

こんにちは、ぱるです。みなさんの中で、「自然言語処理って何?」という質問に自信を持って答えられる人はどれくらいいるでしょうか?
よくわからないけど、つまり言語に関連したAIでしょ?なんて思っている方も多いのではないでしょうか。もし、自然言語処理という言葉を一度も聞いたことがない、という方でも、日常生活においてこの技術に全くお世話になったことがない人はほとんどいないと思います。例えば、コンピュータでキーボードを使ってかなを入力した後に漢字交じり文へ変換を行う、「かな漢字変換」や英語の文を翻訳するために「機械翻訳」を利用したことはありませんか?
このように、みなさんにとって自然言語処理はとても身近な技術で、気づかないうちに日常生活に多大な恩恵を与えているのです。
ということで、今回はみなさんにこの記事を読んでいただくことで、自然言語処理をもっと身近なものに感じ、「自然言語処理とはね・・・」と語れるくらいになっていただきたい、と思います!
自然言語とは
そもそも、自然言語とは何のことでしょうか?実は、読んで字のごとく、「私たち人間が日常書いたり話したりしている日本語や英語のような、自然な言語のこと」です。そして、これと対比した言語が、プログラミング言語です。この二つの言語の違いは、言葉の曖昧性にあります。自然言語には、文の意味や解釈が一意に決まらない曖昧性があります。例えば、以下のような例を考えてみてください。
「黒い目の大きい少女」
これは、少なくとも以下のような二通りの解釈が存在します。
- [黒い[目の大きい]少女]
→ 目が大きくて、肌が黒い少女 - [[黒い目の][大きい少女]]
→ 目が黒くて、体が大きい少女
このように、自然言語には言葉の曖昧性が存在していることがわかります。
確かに、日常的に会話してて、どっちの意味?って尋ねることは往往にしてありますね。
一方で、プログラミング言語でも同様に以下のような例を考えてみてください。
「4 * 6 + 1」
これは、「4と6を乗算したものと1を加算する」という一つの解釈のみしか存在しません。プログラミング言語は、コンピュータを制御するためのプログラムを記述する言語であり、コンピュータが同じ表現を常に同じように解釈して、同じように制御するような作りになっています。よって自然言語のような言葉の曖昧性が存在しません。
改めて、プログラミング言語とは、と考えてみると“自然”言語と対比する“人工”言語だったことがわかりました。確かに、同じプログラムを書いたのにコンピュータによって違う挙動になったら困りますね。
自然言語処理とは
以上のように、プログラミング言語とは異なり、自然言語には言葉の曖昧性が存在します。この言葉の曖昧性を踏まえて、自然言語を使って書かれた膨大なテキストデータを実用的に扱うために自然言語処理という技術が使われているのです。
人間でも意味をきちんと定義しにくい自然言語について、コンピュータに処理させるのはとても難しそうですね。しかし、それができたら言葉の曖昧性も解消できるのではないでしょうか?
では、これから自然言語処理の流れを簡単に説明していきます。
▼関連記事はこちら
・自然言語処理が学べる研究室12選!>>
・自然言語処理の本おすすめ16選!学習レベル・言語別に紹介!>>
・BERT(バート)とは?次世代の自然言語処理の凄さやできること・書籍を紹介>>
自然言語処理が注目される理由
自然言語処理は現在注目度が高まってきています。その理由として、SNS、AIスピーカー、チャットツールの普及などが考えられます。それにより、社会におけるテキストデータの量は一昔前より何倍にも増えました。この膨大なデータを処理するために、自然言語処理が重要な役割を担ってくると予想されています。
また、自然言語処理の技術自体も進化を続けており、今後自然言語処理が使われる場面は増えていくでしょう。
▶【図解】注目される自然言語処理 -episode 1->>
自然言語処理の仕組み
自然言語処理の仕組みを解説します。
自然言語処理はまず、言語処理の前段階として機械可読辞書とコーパスを準備します。そして、「形態素解析」「構文解析」「意味解析」「文脈解析」の順に進めていきます。
▶【図解】注目される自然言語処理 -episode 2->>
機械可読辞書とコーパス
初めに、言語処理を行う前段階として必要になるのが機械可読辞書とコーパスの構築です。
機械可読辞書とは、
「コンピュータが語彙を理解するときに必要な辞書のこと」
です。多くの場合、これは人間が使う一般的な辞書とは区別されています。
そしてコーパスとは、
「言語の使用方法を記録・蓄積した文書集合のこと」
です。コーパスの分析によって、状況に適した言葉の使い方や特徴を捉えることができます。近年では、コンピュータの処理性能や記憶容量が向上したことで、大規模なコーパスを利用した言語処理が行われるようになりました。
最近では、SNSなどによって気軽に個人の発言ができることや、日々大量の言葉のやり取りなども行われるようになりました。それらのデータを収集したらもっと大きなコーパスが作成できますね。
形態素解析
機械可読辞書とコーパスが用意できたら、ここからが言語処理の主な流れに入ります!(いよいよ)
まず初めに行われるのが、形態素解析と呼ばれる作業です。
形態素とは、
「文字で表記された自然言語の文において、意味を持つ最小の言語単位」
のことです。文は、形態素、または、複数の形態素から構成されています。
これだけ聞いてもよくわからないですよね。
では、実際に例を使って形態素解析が担う処理を見てみましょう!
