
全社で生成AIを使わせたいのに、社員が機密情報を入力して漏洩しないか不安で踏み出せない。本記事では、情報漏洩が起こる仕組み、実際の事例、企業が取るべき対策、主要ツールの学習オフ設定を、ガイドライン整備にそのまま使える形で解説します。
ChatGPTやGeminiを業務で使わせたいものの、顧客情報やソースコードの入力による情報漏洩が怖くて全社展開に踏み切れない。情シスやDX推進の担当者は、活用と統制の板挟みになりやすいでしょう。
対策を曖昧にしたまま使わせると、顧客情報や開発中の製品情報が外部へ流出し、信用失墜や損害賠償に直結します。逆に仕組みを理解して正しく対策すれば、禁止せず安全に全社活用でき、生産性で差をつけられるでしょう。
本記事では、情報漏洩が起こる仕組み、実際の漏洩事例、企業が取るべき具体的な対策、主要な生成AIツールの学習オフ設定までを、公式情報とともに整理します。
読み終えれば、ルール・技術・人の3面で抜け漏れなく実装できる対策フレームが手に入り、安心して生成AIを業務に取り入れられる状態になります。
目次
生成AIで情報漏洩が起こる仕組み
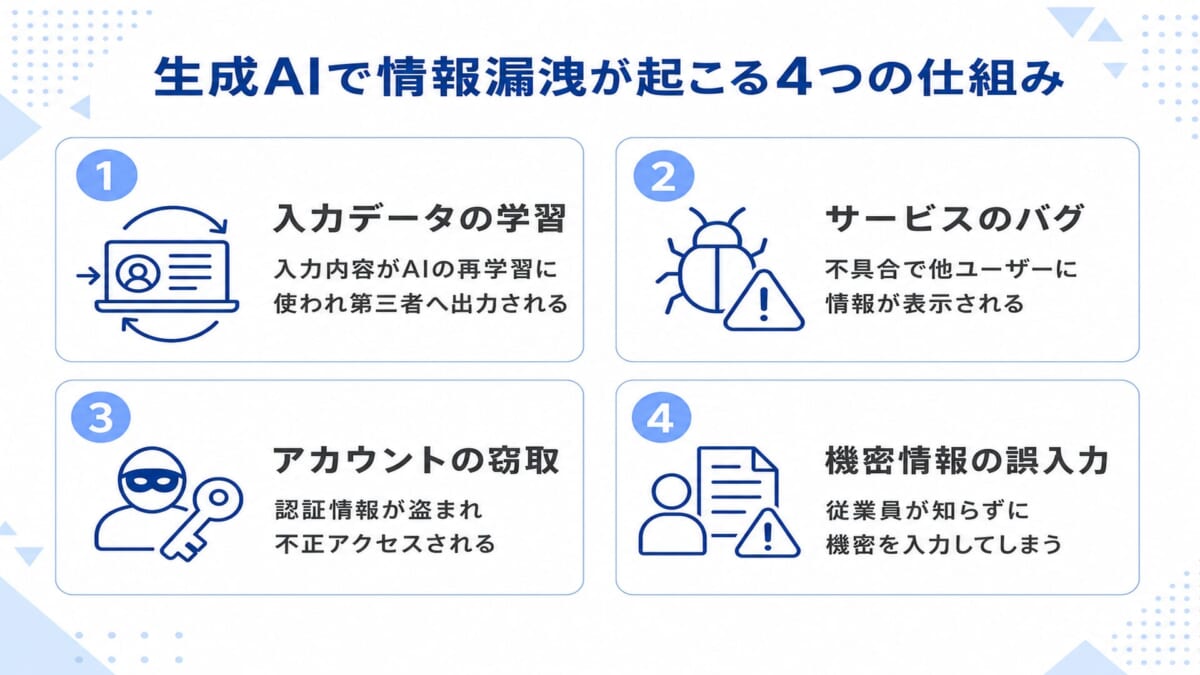
生成AIで情報漏洩が起こる仕組みは、主に以下の4つに整理できます。
- 入力データがAIの学習に利用される
- サービスのバグで他ユーザーに表示される
- アカウント情報の窃取や不正アクセス
- 従業員による意図しない機密情報の入力
どの経路で漏れるかを理解しないと、対策が的外れになります。順に見ていきましょう。
入力データがAIの学習に利用される
最も代表的な経路が、入力したデータがAIモデルの学習に使われることです。
一部の生成AIサービスでは、プロンプトに入力した内容がモデルの精度向上のために再学習へ回されます。そこに未公開の製品名や顧客情報を含めると、組織外への流出に直結します。
学習されたデータは、別のユーザーが関連する質問をした際に、回答の一部として出力される可能性があります。自社の機密が第三者の画面に現れる事態になりかねません。
裏を返せば、学習をオフにする設定や法人プランを選べば、この経路は大きく抑えられます。仕組みを理解すれば、入力データの扱いを起点に対策を設計できます。
サービスのバグで他ユーザーに表示される
自社の使い方が正しくても、サービス側のバグで情報が漏れることがあります。
2023年3月には、ChatGPTでシステムのバグにより、一部ユーザーが他人のチャット履歴のタイトルを閲覧できる不具合が発生しました。提供者側の問題でも漏洩は起こります。
利用者側で完全に防ぐのは難しいものの、機密情報をそもそも入力しなければ被害は最小化できます。入力情報の管理が、提供者起因のリスクへの備えにもなります。
つまり、サービスを過信せず「漏れても困らない情報だけ入れる」前提を持つことが、不確実な不具合への現実的な守りになります。
アカウント情報の窃取や不正アクセス
3つ目は、アカウント情報が盗まれ、保存データにアクセスされる経路です。
セキュリティ企業Group-IB(グループアイビー)は2023年、インフォスティーラーに感染した端末から約10万件分のChatGPTアカウント情報が盗まれ、ダークウェブで売買されていたと報告しました。
アカウントが乗っ取られれば、保存されたチャット履歴や業務情報がそのまま流出します。端末のマルウェア対策や多要素認証が欠かせません。
生成AI固有のリスクに見えても、根は従来のアカウント管理と端末セキュリティにあります。既存の対策を生成AIにも適用することが守りになります。
従業員による意図しない機密情報の入力
実務で最も多いのが、従業員が知らずに機密情報を入力する人的な経路です。
