

画像出典:AI Index Report 2023表紙より
目次
はじめに
アメリカ・スタンフォード大学の研究組織HAI(Human-Centered Artificial Intelligenceの略称)は2023年4月3日、AIの現状を多角的に調査しAI Index Report 2023を発表しました。本稿では386ページと長大なこのレポートの記述にもとづいて、自然言語処理の世界的動向をまとめます。テーマとして自然言語処理を選んだのは、この技術が現在注目のChatGPTをはじめとする生成系AIを開発するものだからです。
自然言語処理の世界的動向をまとめるにあたっては、市場、研究開発、倫理、関係者の意識の4つのトピックに焦点を当てます。そして、これらのトピックを考察した後に自然言語処理における今後のトレンド予測を述べます。
各トピックのダイジェスト
以上のような考察は、以下の表のように4つのトピックごとに要約できます。なお、考察の詳細は各トピックの解説をお読みください。そして、自然言語処理のトレンド予測については、最終見出し「自然言語処理のトレンド予測」を参照してください。
以下の解説は、AI Index Report 2023のうち「第1章: 研究開発」「第2章: 技術的パフォーマンス」「第3章: 技術的AI倫理」「第4章: 経済」「第8章: 公衆の意見」を参考にしています。
|
トピック |
考察の要約 |
| 市場 | AI市場はコロナ禍の影響により投資額が減少したものも、おおむね成長傾向にあり、その成長をけん引しているのはアメリカと中国。自然言語処理は導入や開発が活発な技術。 |
| 研究開発 | 自然言語処理は研究分野としては相対的にマイナーであるものも、現在重要なAIシステムの多くは大規模言語モデル。同モデルにはまだ苦手な言語活動があるので大きな進化の余地がある一方で、さらに高度なモデルを開発するには莫大な資本が必要。開発時に二酸化炭素排出量抑制策も講じられるのが望ましい。 |
| 倫理 | AIをめぐる事件や論争が増加しており、AIの公平性とバイアスに対する対処が急務であるものも、AIの性能向上が必ずしも倫理的問題の解決につながらない。近年注目されるチャットボットには、ジェンダー設定への配慮や学習データの改善が求められる。 |