形態素解析処理
例えば、先ほど挙げた「黒い目の大きい少女」というフレーズを考えてみます。
1.形態素で分割
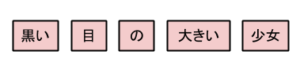
ここで行われているのは、先ほど説明した形態素という単位で、文を分割するという作業です。
こうすることで、
- 文の形態素分割 → 意味のある情報の取得
が可能になります。
このような、「文章において語の区切りに空白を挟んで記述する処理」は、わかち書きと呼ばれています。
一方で、今回は例として日本語の文を扱っていますが、英語の文を解析する場合は挙動が少し異なります。一般的に、英語の文は初めから単語間にスペースが設けられているため、日本語と比べると容易に単語分割の処理を行うことができます。このように、「単語分割」処理は言語によって少し違いがあります。
2. 形態素ごとに品詞を付与

ここで行われているのは、先ほど分割した各単語に適切な品詞を割り当てるという作業です。これによって、例えば、文章中から“名詞”のみを抽出してキーワードの集合を作ることが可能になります。
ここで、どれほど詳細な品詞を付与するかは、形態素解析器によって異なります。以下のサイトでは、JumanとChasenと呼ばれるメジャーな形態素解析器で使われている品詞体系についてまとめてありますので、気になる方はご覧ください。
3. 形態素ごとに語形変化の解析
ここでは、形容詞や動詞がどのように語形変化しているかについて調べています。この結果を辞書に当てはめることによって、より正確な単語分割結果が抽出できます。
例えば、“走る” が、 “走ります”という語形変化などがあります。
以上のような流れに沿って文の解析をし、形態素解析という処理が行われています。このように行われた解析結果は、一つに定まるでしょうか?実はそんなことはありません。以下の例を見てみてください。
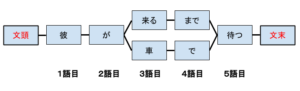
これは、「かれがくるまでまつ」という文について形態素解析を行った結果をグラフで表したものです。このように、結果としての候補が複数挙げられることは往々にしてあります。その中からどれが適切な形態素解析の結果としてふさわしいかを判断する方法はいくつか存在します。今回はその中から、「最長一致法」について説明します。
最長一致法
これは、「文頭から候補として挙げられた形態素を比較し、形態素が最長のものを優先する方法」です。例えば上記の「かれがくるまでまつ」という文では、3語目の文字数が多い「彼が車で待つ」が最適結果となります。
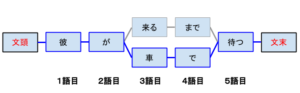
「最長一致法」以外にも「二文節最長一致法」、「形態素数最小法」などといったヒューリスティックな知識を用いた手法や、単語の共起関係について系統的に調べる手法などもあります。
構文解析(係り受け解析)
次に行われるのが、構文解析という作業です。係り受け解析とも呼ばれます。ここでは、形態素解析で得られた単語間の関係性について解析を行います。再び「黒い目の大きい少女」というフレーズを例として考えます。
上記で説明したとおり、このフレーズには二通りの解釈が存在します。これらを構文木と呼ばれる表現方法を用いて構文解析の結果を出力したものが下のようになります。
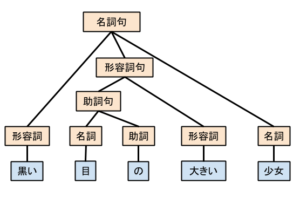
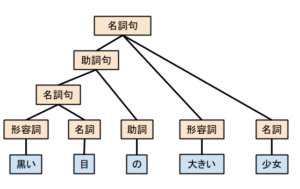
このように構文木を使うことで、単語間の係り受け関係が可視化され、文法的にどのような構造をしているのかを調べることができます。
意味解析
そして、構文解析をした文から正しく意味内容を解釈するために行われるのが、意味解析です。先ほどまでのように、構文解析の時点では二つの構文木はどちらも正解となり、一つの文に対して解釈の仕方が複数存在することになります。この中から正しい解釈を選択するために、意味解析はとても重要な処理なのです。
意味解析を行うためには、“意味”という概念がわからないコンピュータに、プログラムを使ってうまく自然言語文の意味を表現する必要があります。しかし、ある一つの単語にも意味は複数存在し、その複数の意味から、他の単語間とのつながりなどを考慮して適切な一つを選択しなければいけません。そのような処理によって、候補となった複数の構文木から正しい1つに絞ることができるのです。