「便利だから」と無料ツールに顧客リストを貼り付けたり、契約書を要約させたりする行為が、自覚のないまま漏洩につながります。悪意ではなく知識不足が原因です。
会社が許可していないツールを個人判断で使う「シャドーAI」も、把握できないところで情報が外部に渡る温床になります。
この経路はルールと教育で大きく減らせます。入力してよい情報の線引きを明示すれば、現場の判断ミスを未然に防げます。
生成AIによる情報漏洩の事例
実際に起きた情報漏洩の事例を3つ紹介します。
- 大手電機メーカーの機密情報入力による流出
- ChatGPTのバグによる個人情報の表示
- インフォスティーラーによるアカウント情報の窃取
自社で同じことが起きないか、リスクに重ねながら読み進めてみてください。
大手電機メーカーの機密情報入力による流出
2023年、韓国の大手電機メーカーで、従業員がソースコードをChatGPTに入力して機密が外部に渡った事例が報じられました。
半導体部門のエンジニアが、設備関連のソースコードの不具合修正を依頼するために、社内コードをそのまま入力したと報じられています。
同社はこの後、社内での生成AI利用を一時的に制限する対応を取ったとされます。便利さを優先した結果、利用そのものを止めざるを得ない状況に陥りました。
この事例の教訓は明確です。「入力してはいけない情報」を事前に定義しておけば、現場の善意の行動が事故に変わるのを防げます。
ChatGPTのバグによる個人情報の表示
2023年3月、ChatGPTでシステムのバグにより他人の情報が表示される不具合が発生しました。
一部のユーザーが他人のチャット履歴のタイトルを閲覧できる状態になり、さらに有料プラン契約者の氏名やメールアドレス、クレジットカード情報の一部が短時間表示される事態も起きました。
原因はキャッシュに使われていたソフトウェアの不具合とされ、OpenAIは一時サービスを停止して修正しました。利用者側に落ち度がなくても漏洩は起こります。
提供者側のリスクはゼロにできません。サービスを過信せず、入力情報を絞ることが現実的な防御になります。
インフォスティーラーによるアカウント情報の窃取
2023年、約10万件のChatGPTアカウントがダークウェブで売買されていた事実が判明しました。
セキュリティ企業Group-IBの調査によると、情報窃取型マルウェア(インフォスティーラー)に感染した端末から認証情報が盗まれ、闇市場で取引されていたとされます。
アカウントを乗っ取られれば、保存された業務上のやり取りがそのまま閲覧されます。端末の感染が、生成AI経由の漏洩につながる構図です。
対策は従来のセキュリティと地続きです。多要素認証とマルウェア対策を徹底すれば、アカウント窃取の被害を大きく抑えられます。
生成AIの情報漏洩がもたらすリスク
情報漏洩が現実になると、企業は信用と金銭の両面で打撃を受けます。
ここでは代表的なリスクを2つに分けて解説します。被害の大きさを知ることが、対策に投資する判断につながります。
顧客や取引先からの信用失墜
情報漏洩が起きると、顧客や取引先からの信用を一気に失います。
預けた情報が流出した取引先は、再発を懸念して取引の縮小や停止を検討します。一度離れた信用を取り戻すには、長い時間とコストがかかります。
漏洩の事実が報道やSNSで広がれば、直接の被害者でない見込み客にも不安が伝わり、ブランドイメージそのものが傷つきます。
だからこそ、事前の対策が重要です。漏らさない体制を整えることが、長期的な信頼と売上を守ります。
損害賠償や法令違反の責任
漏洩した情報の内容によっては、損害賠償や法令違反の責任を問われます。
個人情報が流出すれば、個人情報保護法に基づく対応が必要になり、被害者から損害賠償を請求される可能性もあります。取引先との秘密保持契約に違反すれば、契約上の責任も生じます。