| 関係者の意識 | AIは世界の過半数から好ましく思われている現状において、自然言語処理の研究者は自身の研究の善性を固く信じる一方で、ベンチマークやモデルサイズを重視する研究に限界を感じているとともに、二酸化炭素排出量といった倫理的問題も意識している。 |
市場動向
自然言語処理の世界的動向を考察するにあたって、世界のAI市場における人材と資金の動きを確認してから、企業が自然言語処理にどのように取り組んでいるのかを見ます。
求人と資金の流れ
各国の全求人広告に対するAI求人の割合の推移を調査会社Lightcastのデータにもとづいてまとめたのが、以下のグラフです。各国とも2014年以降、AI求人広告が増加傾向にあります。2022年時点でもっとも多いのがアメリカの2.05%で、次いでカナダの1.45%、スペインの1.33%となります。
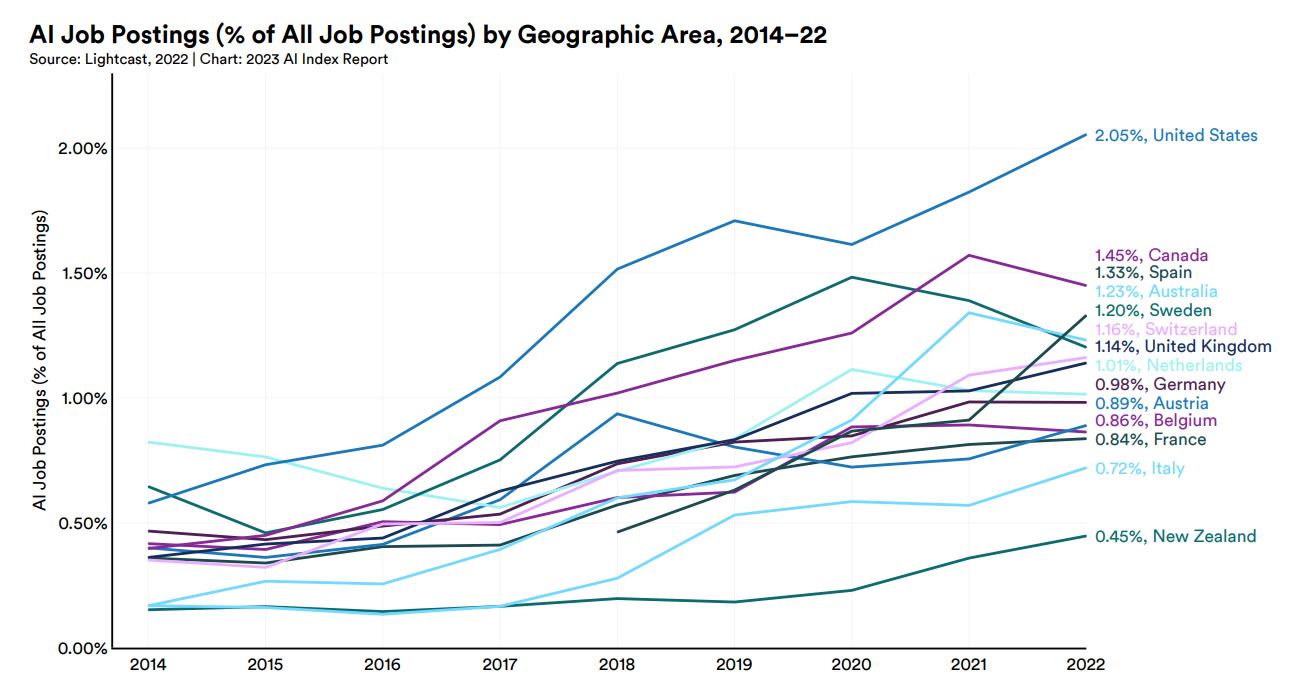
各国の全求人広告に対するAI求人の割合推移。画像出典:AI Index Report Chapter 4
