※本稿は、NABLAS株式会社による寄稿です。
目次
1 社会への影響とフェイク検知技術
1.1 ディープフェイクに関係する事件
ディープフェイク技術の進化は、高度な技術がなくても、プログラミングやPC の操作が一定以上できる人であれば、架空の動画や画像などを作成することを可能にした。技術の民主化により、今までは困難であったような創造的な活動について個人レベルで可能になった一方で、無許可で有名人のポルノ動画を作成するなど、一部の人々を貶めるような悪質な事件・犯罪も発生している。ここでは、その一部について紹介する。
1.1.1 Reddit でのポルノ動画事件
2017 年12 月、”Deepfakes” というのハンドルネームのReddit ユーザーがインターネットにいくつかのポルノ動画を投稿した[1]。女優やアーティストを題材にしており、社会に大きな衝撃を与えましたが、ほどなくして偽物と判明した。この事件は、「ディープフェイク」という言葉が広まるきっかけにもなった。
1.1.2 エネルギー会社CEO なりすまし事件
2019 年3 月に、英国のエネルギー企業が音声のディープフェイク技術によって多額の詐欺被害に遭った。このエネルギー会社のCEO は、電話で22 万ユーロ(約2600 万円)を至急送金するようにドイツの親会社のCEO から求められたので、その通りに振り込んだところ、実はこれは音声クローンの技術を利用した詐欺師からの指示であったことが判明した。この事件を調査した保険会社によると、ドイツ話者の訛りや発音などが再現されており、合成された音声であると気づけなかった、と報告されている[2]。
1.1.3 日本のフェイクポルノ動画事件
2020 年10 月、熊本市の大学生と兵庫県のシステムエンジニアがディープフェイク技術を使い、芸能人の顔を合成したポルノ動画をインターネットに投稿した容疑で逮捕された[3]。動画1本あたり3万枚の画像を訓練に利用し、1週間ほどモデルを訓練して作成されたと言われている。この事件は、日本でディープフェイク技術が悪用された初めての刑事事件だと考えられている。
1.1.4 ペンシルバニア州のチアリーダー・フェイク動画事件
2021 年3 月10 日、ペンシルバニア州で、チアリーダーとして活動する高校生の娘のチームメイトを陥れるために、全裸で飲酒し、喫煙している写真や動画をディープフェイク技術を用いて捏造し、チームメイトやコーチに送った母親が逮捕された[4]。さらに、地方検事官の告発によると、この母親は犠牲者である娘のチームメイトに、自殺を促すようなメッセージを匿名で送っていた。判決文を引用した報道によると、娘は母親がそのような犯行をしていたことを一切知らなかった。
1.2 官房長官フェイク画像拡散事件
2021年2月に福島県と宮城県で震度6強の地震が起きた際、当時の加藤官房長官が記者会見に臨んだ。
その際、笑顔で会見をしているように映像が不正に改変され、Twitter上で拡散されるという事件が発生した。実