文脈解析
最後に行われるのが、文脈解析です。これは、複数の文に対して形態素解析と意味解析を行い、文を超えたつながりについて分析します。文脈は、文章中に現れる語の関係や文章の背景に隠れた知識などといった複雑な情報が必要になるため、意味解析以上に難しい処理となっています。
このような難しさが未だ存在していることから、文脈解析を行うシステムはまだ実用化されていません。
ここでは、この文脈解析を行うための解析について紹介します。
照応解析
照応解析とは、代名詞や指示語などといった照応詞の指示内容の推定や、ゼロ代名詞と呼ばれる省略された名詞句を補完する処理のことです。
まず、照応詞について説明します。
例えば、「太郎はスーパーに行った。そこでお菓子を買った。」という連続した文を考えてみてください。
二文目で使われている、“そこ”という指示語は何を指しているでしょうか?これは明らかに、一文目で出てきた、“スーパー”を指しているとわかると思います。このような前にでてきた情報を指す指示詞や代名詞のことを照応詞といいます。

次に、ゼロ代名詞について説明します。
例えば、「今日花子はいつもより早く家についた。しかし、夕食を食べなかった。」という文について考えてみましょう。
二文目では、“夕食を食べなかった”の動作主である“花子”が省略されています。このように、日本語では主語や目的語が明確な場合、頻繁に省略が行われます。この省略された名詞句のことをゼロ代名詞といいます。

談話解析
これまで単一の文や周囲1、2文に対しての分析を行ってきましたが、実際の会話は、対話や独話などと呼ばれる、いわゆる複数文によって構成され、成立しています。このような、関連した一連の文(談話)を対象にして、文のまとまり、文章の構造、意味などを解析する処理のことを談話解析といいます。
談話についての処理は、複数文の内容に加えて、状況や知識などの背景に隠れている情報を考慮する必要があるため、通常の文を対象にするより難しい処理となっています。
しかし、このような明示されていない、暗黙な情報をコンピュータに理解させるにはどうしたら良いでしょうか?文が複雑になればなるほど、この不明瞭な情報の認識は、人間にとっても困難なものとなります。
自然言語処理の手法一覧
自然言語処理には以下のような手法が使われます。
- 共起語解析
- トピックモデル
- 感情分析
それぞれ解説します。
共起語解析
まず、1つ目の手法は共起語解析です。
共起語は特定のキーワードと一緒によく使われる言葉です。つまり簡単に言うと、共起語解析とは、どんな言葉がよく使われているかを解析するという手法です。
例えば、「天気」という単語とよく使われている言葉を探すと「水位」「災害」「情報」などが上位に出てきます。これが共起語です。
共起語解析を通じてSEO等のコンテンツ内で共起語を使用するなど、Webマーケティングで活用されています。
トピックモデル
2つ目がトピックモデルです。
トピックモデルとは、文章のトピックを把握するための技術です。テキスト内の単語の数や、その単語が使われている頻度からトピックを判断します。
例えば、歴史がトピックだった場合、「過去」や「諸説」などといった単語が頻出すると考えられます。トピックモデルではこの考え方の逆の作業を行っていると考えるといいでしょう。
こちらの技術も、SEOやニュース記事のタグ付けなどに使われ、Webマーケティングで活用されています。
感情分析
3つ目は感情分析です。
感情分析は、その言葉の通り、テキスト内の単語から文章全体の感情を分析することです。
「悲しい」「嫌い」などの単語が多い文章はネガティブ、逆に「面白い」「好き」といった単語が多ければポジティブだと判断されます。
自然言語処理でできること
自然言語処理でできることを紹介します。主に以下の3つが挙げられます。
- 機械翻訳
- 対話システム作成
- 予測変換
それぞれ解説します。
▼関連記事はこちら
・自然言語処理でできることまとめ|活用事例からpythonとBERTでの使い方を解説>>
・Pythonを使った自然言語処理でできること – ライブラリ・本なども紹介>>
機械翻訳
まず1つ目は機械翻訳です。