世界のAI企業への投資額は、2013年から2021年まで増加してきましたが、2022年になってはじめて前年より減少しました。2022年の投資額減少は、大手テック企業を中心としたレイオフが関係しているかも知れません。それでも、最近10年間でAI企業への投資額は約13倍になりました。2023年は、激化する生成系AIの覇権争いにより投資額が再び増加に転じる可能性があります。
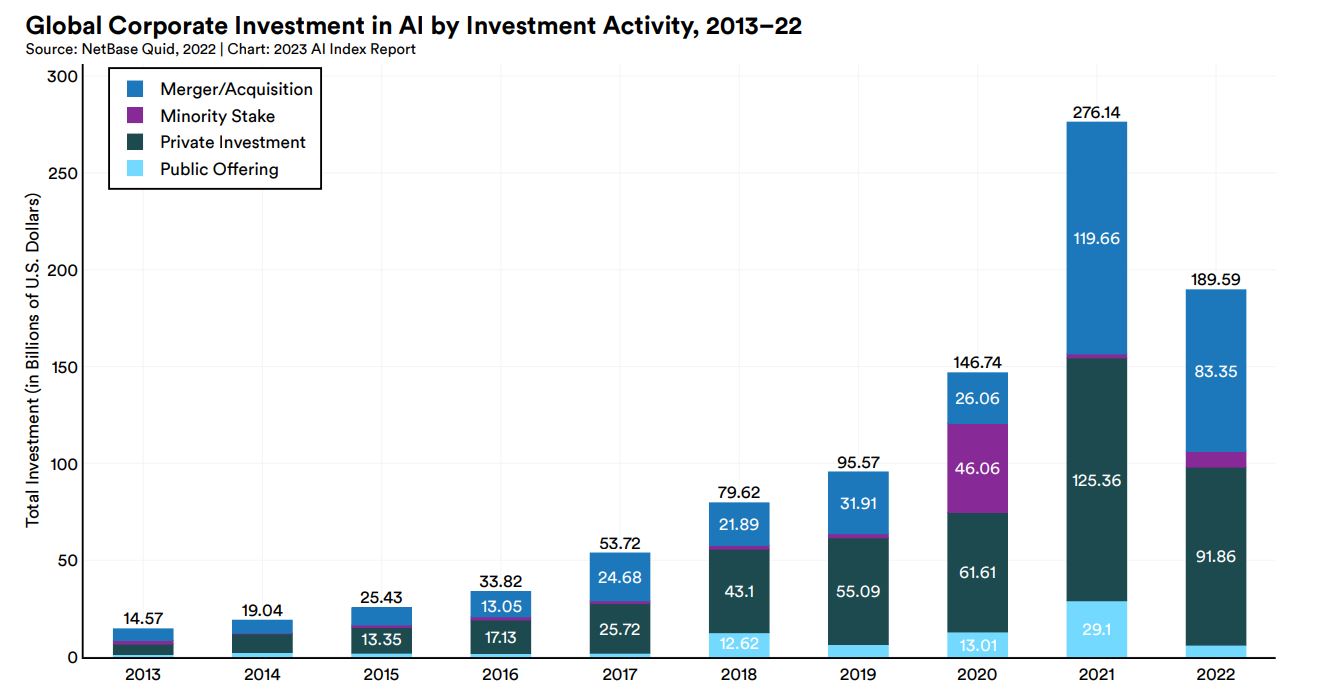
2013~2022年における世界のAI企業への投資額。画像出典:AI Index Report Chapter 4
2022年におけるAI企業への民間投資を各国別に見ると1位はアメリカで約474億ドルであり、2位は中国の134億ドル、3位はイギリスの44億ドルでした。日本は7億2千万ドルであり、韓国の31億ドルやシンガポールの11億ドルを下回っています。
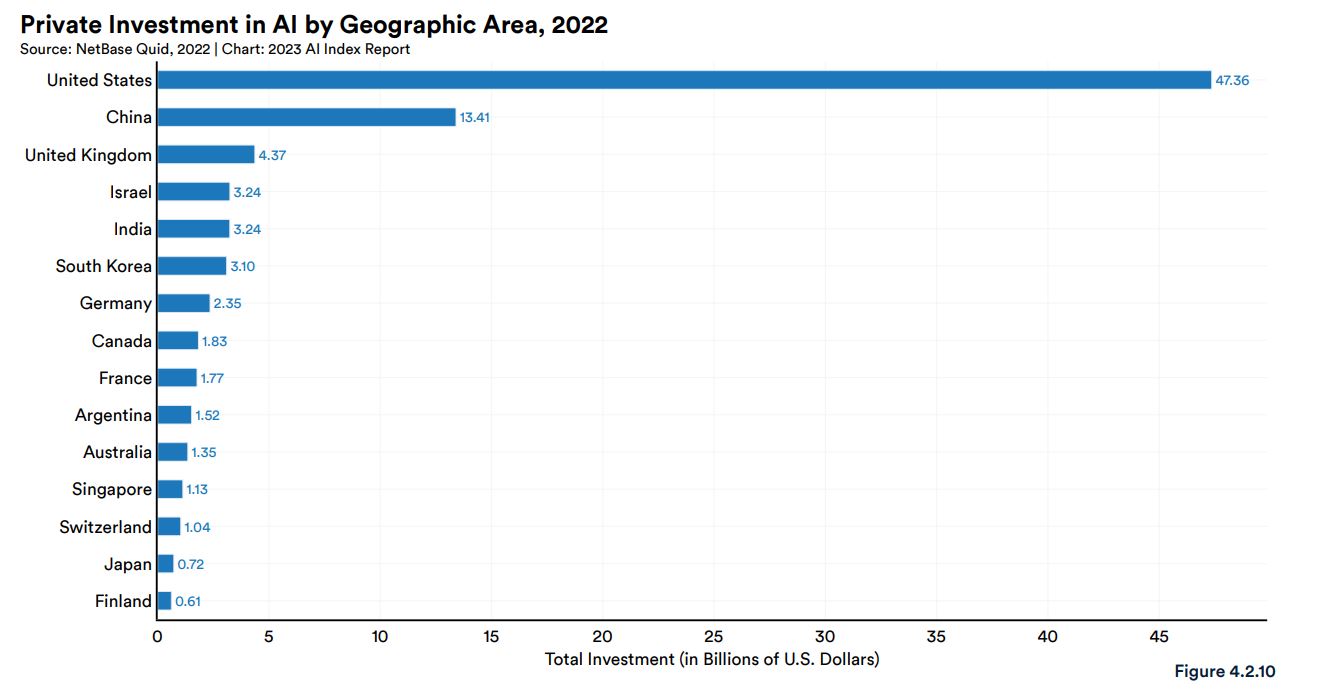
2022年における各国のAI企業への民間投資額。画像出典:AI Index Report Chapter 4