個人情報保護委員会も、生成AIサービスの利用にあたって入力情報の性質や取り扱いを確認するよう注意喚起しています。法的な備えも経営課題です。
金銭的な負担は、対策コストをはるかに上回ります。事前のルール整備は、将来の賠償リスクへの保険になります。
生成AIの情報漏洩を防ぐ対策
情報漏洩を防ぐ対策は、以下の6つをルール・技術・人の3面で組み合わせます。
- 利用ガイドラインを策定し周知する
- 入力してはいけない情報を明確にする
- 入力データを学習させない設定にする
- 法人向けプランやAPIを利用する
- DLPやCASBで技術的に制御する
- 従業員へ継続的に教育する
1つの対策に頼ると抜けが生まれます。複数を重ねることで、はじめて実務で守れる体制になります。
利用ガイドラインを策定し周知する
対策の土台は、利用ガイドラインを作って全社に周知することです。
判断基準がないと、現場は「使っていいのか分からない」と止まるか、逆に無防備に使ってしまいます。ルールがあってはじめて、安全と活用を両立できます。
ガイドラインには、利用を認めるツール、入力禁止情報、生成物の社外利用基準、レビュー手順、事故発生時の連絡先を盛り込みます。実際の漏洩事例を添えると、ルールの必要性が腹落ちします。
作って終わりにせず、現場の疑問をFAQとして追記し続けましょう。更新され続けるガイドラインが、形骸化を防ぎ実効性を保ちます。
入力してはいけない情報を明確にする
ガイドラインの中核として、入力してはいけない情報を具体的にリスト化します。
「機密情報は入力禁止」という抽象的な表現では、現場が判断に迷います。誰が見ても分かるよう、具体例を列挙することが重要です。
たとえば、以下のような情報を入力禁止として明示します。
- 顧客の個人情報や顧客リスト
- 未公開の製品情報や開発中のソースコード
- 取引先との契約書や秘密保持対象の情報
- 社員の人事情報やパスワード
判断に迷わないリストがあれば、現場は安心して使えます。線引きの明確化が、善意のうっかり入力を防ぐ最も効果的な一手です。
入力データを学習させない設定にする
技術面の基本は、入力データを学習に使わせない設定にすることです。
多くの生成AIサービスには、入力内容をモデルの学習に使わせないオプトアウト設定が用意されています。設定をオフにすれば、学習経由での漏洩リスクを抑えられます。
設定方法はツールごとに異なり、後述する主要ツールの手順で具体的に解説します。全社で使うツールは、管理者が一括で設定できるか確認しておきましょう。
無料で今すぐできる対策のため、優先度は高めです。まず学習設定を見直すだけで、リスクの一角をすぐに減らせます。
法人向けプランやAPIを利用する
より確実な対策は、法人向けプランやAPIを利用することです。
主要な生成AIサービスの法人プランやAPIでは、入力データを原則としてモデルの学習に使わない方針が明記されています。個人の無料アカウントより、データの扱いが管理されています。
法人プランは管理者によるアカウント管理やアクセス制御もしやすく、シャドーAIの抑止にもつながります。会社が正式なツールを用意することが、安全な利用の前提になります。
コストはかかりますが、漏洩時の損失と比べれば小さい投資です。会社公認の安全なツールを配ることが、現場の正しい利用を後押しします。
DLPやCASBで技術的に制御する
ルールを技術で支えるのが、DLPやCASBによる制御です。
DLP(データ漏洩防止)は、機密情報の送信を検知してブロックする仕組みです。生成AIへの入力前に機密を検出し、送信を止められます。
CASB(キャスビー)はクラウドサービスの利用を可視化・制御する仕組みで、会社が許可していないAIツールへのアクセスを監視・遮断できます。シャドーAIの抑止に有効です。
