
 2022年11月にOpenAIによりChatGPTが公開され、それ以降も世界的なビッグテックが次々に大規模言語モデル(LLM)の開発に乗り出し、開発競争が激化しています。あわせて2023年3月15日、OpenAIはマルチモーダルに対応したGPT-4をリリース。マルチモーダルにさまざまなデータ形式に対応できるAIの進化が今後も加速していくと考えられます。
2022年11月にOpenAIによりChatGPTが公開され、それ以降も世界的なビッグテックが次々に大規模言語モデル(LLM)の開発に乗り出し、開発競争が激化しています。あわせて2023年3月15日、OpenAIはマルチモーダルに対応したGPT-4をリリース。マルチモーダルにさまざまなデータ形式に対応できるAIの進化が今後も加速していくと考えられます。
AI inside は、早期からAIをSaaSとしてパッケージ化、事業化し、AIの社会実装を牽引してきました。同社のデジタルデータ化サービス「DX Suite」は、AI OCR分野で高いシェアを占めています。
AI inside は、2023年2月13日、あらゆるデータを活用し自律学習するAIにより、誰もが意識することなくAIの恩恵を受けられる世界を目指す「AnyData」を発表しました。これまでAI分野を牽引してきたAI inside は、AI OCR分野以外にも進出を続け、事業を拡大させたい計画です。
同社は、現在のAI市場をどのように捉え、今後どのように事業展開していくのか。大規模言語モデルをどのように事業に取り込んでいくのか、AI inside 代表取締役社長CEO渡久地択氏へのインタビューをお届けします。
目次
コロナ禍でも成長を続けてきたAI inside の主力事業「DX Suite」
新型コロナウイルスの感染拡大を受け、リモートワークの拡大や、ペーパーレス化の推進など社会的にDXの注目が高まりました。あわせてAI inside が提供するAI OCRを活用したデジタルデータ化サービス「DX Suite」は提供数が大きく伸長しています。