際の映像には官房長官は笑顔で対応している画像はなかったが、記者会見からたった30分後に公開されたツイートだったために、疑う人も少なく、一気に拡散されてしまった。
その結果、「不謹慎である」「許せない」といった批判のコメントが多数集まる結果となり、大きな問題となった。ディープフェイク技術の進化は、精巧な画像や動画を作れるというだけでなく、簡単かつ迅速に公開できてしまうという点も大きな問題であることを示唆する事件となった。
1.3 eKYC突破に関する論文
2021年6月に日立の研究グループから発表された論文が関係者の間で大きな注目を集めた。
その論文は、オンラインで本人認証のために利用されているeKYCシステムがディープフェイク技術によって突破できることを技術的に証明し、セキュリティ関係者に警笛を鳴らす内容であった。
もともと、銀行などの窓口業務では身分証と本人の顔を照合するKYC(Know Your Customer)という方法によって本人認証がなされていた。オンラインで完結するeKYC(electronic Know Your Customer)は、2018年11月の施行規則改定により法正式な本人認証手続きとして法的に許可された。
その後、COVID-19 の状況下の元、非対面での窓口業務に対するニーズが高まり、一気に広がっていた状況の中であったため、この論文が関係者に与えた衝撃は大きなものであった。
1.4 フェイク動画の検知技術
年々ディープフェイク技術が高度化する中で、動画や画像が本物か偽物かを人間が見て判断することが困難になりつつある。一方で、ディープフェイク技術に対抗して、ディープフェイクによって作成されたコンテンツを検知する技術も発達してきている。ここでは、フェイク動画の検知技術の概要と、いくつかの先進的な取り組みについて紹介する。
1.4.1 検知技術の概要
ディープフェイク技術によって作られたフェイク動画は、よく見ると不自然な部分や、合成した部分につなぎ目があったり、不自然な点が残っていることが多い。このような不自然な点は、「アーティファクト」と呼ばれ、フェイク動画かどうかを判定するための手がかりとして利用される。
アーティファクトを利用してフェイクを検出する方法は大きく大別すると、1)人間が目に見えるアーティファクトを手がかりにして、自動的に検出するためのロジックを手動で作成する方法と、2)ディープラーニング技術などを利用して自動的にアーティファクトを検出し、フェイクの検出に利用する方法の2つの方法がある。
フェイク動画に出現するアーティファクトとしては、以下のようなものがあることが知られている。
- 唇の動きと音声の不一致(矛盾)に着目[5]
- 眼の色彩や光の反射の消失、眼や歯の部分的な消失[6]
- 顔の表現や、頭の動きに着目した方法[7]
- 頭の動き:顔部分の特徴のみで算出した3Dの動きと、顔全体の特徴で算出した3Dの動きを比較[8]
- 表情:頬の上がり方の動き、鼻のシワ、口のストレッチ[9]