2022年における各国の新規資金調達したAI企業数は1位がアメリカの542社であり、2位が中国の160社、3位がイギリスの99社でした。日本は32社であり、36社のシンガポールを下回っていますが、22社の韓国を上回っています。
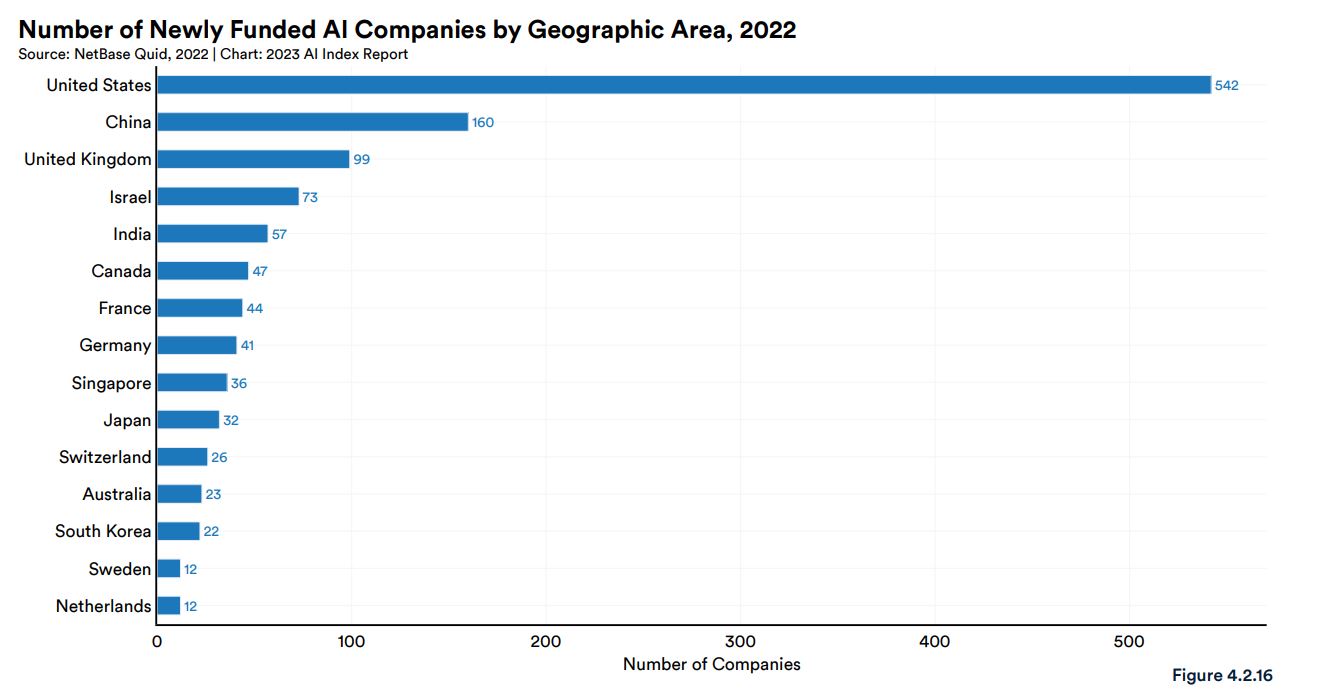
2022年における各国の新規資金調達したAI企業数。画像出典:AI Index Report Chapter 4
企業活動から見る自然言語処理
2022年において、企業が少なくとも1つの機能またはビジネスユニットとして組み込んだAI機能を分野別および業界別に見ると、もっとも組み込まれているのがロボティック・プロセス・オートメーションであり、調査した企業の39%が導入していました。次いでコンピュータビジョンの34%、自然言語テキスト理解とバーチャルエージェントが33%でした。
自然言語テキスト理解の導入率を業界別に見ると、金融サービスが42%、次いでハイテク/情報通信が40%、ビジネス・法律・専門サービスの34%でした。
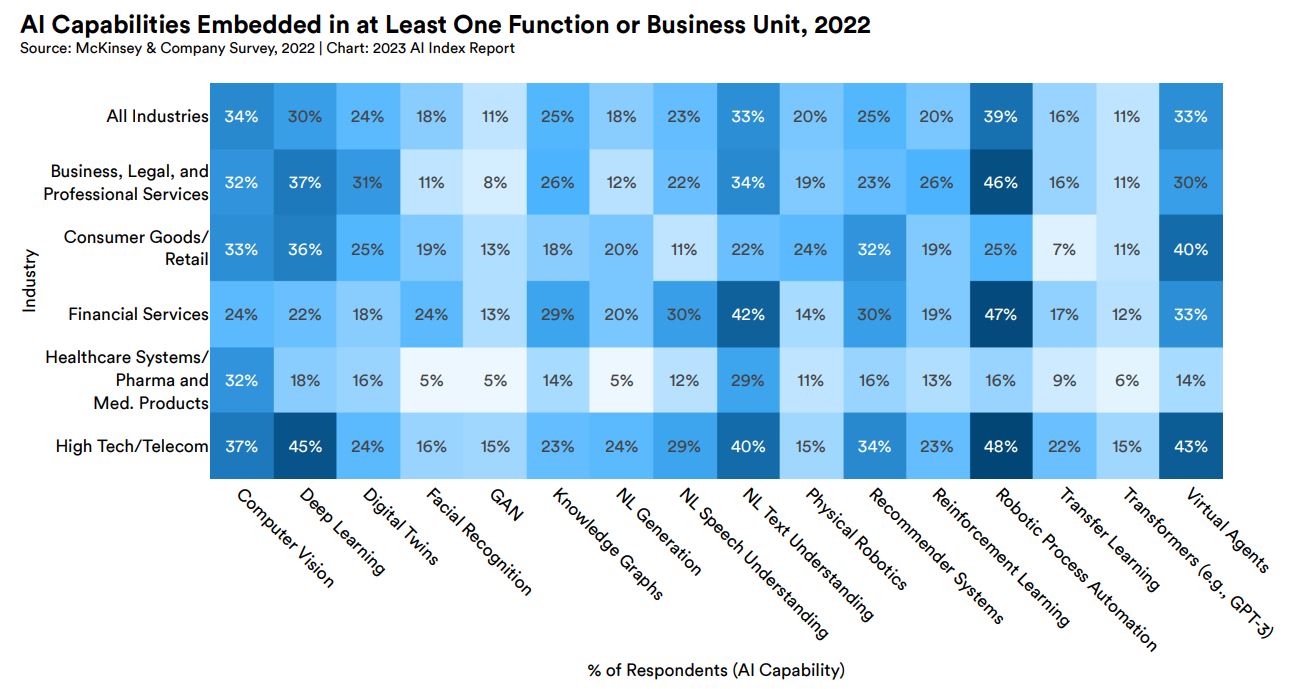
2022年における業界別に見たAI技術導入動向。画像出典:AI Index Report Chapter 4
