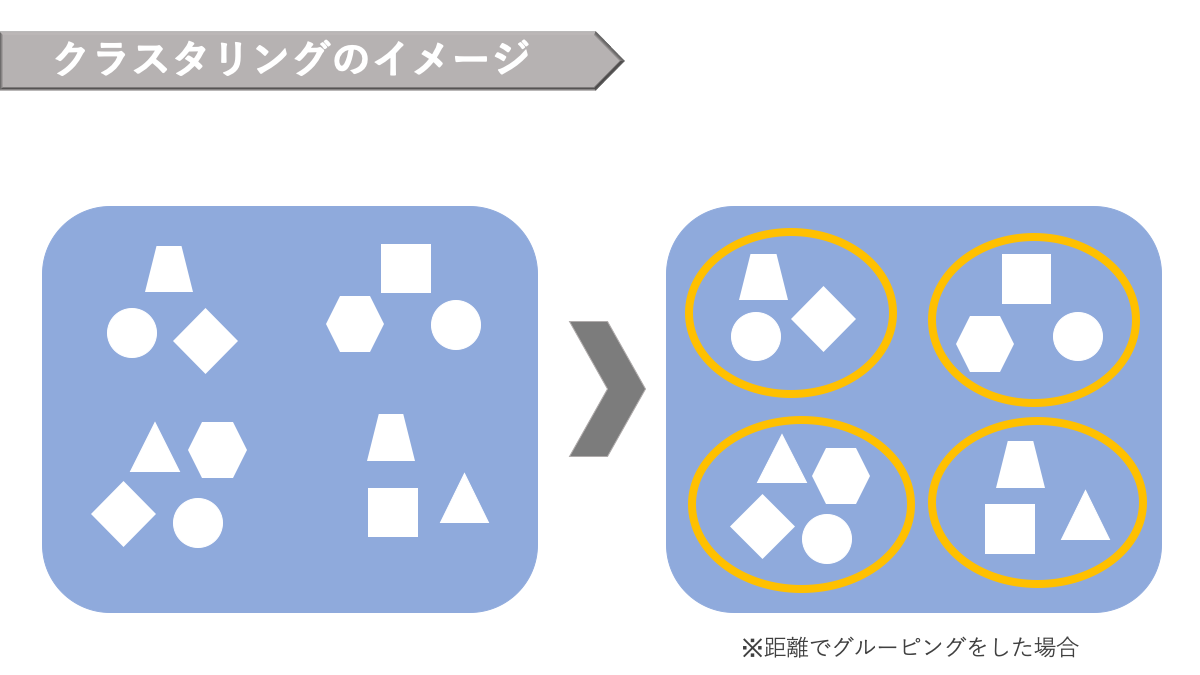
教師なし学習を用いたプログラムは、「教師あり学習」とは異なり、膨大な教師データを学習しません。代わりにデータそのものが持つ構造・特徴を分析し、グループ分けやデータの簡略化をします。
この教師なし学習の代表的な手法がクラスタリングです。「クラスタリング」と呼ばれるこの手法は、教師あり学習の分類問題とは全く異なる仕組みです。
AINOW編集部作成
3つ目の方法は「強化学習」です。
強化学習は、機械が取る戦略を学習しながら改善していく手法になります。正しいデータを与えられるのではなく、「報酬」と呼ばれる行動の望ましさの手がかりのようなものを参照して、試行錯誤を繰り返します。
強化学習のわかりやすい例は、掃除ロボットです。掃除ロボットは、「ゴミ」という報酬をなるべく多く得られるように、「ゴミが多くとれる経路」を試行錯誤を繰り返しながら学習していきます。
また、人間が自転車に乗れるようになるプロセスも強化学習になぞらえられます。最初は、グラグラしてなかなか前に進めません。
しかし、評価を参考にしながら方法を少し変えることで、前に進めるようになってきます。これを繰り返すことで、最適な方法がわかってきて、だんだんと長い距離をこなせるようになります。
▼機械学習について詳しく知りたい方はこちら

▼AIについて詳しく知りたい方はこちら

強化学習のメリット・デメリット
強化学習のメリットは、囲碁や将棋のようなゲームに、AIが人間を下した点にみることができます。
これらのゲームは、個々の局面でどの行動を取るべきか、意見が分かれることがあります。よって、個々の行動をどう評価するかも難しいところです。
しかし強化学習では、このような、複数回の行動を伴う複雑な手続きを評価したうえで最適化できます。また、ロボットの歩行制御も強化学習の得意分野です。
強化学習では、長く歩くことを報酬に設定すれば、関節の動かす角度や、歩幅、左右のタイミングなどを自動で学習できます。しかし、教師あり学習の場合、それらのデータを入力と出力のセットで準備する必要があります。
一方で、デメリットもあります。
まず、学習に大量な時間がかかります。これは機械学習全般に言えるデメットですが、強化学習の場合は特に顕著です。
また機械が、導き出した最適な行動が、人間にとって合理的ではない可能性もあります。一概に、強化学習が良い、悪い、と考えるのではなく、目的に合わせて最適な学習方法を選ぶことが重要です。
▶AIによるメリット・デメリットは?人工知能の問題点と解決策も紹介>>
強化学習の仕組み
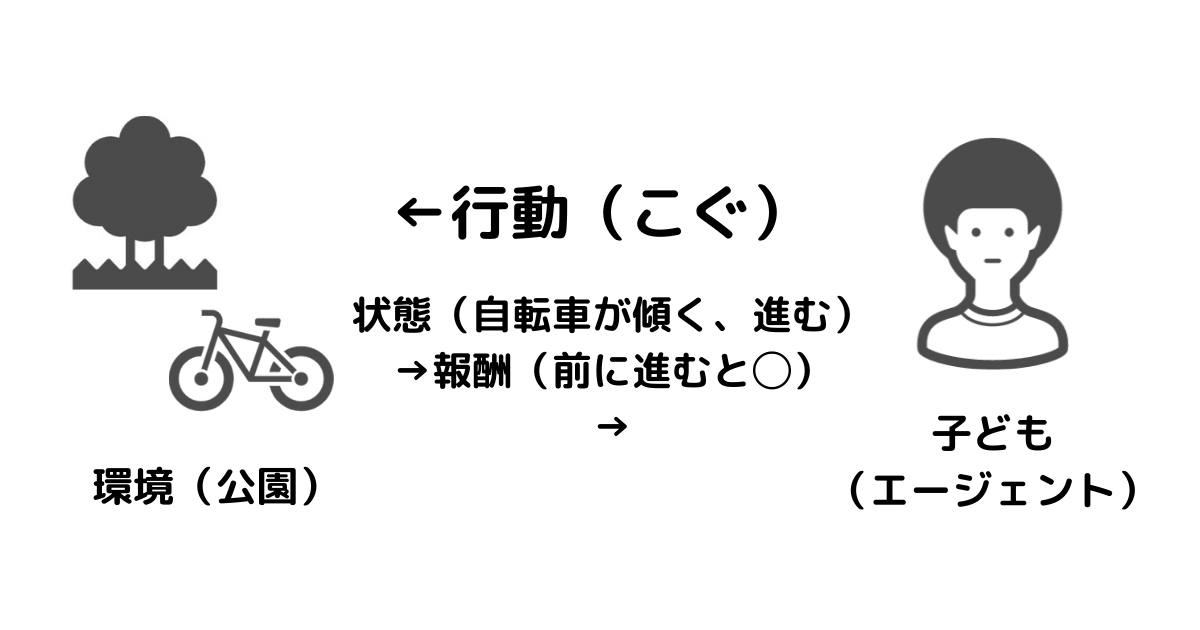
では、もう少し詳細に強化学習の仕組みをみていきましょう。再び自転車の例で説明します。
まず、自転車に乗るために、公園に来たとしましょう。乗れるようになりたいのは、子どもとします。このとき、公園のことを「環境」子どものことを「エージェント」と呼ぶことにします。