- まばたきのパターン、回数[10]
また、上記のようなアーティファクトに注目する方法に加え、頭の動きに着目し、顔部分の特徴のみで算出した3Dの動きと、顔全体の特徴で算出した3Dの動きを比較する方法 [49] や、顔の表現や、頭の動きに着目した方法 [48] などがフェイクの検出において有効であることが知られている。
次に、ディープラーニング技術などを利用して自動的にアーティファクトとなるような特徴量を抽出する手法として、2 つの事例を紹介する。1つ目は、顔の変換処理に利用されるモデルは、多くの場合解像度に限界があり、特定の解像度(例えば 256 x 256 など)でしか出力できないという仮定に基づく方法だ。
現実的にはこの仮定(制約)は、多くの場合で正しく、顔の入れ替えの際には、後処理によってどうしても入れ替えの痕跡が残る。そのような痕跡をディープラーニングのモデル(ResNet)などに学習させるために、顔領域およびその外周領域についてデータをサンプリングし、フェイク動画を検知するために有効なアーティファクトを発見する。この手法も、良い性能を出している。
また、目に見えない特徴量を利用する方法も研究されている。もともとは、テロリストなどが画像や音声の中にデータを秘匿することがあり、そのデータを分析して犯罪を防止する目的で生まれた技術だが、ディープフェイクの検知技術としても利用されている。
1.4.2 Microsoft Video Authenticator
Microsoft Video Authenticator は、フェイク動画検知のためにMicrosoft 社が2020 年に開発したソフトウェアだ。画像や動画を解析して、ディープフェイク技術によって発生する、人間の目では認知しづらいレベルの色あせやグレースケールなどを検出し、ディープフェイク技術による編集が行われたかどうかを判定する信頼スコアを算出する。このスコアをもとに、フェイク動画かどうかを判断することができる[11]。
1.4.3 DeepFake Detection Challenge
2019 年9 月に、AWS 社・Facebook 社・Microsoft 社などの大手IT 企業や学識経験者などが協力し、DeepFakeDetection Challenge (DFDC) と呼ばれるプロジェクトを立ち上げた[12]。このプロジェクトの目的は、世界中のエンジニアや研究者が、ディープフェイク技術などで操作されたメディアの検出に役立つ技術を生み出すことだ。世界中のエンジニアや研究者が集まって機械学習やデータサイエンスの技術を競い合う、「Kaggle」というサービスの中で、コンペティションとして開催された[13]。12 月にコンペティションはスタートし、最終的に2,000 人以上の参加者が集まり、このチャレンジのために作成された独自の新しいデータセットを使ってモデルの訓練と検証を行った。参加者は、AI によって作成されたフェイク動画を見破るようなモデルを設計し、そのモデルの精度を競った。