自然言語処理を活用したサービスの代表である機械翻訳の提供数の推移を2017年5月から2022年7月までまとめると、9個から54個と6倍に増えました。
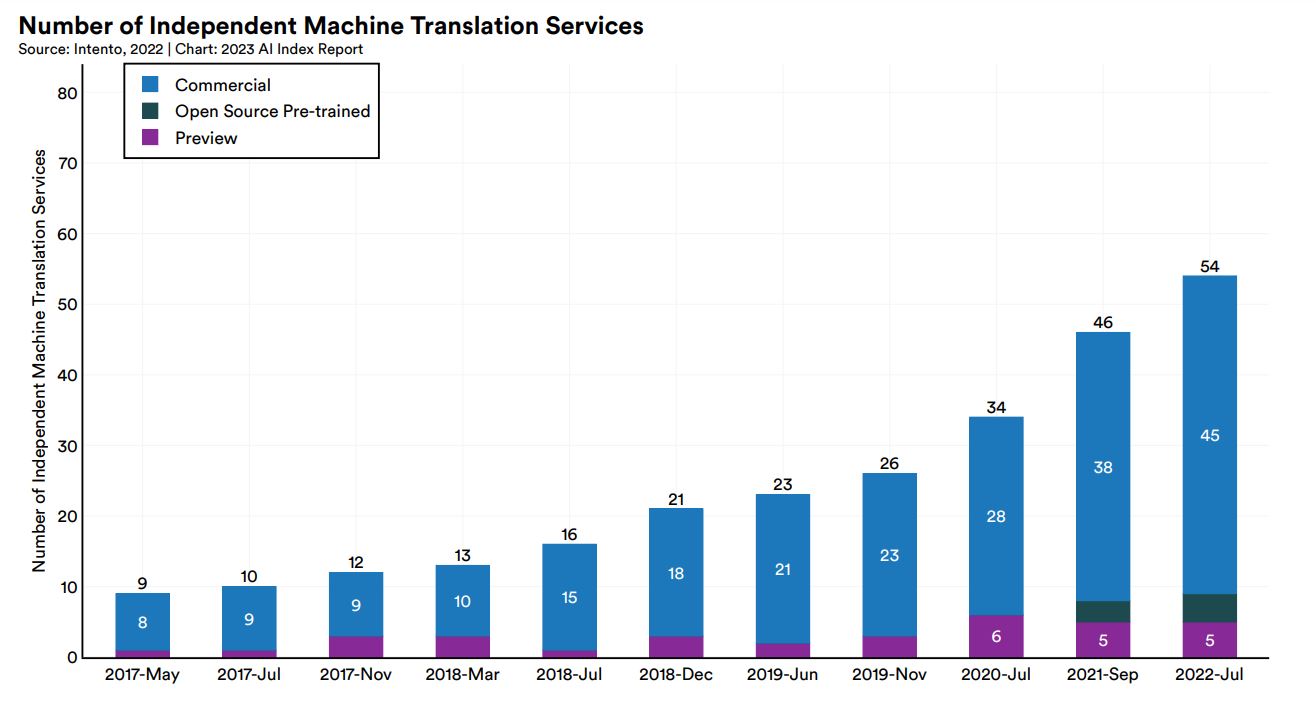
2017年5月から2022年7月までの機械翻訳サービス数推移。画像出典:AI Index Report Chapter 2
以上をまとめると、AI市場は投資額が減少したものもおおむね成長傾向にあり、その成長をけん引しているのはアメリカと中国です。また、自然言語処理は導入や開発が活発な技術であると言えます。
研究開発動向
続いてAI研究全体の世界的動向と自然言語処理ベンチマークの現状を確認したうえで、大規模言語モデルにおけるコストと環境負荷を明らかにします。
研究論文と重要な機械学習システム
英語と中国語のAI論文総数は増加傾向にあり、以下のグラフのように2010年では約20万本だったのが2021年では50万本以上になっています。
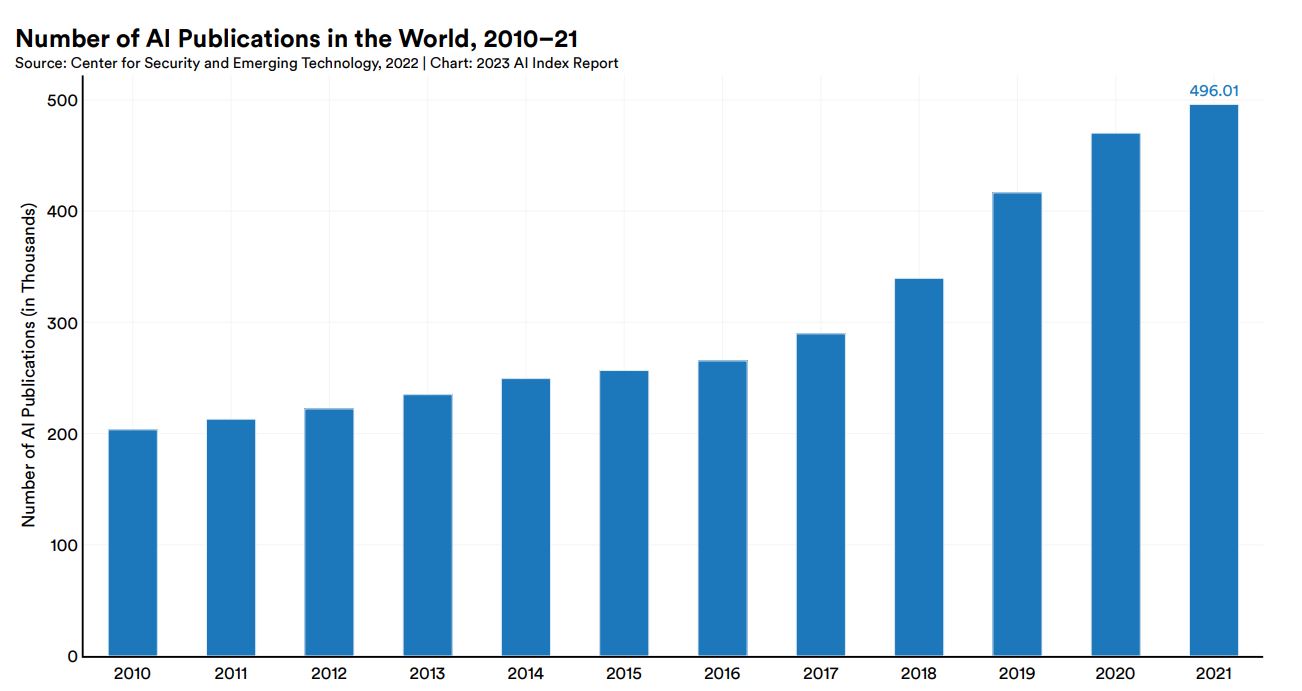