機械翻訳とは、人の手を介さず機械が自動で翻訳することです。機械翻訳自体はAIが登場した時期から使われていましたが、近年AIの発達に伴い、機械翻訳の技術も向上しています。
身近な例では、グーグル翻訳がこれに当たり、難しい用語や言語ごとのニュアンスの違いも含めて翻訳が可能となってきています。
対話システム作成
2つ目が対話システムの作成です。
対話システムでは、人間同士が行うような会話をコンピュータで実現できます。これは人間同士の会話を大量のデータとして学習させることで、どんな会話でもある程度自然な応答を自動で生成し、応えられるようになりました。
対話システムの身近な例の1つである対話形式アシスタントでは、スマートスピーカーに問いかけると明日の天気を調べてくれたり、照明を暗くしてくれたりと、様々な指示を出すことが可能です。
また、この技術は最近開発されたChatGPTにも使われ、自然な会話ができるように設計されています。
予測変換
3つ目が予測変換です。
予測変換はとても身近に行われてます。例えば、今使っているスマートフォンやパソコンで「しちょう」と打ち込むと「視聴」「市長」「試聴」など、さまざまな予測変換が出てくるでしょう。
この技術も自然言語処理が使われています。
自然言語処理の活用事例
次に、自然言語処理の活用事例を紹介します。
- 自動応答
- あいまい検索・類似文書検索
- テキストマイニング
それぞれ解説します。
▼関連記事はこちら
・【自然言語処理活用事例】作業の効率化、感情理解をする>>
・既に人間を超えた?機械読解技術の今と未来>>
・1番構ってくれるLINEチャットボットはどれ!? 実際にチャットボットに甘えてみた!>>
AIスピーカーの自動応答

(出典:https://www.biccamera.com/bc/i/topics/osusume_smart_speaker/index.jsp)
自然言語処理はAIスピーカーやチャットボットの自動応答に活用されています。有名なものだとGoogleアシスタント、Alexa、Siriなどが挙げられます。
▶【2023年版】対話型AIとこれからのビジネス実用例5選>>
あいまい検索・類似文書検索
(出典:https://swingroot.com/google-search/)
近年では、GoogleなどWeb上の検索サイトでうろ覚えのキーワードや文章を入力しても期待した検索結果になる確率が上がってきています。
これは自然言語処理を活用することで可能になりました。
テキストマイニング
テキストマイニングは、コールセンターへのクレームや問合せ、顧客アンケートの自由記述、SNS等に投稿されている文章などの大量のテキストデータを解析し、有益な情報を抽出することに活用されています。
自然言語処理は、このツールに欠くことのできない機能です。テキストマイニングツールでは自然言語処理によって文章を単語に分割・分類することで、単語間/文章間の関係性や出現頻度などの分析を行います。
今後の課題
自然言語処理はこれまで発展を続けてきました。しかし、まだ精度は完璧ではなく、言語ごとに処理技術も異なります。
今後はこれらの精度、そして言語ごとの技術の差という課題を解決していく必要があります。
▶【図解】注目される自然言語処理 -episode 3->>
まとめ
このような曖昧な情報をうまく形式化することができれば、そのままプログラムに組み込むことができるため、意味解析や文脈解析の精度が上がり、自然言語処理全体の性能が向上すると考えられています。このようなことは、形式意味論、形式語用論などの基礎研究に関連しています。これらは言語学と呼ばれる分野に存在し、言葉というのはそれほど単純なものではないという概念と向き合っています。全て深層学習を使えばなんとかなるだろうという考えだけでは、達成できない部分に対して、これからは「人がどのようにして言葉を理解しているのか」という形式的な追求をしていくことが重要なのです。
このように自然言語処理は大きく分けて4つの分析を経てようやく達成される大規模な技術であり、これを達成するためには深層学習だけでなく、言語学や統計学などの様々な分野が密接に関係していることがわかりましたね!文系だし、自然言語処理なんて、結局AIでしょ?なんて思っていた方も、少しでも興味を持っていただければな、と思います。

