1.4.4 Pindrop 社- 音声通話の不正検知
Pindrop 社は、電話の音声データを分析して、企業や個人が電話詐欺に遭うことを防ぐ、音声解析に特化したセキュリティ企業だ。Pindrop 社は、年々高度化する音声通信による詐欺に対応した、本人識別・不正検知のためのソリューションを提供している[14]。ディープラーニング技術を利用して、音声のディープフェイク技術を検知する技術を確立しており、成果をあげている[15]。

図1 Microsoft Video Authenticator[11]
2 生成ディープラーニングの社会実装
ディープフェイクの技術と、その進化に大きく貢献した生成ディープラーニングの技術は、使い方によっては悪用されかねない技術であることは本稿で繰り返し説明してきた通りだが、同時に大きな産業的可能性を秘めた技術でもある。今後、この技術領域においてはさらに多くの製品やサービスが生まれると予想される。本節では、既に市場に投入されている製品・サービス、近いうちに投入される予定の技術について、紹介する。
2.1 NVIDIA 社- Maxine
2020 年10 月、NVIDIA 社はAI 技術を活用したビデオ会議プラットフォーム「Maxine」を発表した。NVIDIA 社の発表によると、Maxine では内部的にGAN を利用して圧縮したデータを復元しており[17]、ビデオ会議ソフトウェアに必要な帯域幅(通信データ量)を約10 分の1 に削減することが出来る。Maxine は、入力として動画を撮影・送信する代わりに、送信元のビデオから抽出されたキーポイントの集合を抽出する。このデータは、通常の動画よりもはるかに小さなデータとして表現できるため、通信量を大幅に削減することや、より多くのフレームを送信することなどが可能となる。受信側では、GAN を利用して、キーポイントの集合から元の顔画像を再構成する。Maxine のような技術は、ネットワーク帯域幅が限定されているような環境下でも、高いビデオの品質で通信できるため、オンライン会議の急増によって逼迫している通信帯域の問題を解決できる可能性を秘めている。
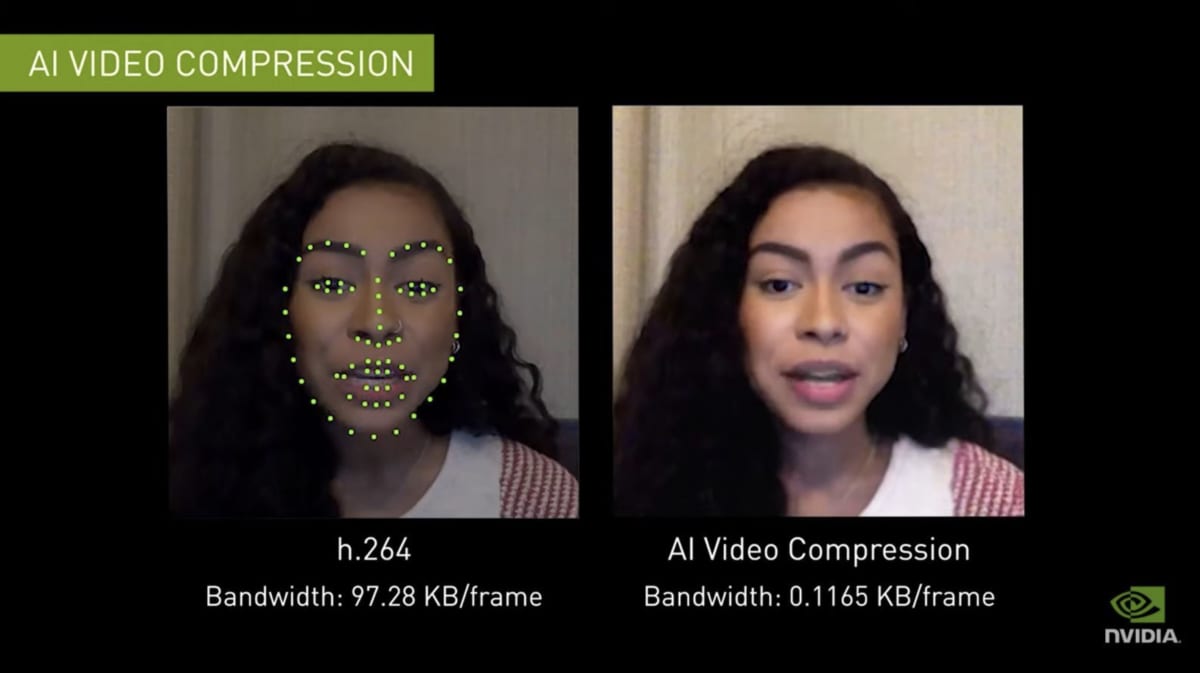
図2 従来のビデオ圧縮技術とMaxine の帯域幅の比較[16]
2.2 Descript 社- Overdub
Descript 社は、1 分間のサンプル音声さえあれば、その音声で任意の内容を発言させることが可能な音声クローニング技術「Overdub」を公開・提供している[18]。Descript というポッドキャスト用のツールの一部として提供されており、主な用途としては、配信用に録音した音声の一部を編集したり、音声を追加するような利用方法が想定されている。元々はモントリオールに拠点を持つLyrebird というベンチャー企業が開発していた技術だが、現在はDescript 社に買収され、AI 研究部門として技術開発を続けている。