人の注意だけに頼らず、仕組みで止められる点が強みです。ルールと技術の二重防御が、うっかり入力を構造的に防ぎます。
従業員へ継続的に教育する
仕上げは、従業員への継続的な教育です。
ルールやツールを整えても、使う人が危険性を理解していなければ事故は起こります。漏洩は知識不足から生まれるため、教育が根本的な対策になります。
研修では、入力してはいけない情報の具体例、実際の漏洩事例、事故が起きたときの対応手順までカバーします。一度きりではなく、定期的に最新リスクを共有しましょう。
教育が浸透すれば、現場が自律的にリスクを避けられます。一人ひとりの判断力が、最後の砦として組織を守ります。
主要な生成AIツールの学習オフ設定
すぐにできる対策として、主要3ツールの学習オフ設定を解説します。
- ChatGPTで学習をオフにする設定
- Geminiで学習をオフにする設定
- Microsoft Copilotの設定
設定は数分で完了します。自社で使っているツールの手順を確認してみてください。
ChatGPTで学習をオフにする設定
ChatGPTでは、設定画面から学習利用をオフにできます。
画面左下のアカウントメニューから「設定」を開き、「データコントロール」内の「すべての人のためにモデルを改善する」をオフにします。これで入力内容が学習に使われなくなります。
業務利用なら、データを学習に使わないChatGPT TeamやEnterpriseの導入も選択肢です。管理者がメンバー全体のデータ扱いを統制できます。
無料アカウントでもオプトアウトは可能です。まず設定をオフにするだけで、最も基本的なリスクを取り除けます。
Geminiで学習をオフにする設定
Gemini(ジェミニ)では、アクティビティ設定をオフにすることでデータ利用を抑えられます。
「Gemini Apps アクティビティ」をオフにすると、会話が人によるレビューや今後の学習に使われにくくなります。設定はGoogleアカウントの画面から変更できます。
業務では、データを学習に使わないGoogle WorkspaceのGeminiなど、法人向けプランの利用が推奨されます。組織のデータ保護方針が適用されます。
個人と法人で扱いが異なる点に注意しましょう。用途に合ったプランを選ぶことで、安心してGeminiを使えます。
Microsoft Copilotの設定
Microsoft Copilot(コパイロット)は、法人向けでデータが保護される仕組みです。
Microsoft 365 Copilotでは、組織のデータがモデルの学習に使われない方針が示されています。エンタープライズ向けのデータ保護が標準で適用されます。
一方、無料版や個人向けの利用ではデータの扱いが異なる場合があります。業務で使うなら、保護対象となる法人プランかを必ず確認しましょう。
権限設定も重要で、アクセスできる範囲を絞らないと意図しない情報まで参照されます。プランと権限を正しく設定すれば、業務データを守りながら活用できます。
生成AIの情報漏洩対策に関するよくある質問
生成AIの情報漏洩対策に関する質問は以下の4つです。
- 無料版と有料版で情報漏洩リスクは違いますか
- 入力した情報は後から完全に削除できますか
- 中小企業でもすぐにできる対策はありますか
- ローカルLLMを使えば情報漏洩は防げますか
質問への回答を確認して、自社の対策づくりの参考にしてみてください。
無料版と有料版で情報漏洩リスクは違いますか
法人向けの有料プランのほうがリスクは低い傾向にあります。
多くのサービスで、法人プランやAPIは入力データを学習に使わない方針を明記しています。一方、個人の無料アカウントは設定次第で学習に使われる場合があります。
ただし無料版でも、学習オフ設定を行えばリスクは下げられます。業務利用なら法人プランを基本としつつ、設定の見直しも合わせて行いましょう。