渡久地:2019年時点の「DX Suite」のユーザー数は、500人で業界トップでした。創業当時から、代理店戦略やパートナー戦略を実行し、現在は46,000人を超えるユーザー数にまで成長しています。さまざまな企業様のAIインフラになるべく、AI運用基盤に投資を続けています。
また、AI inside は、機密性が高いデータのクラウドでの活用が難しい背景や、AIの運用コスト削減などを目的に独自のOSとソフトウェアにより、あらゆるAIの運用を実現するためのエッジコンピュータ「AI inside Cube」も提供しており、エッジAI領域にも展開をしています。
渡久地:「AI inside Cube」は、金融機関・行政・BPOなど、大量に紙書類が発生し、その処理業務を捌いている企業様に多く利用されています。
セキュリティ面ももちろんですが、昔に比較すると、大量処理のコスト・工数最適化のニーズが強くなってきています。
あわせて同社はAI OCR以外の事業領域にも展開を始めています。2021年4月に、ノーコードで画像や物体認識のAIモデルの開発ができるプラットフォーム「Learning Center Vision」の提供を開始しました。
「Learning Center Vision」は直感的な操作(GUI)で日本語のUIを備え、ノーコードでAIモデル開発ができるサービスです。
渡久地:さらに、テーブルデータをもとに、ノーコードで予測・判断AIのモデルを作れるプラットフォーム「Learning Center Forcast」の提供も始まっています。
物体検出と予測・判断ができる「Learning Center」を活用して顧客が作ったAIモデル数は、順調に増えています。提供開始直後の2021年6月末時点では14件でしたが、今(2022年12月末)では394件になっています。
AIモデルの自動生成を可能にする自律型AI「AnyData」
AI inside が次に実現を目指すのが、音声や画像、テキストなどさまざまなデータを入力するだけで、AIモデルを自動生成する「自律型」のAIです。AI inside は2023年2月13日、さまざまな課題解決ソリューションを生み出す「AnyData」を発表しました。
「AnyData」は、種類・形式を問わないあらゆるデータを元に、つまりマルチモーダルな自律学習によりAIモデルを生成する「Autonomous Learning」の技術を活用したものです。