2.3 Generated Media 社- Generated Photos
「Generated Photos」は、Generated Media 社が提供するサービスで、GAN によって生成された架空の人物画像が10 万点以上ダウンロード可能だ。写真を確認すると、人間が見ても生成された画像であることを判別することは非常に難しいほど高い品質の顔画像が生成できていることがわかる。架空の人物の顔画像を生成する技術は、肖像権の面で自由度が高いため、アバターのプロフィールやゲームキャラクターの生成など、産業的に様々な応用が期待されている。内部的には、顔生成(Entire Face Synthesis)技術としてStyleGAN が利用されている。
2.4 GAN による人工歯のデザイン
カリフォルニア大学バークレー校とGlidewell Dental Lab は人工歯をデザインするGAN を共同で開発した[20]。新しい人工歯を制作する際には、出来上がった人工歯が患者の歯列にフィットし、噛み合わせもうまく機能し、かつ美しくなければならないなど、多くの要件を同時に満たす必要がある。そのため、通常は何年もトレーニングを受けた技術者が担当するような、専門性の高い難しい作業となる。設計支援ツールの導入によって人工歯のデザインの負担を少なくできるものの、歯科医がデザインを評価し、調整する作業は未だに必要だ。新しいGAN を利用した手法では、人間が得た知識からだけではなく、反対の歯との空間も考慮し、自動的に設計することが可能だ。失われた歯と、反対の歯の間のスペースを考慮して設計することは、歯科医にとっては難しい作業となるが、良い噛み合わせを実現する上では重要な要素で、最終的に出来上がる人工歯の質に大きな影響を与える。発表された研究結果によると、GAN 技術で作った人工歯の方がより患者の口に合い、噛み合わも良いとの結果が報告されている(図における赤い部分は反対の歯とぶつかってしまう部分を示している)。
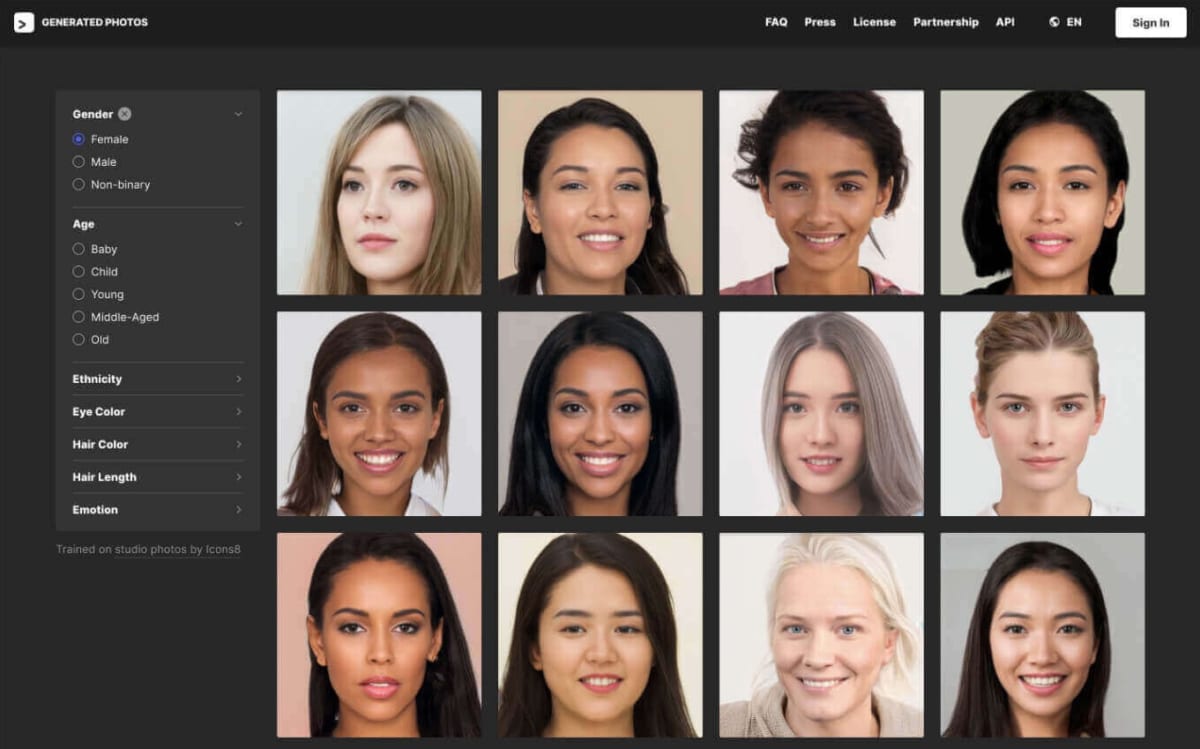
図3 Generated Photos[19]
2.5 デザイン・芸術への応用
生成ディープラーニングの技術は、デザインや芸術の制作工程に大きな影響を与える可能性があると言われており、既にこのような技術を利用した作品を目にする機会が増えてきている。本節では、デザイン・芸術に関係する技術のうち、既に身近な存在となっている事例をくつか紹介する。
1つ目の事例は、Preferred Networks 社が開発した「PaintsChainer」[21] だ。PaintsChainer は、モノクロの線画に対して自動で着色する技術で、内部的にはPix2Pix に似た構造を持つニューラルネットワークで構成されている。入力された線画からカラー画像を生成するような問題を考えた際に、技術的に難しいのは、正解が一意に決まらない、という点だ。