さて、自転車に乗るためには、ハンドルを握り、ペダルをこぎ、バランスを保つ必要があります。これらを「行動」と呼びます。行動が変化を起こす対象を「状態」と言います。
行動の結果、ふらついたり、前に傾いたりと、変化が生じます。これは、状態が変わったと言えます。その状態に応じて、前に進むことができたり、こけたりするはずです。
この結果に対して「報酬」を設定します。例えば、「50mを自転車で走れるようになること」を1点とします。
エージェントは、1点を取るにはどんな行動を取るのが良かったのかを逆算しながら学習していきます。
「教師あり学習」はペダルの漕ぎ方や バランスの保ち方、転び方などの「各行動」を逐一評価するのに対して、「強化学習」はハンドルの握り方からバランスの保ち方までの「連続した行動」を評価します。
子どもは、試行錯誤していくなかで、報酬を最大化。つまり、結果的に長い距離を進むことを目指し、そのために最適な行動のルールを学習します。
この行動のルールのことを、「方策」と呼びます。
Q値・Q学習法とは
強化学習とセットでよく耳にするQ学習法とは、強化学習の典型的なアルゴリズムです。
強化学習では、行動に応じて報酬が発生し、それを元に行動を修正していきます。しかし、そこで一つ問題が生じます。
すぐに貰える報酬を最大化するような行動が、長い目で見た時に、もっとも望ましい行動であるとは限りません。
例えば将棋において、相手の重要な駒を取る行動は、短期的に見れば望ましい行動に見えます。しかし、その行動によって、守りが大きく損なわれるのであれば、長期的に見るとむしろマイナスな行動になります。
長期的に見た時の報酬のことを「価値」といいます。短期的な報酬ではなく、長期的な価値を最大化するような行動が必要です。
そして、ある状態において、ある行動を取った際に得られる価値を「Q値」といいます。
Q値には期待値が含まれています。期待値を計算するには、実際には次の状態を正確に見積もることが必要です。
しかし、厳密には不可能です。これは具体例をあげてみると分かりやすいでしょう。
例えば、「棋を打つ行動を取ったとき、その後相手がどのような行動を返してきて、状態がどう変わるか」を知ることは不可能です。また、テトリスでは、「次のブロックで何が来るか」は分かりません。
そこで、実際に行動を起こし、Q値を逐一更新する方法で学習すれば、具体的に期待値を計算しなくても、結果的に問題を学習したことになります。
Q学習とは、Q値を学習するための一つのアルゴリズムです。その他のアルゴリズムとして、Sarsaやモンテカルロ法などがあります。
参考文献:https://blog.brainpad.co.jp/entry/2017/02/24/121500#f-860f34e5
深層強化学習とは
強化学習は、深層学習と組み合わせて深層強化学習とすることで、さらに実用性が増しました。深層学習は、ディープラーニングとも呼ばれる「教師あり学習」の一つです。
従来の機械学習との違いは、特徴量を機械が学習する点にあります。