渡久地:複合的にデータを処理し、課題を解決できるマルチモーダルAIの構想は創業当時からありました。もともと創業する時に、AIと宇宙のキーワードが浮かんでいて、宇宙のような未知の事象に対応しなくてはいけない場合は、自律的なAIが絶対に求められると考えていました。
自律型でマルチモーダルに対応したAIの登場によって、今までは解決できなかったニッチな課題も解決できると思います。「AnyData」によって、学習させたい社内のデータを取り入れ、出力を設定するだけのシンプルな作業で、業務を自動化できるようになります。
先ほどの「Learning Center」でノーコードでAIを作るというところから一歩進んで、そもそもAIを作る・アノテーションする必要もないものです。なんでもデータをマルチモーダルにインプットすると、AIが自律的に課題設定して、モデルを自動生成していくというものなので、あらゆるデータをAIに触れる状態にすることで、複合的に課題解決ができるようになります。
まずは、金融・保険・行政・BPO・製造・医療・小売流通などデータの活用が多い業種から適用していきたいと考えています。
また、電帳法対応が多くの企業の喫緊の課題となっているので、AnyDataを導入すれば簡単に電帳法対応ができるソリューションも提供していきます。
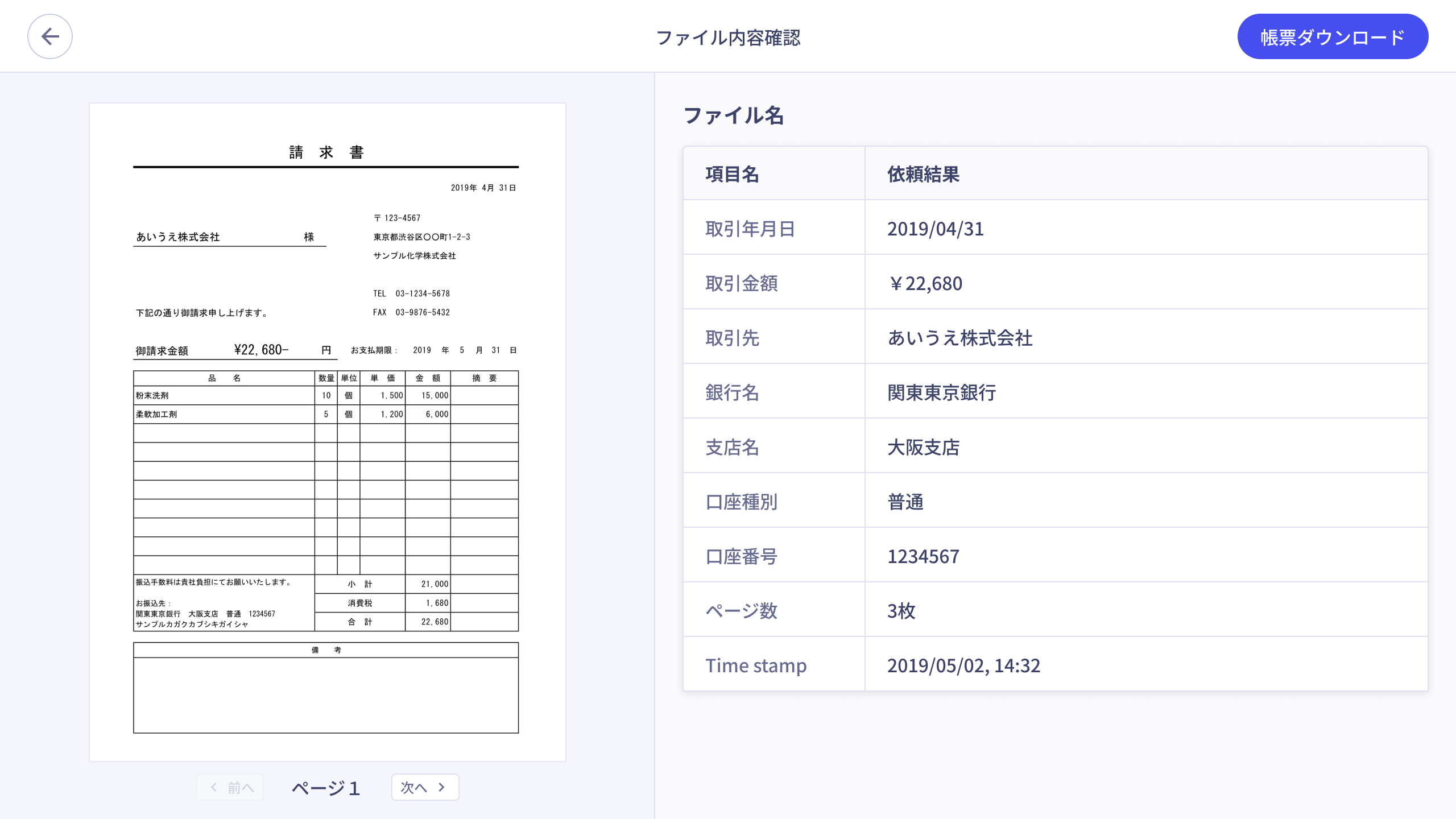
電帳法対応ソリューションの画面 ※画面は開発中のものにつき実際の仕様とは異なる場合があります。
しかし、簡単にモデルを構築できることが現場へのAI活用の拡大に繋がるとは限らない一面も残っています。実際、ノーコードでAI活用を進める多くのプラットフォームが提供されていますが、会社の現場で活用が進んでいるとはまだ言えない現状です。渡久地氏も同様の課題を挙げています。
渡久地:ツールの導入だけではAIの導入はすすみません。課題は何か、AIを活用すれば解決できる課題なのかなど課題の解像度を高める必要があります。