着色の方法は無数にパターンがあり、例えば青に着色されているところを赤と着色しても間違いではないことが多々ある。このように正解が一意に決まらない場合、従来の手法では良い出力を得られるようなモデルを作ることが難しいという問題があったが、PaintsChainer ではGAN を導入することで、Descriminator が「本物らしいか」を判断し、生成器がより自然な着色画像を生成するように、敵対的に訓練するモデルを構築して解決した。本技術は、モノクロの漫画をカラー版に自動で変換して配信するサービスに利用されている(PaintsChainer は2019 年11 月にピクシブ社の運営へ移行し、Petalica Paintとして運営されている)。
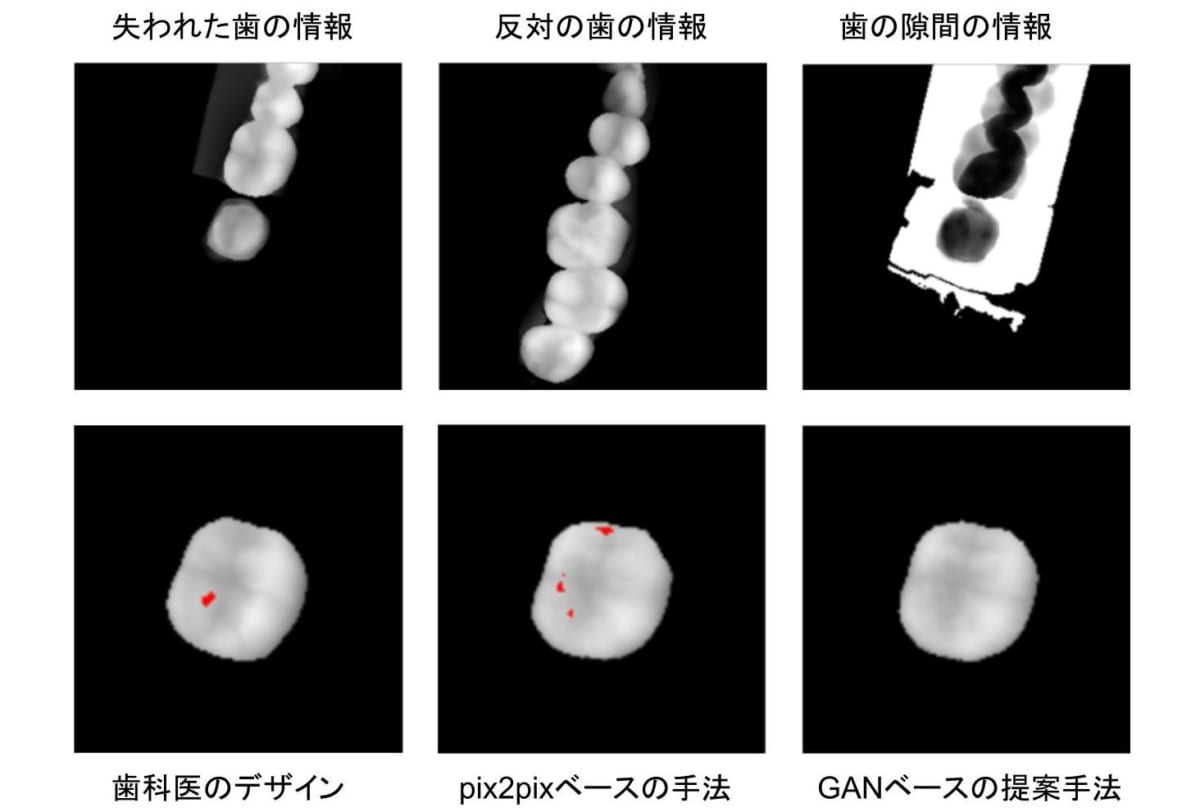
図4 失われた歯のデザインに関する歯科医と提案手法の比較[20]
NVIDIA 社の報告によると、2019 年に一般公開された際には一ヶ月で50 万枚の画像が作成された。内部的には、SPADE[24] と言われるGAN のモデルが利用されている。各種のアートワークの風景部分は自動で作成しつつ、前景部分の作成に集中できるような製作のプロセスが可能になると期待されている。作成できる画像は限定的であることや、実用性の面で課題もあるが、今後、このような技術が高度化していく中で、より幅広い製作、各種の映像製作の工程が効率化されることなどが期待されている。
2.6 工業製品検査への応用
生成ディープラーニングの技術の多くは、本物のデータが持つ分布に近いデータ(本物に近いデータ)を作り出すことを目的とするが、その内部処理には、本物のデータに近いかどうかを判定するロジックが含まれている。これをうまく利用することで、本物のデータに近いかどうかを数値化したり判定することなどが可能となる。今まで観察してきたデータの特性から離れた特性を持つデータを発見する技術は、「異常検知」と呼ばれ、工業製品の検査工程などで利用できる。
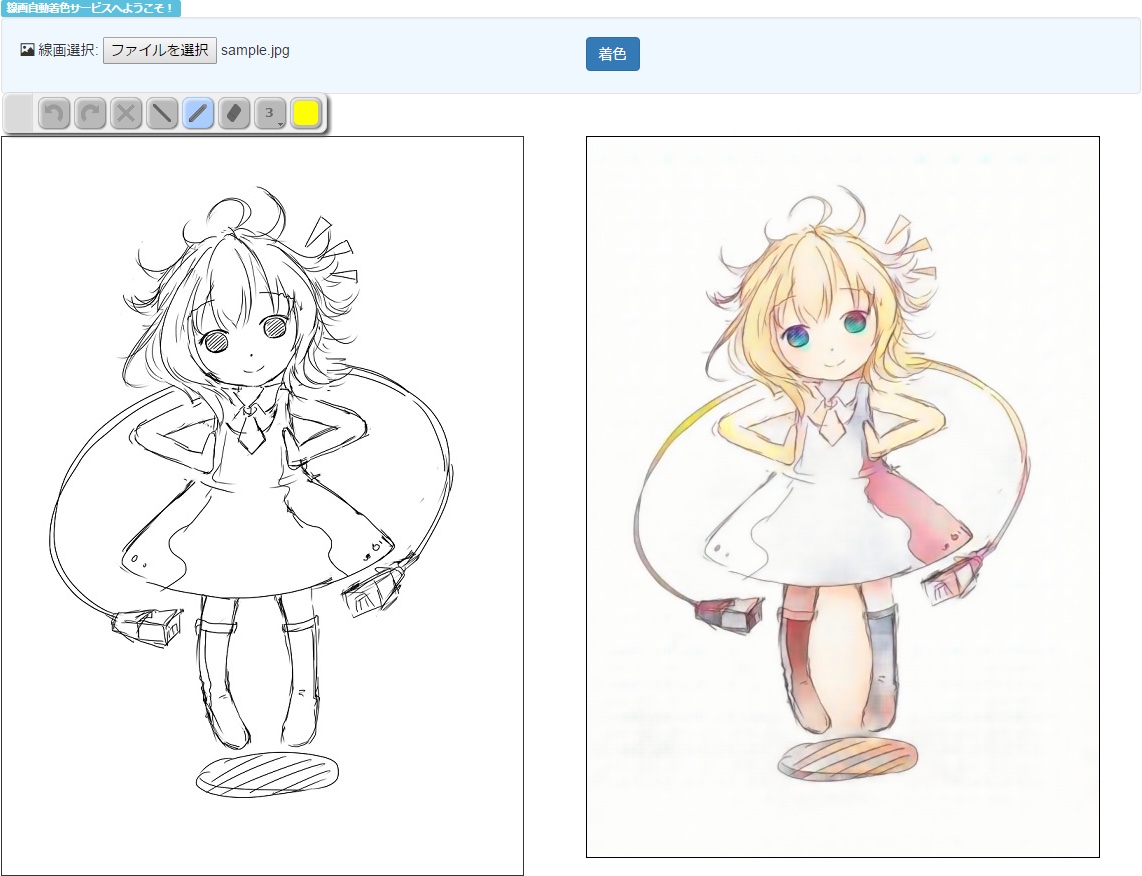
図5 PaintsChainer で自動着色した画像[22][21]

図6 GauGAN[23]
AnoGAN では、まず正常な製品のみのデータを大量に利用してGAN のモデルを訓練し、正常な製品のパターンや特徴を把握することで、本物(正常品)に近いデータを生成できるようなモデルを構築する。次に、検査対象のデータ(画像)を入力とし、先に訓練したGAN のモデルを通じて画像を再構成する。この際、傷や不具合など、今までに見たことの無いパターンが含まれるデータは、うまく生成できないので、元の画像と生成された画像の差分を取ることで、異常品であるかを判定することや、異常を含む可能性が高い部位を検知すること、異常度などの数値を算定することなどが可能になる。
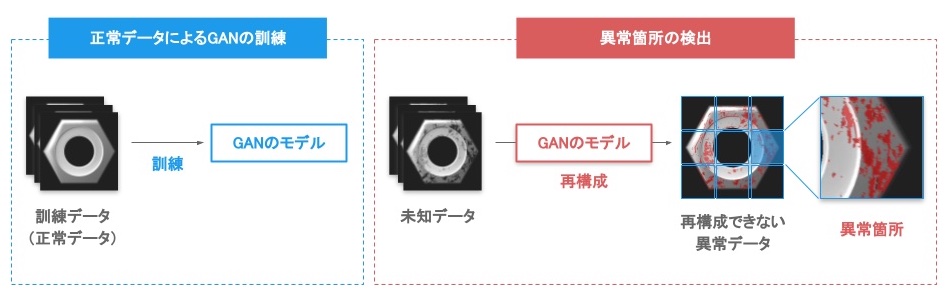