例えば、犬と猫を判別するAIをつくるとします。従来は、どこに注目するかを人間が指定していました。例えば、耳の形やひげがあるかなどです。
一方でディープラーニングは、何が重要であるかを機械が自動的に学習します。その結果、人間が指摘した特徴を用いるより、高精度になる場合があります。
強化学習は与える報酬によって結果が大きく異なるため、どのような報酬を与えれば良いのかが難しいところです。
深層強化学習では、行動の価値を表す部分に深層学習を使います。これが、前述したQ値を導くための関数になります。
言い換えると、Q関数に深層学習を使ったものが深層強化学習になります。
Q値とは:ある状態において、ある行動を取った際に得られる価値
深層強化学習によって、ゲーム画面のような高次元の状態を持つタスクでも、成功例が生まれ、強化学習を幅広く活用できるようになりました。
▼深層学習(ディープラーニング)について詳しく知りたい方はこちら

強化学習の課題
自ら最適な行動を学習していく様子は、いかにも人間らしい人工知能のイメージにぴったりです。一方で、実際は強化学習にもさまざまな課題があります。
まず、強化学習はあくまで、ある環境において最適な行動を学習しているに過ぎません。
例えば、自動運転技術を搭載した車が上手に障害物を避けられるようになったとしても、実際に公道を走るためには、信号機や標識などのルールを守れないといけません。
また、急に人が飛び出してきたときに特別な対応をとる必要があります。このように、単純な環境でないと実用が困難です。
例えば、ゲームやロボットの分野は、強化学習が得意としています。その他の分野は、今後の課題と言えます。
強化学習の事例
では、実際に強化学習を活用した事例を見ていきましょう。
ゲームの例
ゲームは、強化学習が得意な分野です。例えば、下記の動画では、マリオテニスにおいて最適な行動を学習しています。
ロボットの例
ロボットも同様に強化学習が得意な領域です。例えば、下記の動画のような物体保持への活用事例があります。
自動車の例
自動運転にも強化学習が使われています。公道とは程遠いゲームのような環境ですが、それぞれの車がぶつからないように自動でルートを学習しています。
▶《AI事例25選》産業別にAIの活用事例をまとめました>>
おわりに
強化学習は、報酬を最大化するために最適な行動を学習する技術です。
これは、目的のために試行錯誤しながら手段を試す「人間の学習」と似ているように思われます。また、囲碁の例のように、めざましい成果をあげた技術でもあります。
一方で、まだまだ活用の範囲は狭く、課題もあるでしょう。目的に応じて、教師あり・なし学習と使い分けることが肝心と言えます。
【参考文献】
https://blog.brainpad.co.jp/entry/2017/02/24/121500#f-860f34e5
https://www.slideshare.net/pfi/nlp2018-introduction-of-deep-reinforcement-learning



