そこで、AI insideではAI Growth Programを提供しています。我々のツールは簡単に使えるので、ツールの使い方というより、課題の抽出・AI活用案の策定から、AIを活用した新規ビジネス創出の支援にフォーカスを当てた教育プログラムです。
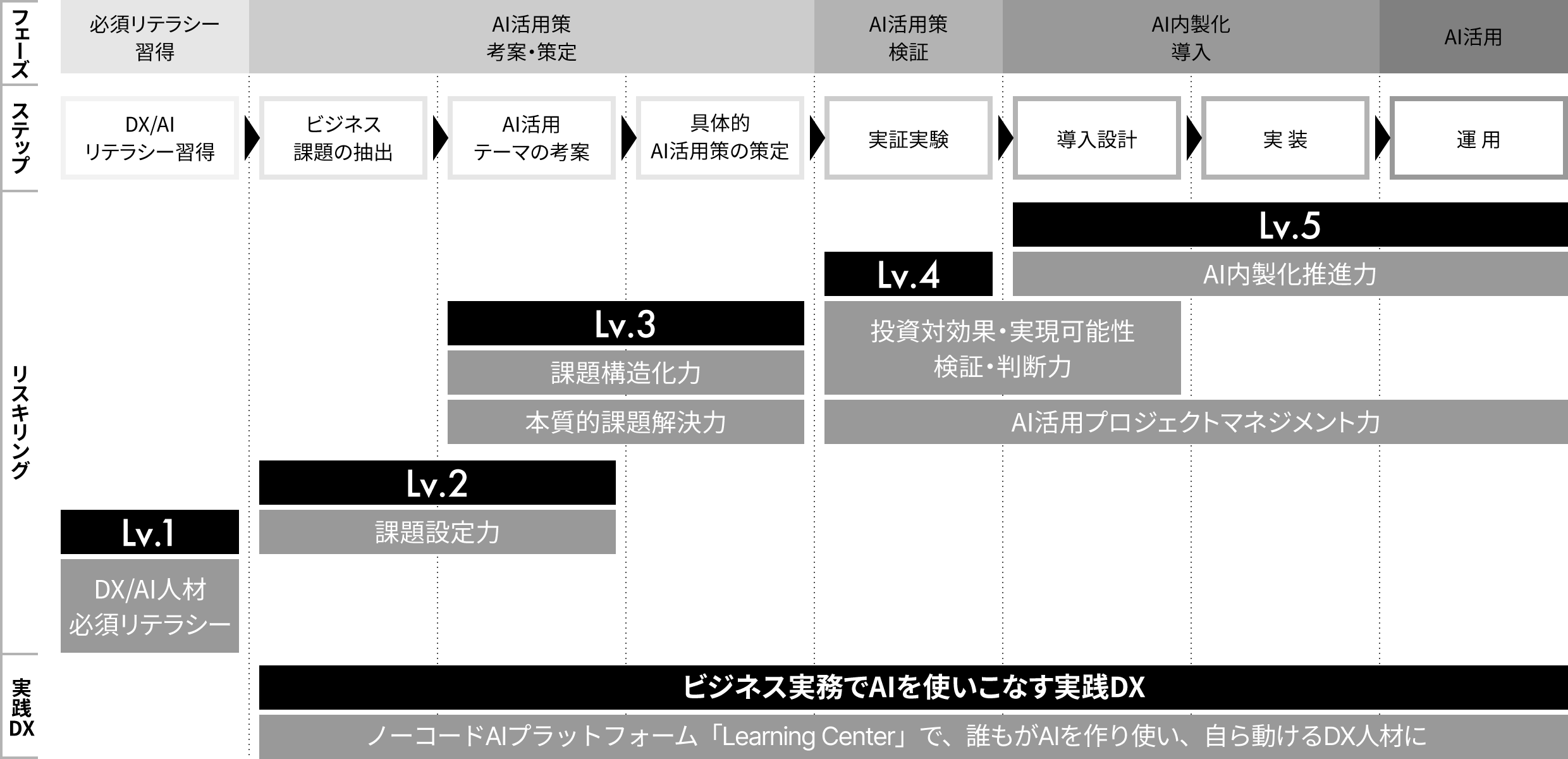
AI 導入までの流れ 【提供:AI inside】
大規模言語モデルでAI OCRはどのように進化する?
ChatGPTを筆頭に、大規模言語モデル(LLM)の社会的注目が高まる中、渡久地氏はどのようにトレンドを捉えているのでしょうか。

渡久地:AI OCRは、まさにテキストをデジタルデータ化していく技術です。だからこそ、LLMの活用に向いている分野だと思います。画像や音声などあらゆるデータを人間はテキスト化して理解していると思います。テキストはあらゆるデータの中心的な存在です。言い換えれば人間のプロトコル(規格)はテキストであると考えることもできるでしょう。
今後、テキストを処理する技術の進歩がさらに自動化の幅を広げていくと予想されますし、「DX Suite」をはじめとした当社のサービスにも積極的にLLMを活用していきたいと思っています。
例えば、健康診断書でも自身の健康データが時系列で整理できます。健康診断書をAI OCRで読み取る際、テキストの意味を理解して、構造化をするなど。もともと、非構造化データの構造化は買収により技術取得して強化しているところでした。さらに、これまでの健康データをもとに、健康状態の予測もできます。これらの工程を繋ぎこむ際に、LLMの活用は重要です。
さいごに
今回は、AI insideが発表した「AnyData」についてお話を伺いました。
今までのAIは特定の課題にしか対応できないなど、活用を進める上で課題があったり、特定の用途でしか活用ができないなど、超えるべき壁が残っていました。
マルチモーダルなAIの研究開発がすすみ、大規模言語モデルの精度も高まる今、「AnyData」のようなサービスが生まれることにより、さらにAIの活用を進める起爆剤になっていくと予想されます。
AINOWは引き続き、マルチモーダルAIや大規模言語モデルの動向に注目し、発信していきます。



