入力した情報は後から完全に削除できますか
チャット履歴は削除できますが、完全な消去は保証されません。
多くのサービスで会話履歴の削除機能が用意されていますが、すでに学習に使われたデータをモデルから取り除くのは困難です。一度入力した情報は戻らない前提で考えましょう。
だからこそ入力前の管理が重要です。「消せるから大丈夫」ではなく「入れない」ことが、最も確実な対策になります。
中小企業でもすぐにできる対策はありますか
学習オフ設定と入力禁止リストの周知から始められます。
高額なツールを導入しなくても、各ツールの学習設定をオフにし、入力してはいけない情報を簡単な一覧にして社内共有するだけで、リスクは大きく下がります。
まずは無料でできる範囲から着手しましょう。小さく始めても、ルールと設定の徹底で実務上の安全は確保できます。
ローカルLLMを使えば情報漏洩は防げますか
外部送信のリスクは減りますが、ゼロにはなりません。
自社環境で動かすローカルLLMは、入力データが外部サービスに送られないため、学習経由の漏洩リスクを抑えられます。機密性の高い業務には有力な選択肢です。
ただし、社内での不正アクセスや権限管理の不備による漏洩は残ります。導入する場合も、アクセス制御と運用ルールの整備は欠かせません。
生成AIの情報漏洩対策で安全な活用を実現しよう
生成AIで情報漏洩が起こる仕組みは、入力データの学習、サービスのバグ、アカウント窃取、従業員の意図しない入力の4つです。実際に大手電機メーカーの機密流出やChatGPTのバグ、アカウントの闇取引といった事例が起きています。
対策は、ガイドライン策定、入力禁止情報の明確化、学習オフ設定、法人プランの利用、DLPやCASBによる制御、従業員教育の6つを、ルール・技術・人の3面で組み合わせることが基本です。まずは学習オフ設定と入力禁止リストの周知から、今日着手できます。
仕組みを理解して対策を重ねれば、利用を禁止せずに安全な全社活用へ進めるでしょう。漏洩を恐れて使わせないままでは、競合に業務効率で差をつけられてしまいます。
対策を固めた次は、現場が迷わず使えるよう社内ルールを運用に乗せ、活用を定着させる段階に進みましょう。安全な土台があってはじめて、生成AIは事業成果につながる武器になります。
出典・参考リンク
- OpenAI「March 20 ChatGPT outage: Here’s what happened」 https://openai.com/index/march-20-chatgpt-outage/
- Group-IB「Group-IB discovers 100,000+ compromised ChatGPT accounts on dark web marketplaces」 https://www.group-ib.com/media-center/press-releases/stealers-chatgpt-credentials/
- 個人情報保護委員会「生成AIサービスの利用に関する注意喚起等について」 https://www.ppc.go.jp/news/careful_information/230602_AI_utilize_alert/
- NRIセキュアテクノロジーズ「生成AIのリスクを整理する|3つの観点でリスクと対策を解説」 https://www.nri-secure.co.jp/blog/generative-ai-risks
- NTTデータ「情報漏洩?企業における生成AI活用の落とし穴」 https://www.nttdata.com/jp/ja/trends/data-insight/2025/0703/



