図7 AnoGAN による異常検知の発見[25]
3 まとめ
本ワイトペーパーでは、近年AI 犯罪の中でも最も深刻な脅威の一つとなりつつあるディープフェイクおよびその基盤となっている技術について解説した。ディープフェイクの技術は年々高度化しており、もはや人間が眼で見て判別することは困難なレベルの高い画質の画像が生成できるようになりつつある。実際、世界中ですでにいくつも悪質な事件が発生しており、社会的な懸念は大きくなる一方だ。また、画像や動画だけでなく、音声をクローンする技術も進化している。しかし、Microsoft Video Authenticator のように、フェイクを検知する技術の開発も同時に進むと同時に、フェイク画像や音声による被害を防ぐためのサービス・プロダクトも開発されている。今後、ディープフェイクの技術開発は益々進化することが想定されるが、検知技術と共に、法整備やモラル教育など、社会としての基盤や対応のための仕組みづくりなどが重要となることが考えられる。
一方、ディープフェイクの進化に関係していた生成ディープラーニングの技術は、利用方法次第では大きな可能性を秘めた技術であり、様々な産業に大きな変革をもたらす可能性がある。実際、データ圧縮・復元、デザイン・芸術への応用、工業への応用、異常検知への応用など、すでに様々な基盤技術やプロダクトが開発されている。
今後、様々な分野でAI 技術が産業の構造を変え、社会に変化をもたらすと予想されている。その際に重要となるのは、表面的に理解して漠然と恐れたり期待するのではなく、できることや限界などを理解し、警戒するべきことは適切なレベルで警戒して対応し、活用するべきことは活用する姿勢ではないだろうか。このホワイトペーパーが、そのような技術的な限界や可能性などを知るきっかけになれば幸いである。
参考文献
[1] “Deepfakes: An Unknown and Uncharted Legal Landscape.” owards Data Science; https://towardsdatascience.com/deepfakes-an-unknown-and-uncharted-legal-landscape-faec3b092eaf, 2019.[2] “Fraudsters Used AI to Mimic CEO’s Voice in Unusual Cybercrime Case.” THE WALL STREETJOURNAL; https://www.wsj.com/articles/fraudsters-use-ai-to-mimic-ceos-voice-in-unusual-cybercrimecase-11567157402, 2019.
[3] “「ディープフェイク」脅威に 国内初摘発、海外被害も.” 日本経済新聞; https://www.nikkei.com/article/DGXMZO64577690S0A001C2CZ8000/, 2020.
[4] “Mother ’used deepfake to frame cheerleading rivals’.” BBC News; https://www.bbc.com/news/technology-56404038, 2021.
[5] P. Korshunov and S. Marcel, “DeepFakes: A new threat to face recognition? Assessment and detection.”2018, [Online]. Available: http://arxiv.org/abs/1812.08685.
[6] F. Matern, C. Riess, and M. Stamminger, “Exploiting visual artifacts to expose deepfakes and facemanipulations,” in 2019 ieee winter applications of computer vision workshops (wacvw), 2019, pp. 83–92,doi: 10.1109/WACVW.2019.00020.
[7] S. Agarwal, H. Farid, Y. Gu, M. He, K. Nagano, and H. Li, “Protecting world leaders against deepfakes,” 2019.
[8] X. Yang, Y. Li, and S. Lyu, “Exposing deep fakes using inconsistent head poses.” 2018, [Online].Available: http://arxiv.org/abs/1811.00661.
[9] T. Baltrusaitis, A. Zadeh, Y. C. Lim, and L.-P. Morency, “OpenFace 2.0: Facial behavior analysistoolkit,” in 2018 13th ieee international conference on automatic face gesture recognition (fg 2018), 2018,pp. 59–66, doi: 10.1109/FG.2018.00019.
[10] T. Jung, S. Kim, and K. Kim, “DeepVision: Deepfakes detection using human eye blinking pattern,”IEEE Access, vol. 8, pp. 83144–83154, 2020, doi: 10.1109/ACCESS.2020.2988660.
[11] “New steps to combat disinformation.” https://blogs.microsoft.com/on-the-issues/2020/09/01/disinformation-deepfakes-newsguard-video-authenticator/, 2020.
[12] “Think like the bad guys: An interview with cristian canton ferrer, ai red team lead.” https://tech.fb.com/dfdc/, 2020.
[13] “Deepfake detection challenge.” https://www.kaggle.com/c/deepfake-detection-challenge, 2019.
[14] “CALL center fraud prevention.” https://www.pindrop.com/solutions/anti-fraud/, 2020.
[15] T. Chen, A. Kumar, P. Nagarsheth, G. Sivaraman, and E. Khoury, “Generalization of Audio DeepfakeDetection,” in Proc. Odyssey 2020 the speaker and language recognition workshop, 2020, pp. 132–137,doi: 10.21437/Odyssey.2020-19.
[16] “AI-Powered Video Conferencing with NVIDIA Maxine.” NVIDIA; https://www.youtube.com/watch?v=eFK7Iy8enqM.
[17] “AI Can See Clearly Now: GANs Take the Jitters Out of Video Calls.” NVIDIA; https://blogs.nvidia.com/blog/2020/10/05/gan-video-conferencing-maxine.
[18] A. Mason, “Introducing Descript Podcast Studio & Overdub.” https://blog.descript.com/introducingdescript-podcast-studio-overdub/, 2019.
[19] “Generated Photos.” https://generated.photos/.
[20] A. A. E. Jyh-Jing Hwang Sergei Azernikov, “Learning beyond human expertise with generativemodels for dental restorations,” arxiv arXiv:1804.00064, 2018.
[21] 米辻泰山, “線画自動着色サービス「PaintsChainer」について,” 映像情報メディア学会誌, vol. 72, no. 5,pp. 353–357, 2018, doi: 10.3169/itej.72.353.
[22] Preferred Networks; https://github.com/pfnet/PaintsChainer.
[23] “GauGAN.” Nvidia; http://nvidia-research-mingyuliu.com/gaugan.
[24] T. Park, M.-Y. Liu, T.-C. Wang, and J.-Y. Zhu, “Semantic image synthesis with spatially-adaptivenormalization,” in Proceedings of the ieee/cvf conference on computer vision and pattern recognition, 2019,pp. 2337–2346.
[25] S. M. W. Thomas Schlegl Philipp Seeböck, “Unsupervised anomaly detection with generativeadversarial networks to guide marker discovery,” arXiv arXiv:1703.05921, 2017.
執筆者情報

| AI総合研究所 NABLAS株式会社の代表取締役所長。 |
『ディープフェイクと生成ディープラーニング Part.1|ディープフェイクを生み出した技術革新』はこちら
『ディープフェイクと生成ディープラーニング Part.2|ディープフェイクの作成プロセス』はこちら
駒澤大学仏教学部に所属。YouTubeとK-POPにハマっています。
AIがこれから宗教とどのように関わり、仏教徒の生活に影響するのかについて興味があります。