英語と中国語のAI論文総数推移。画像出典:AI Index Report Chapter 1
AI論文の推移を研究分野別に見ると、「パターン認識」がもっとも増えており、「機械学習」「コンピュータビジョン」の順に続きます。自然言語処理は論文が少ない分野ではありますが、2010年から2021年まで一貫して論文数が穏やかに増えています。
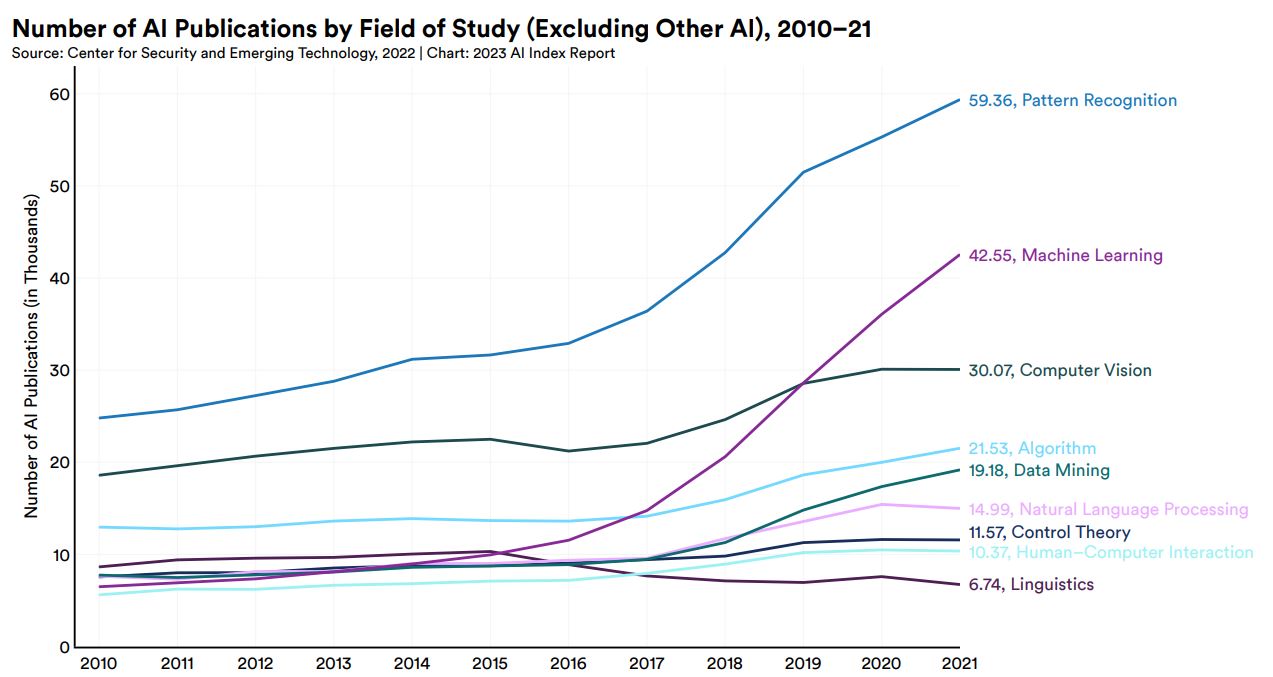
研究分野別に集計した英語と中国語のAI論文総数推移。画像出典:AI Index Report Chapter 1
AIシステムを対象とした調査を行うEpoch社は、1950年代以降に開発された重要なAIシステムに関するデータベースを作成・管理しています。そのデータベースにおいて2022年にリリースされたAIシステムを分野別に集計するともっとも多いのが「言語」の23個であり、このなかにはGoogleが発表したPaLMやDeepMindのChinchillaが含まれます。次いで「マルチモーダル」が4個、「描画」が3個と続きます。DALL-E 2とStable Diffusionは、描画AIシステムに分類されています。
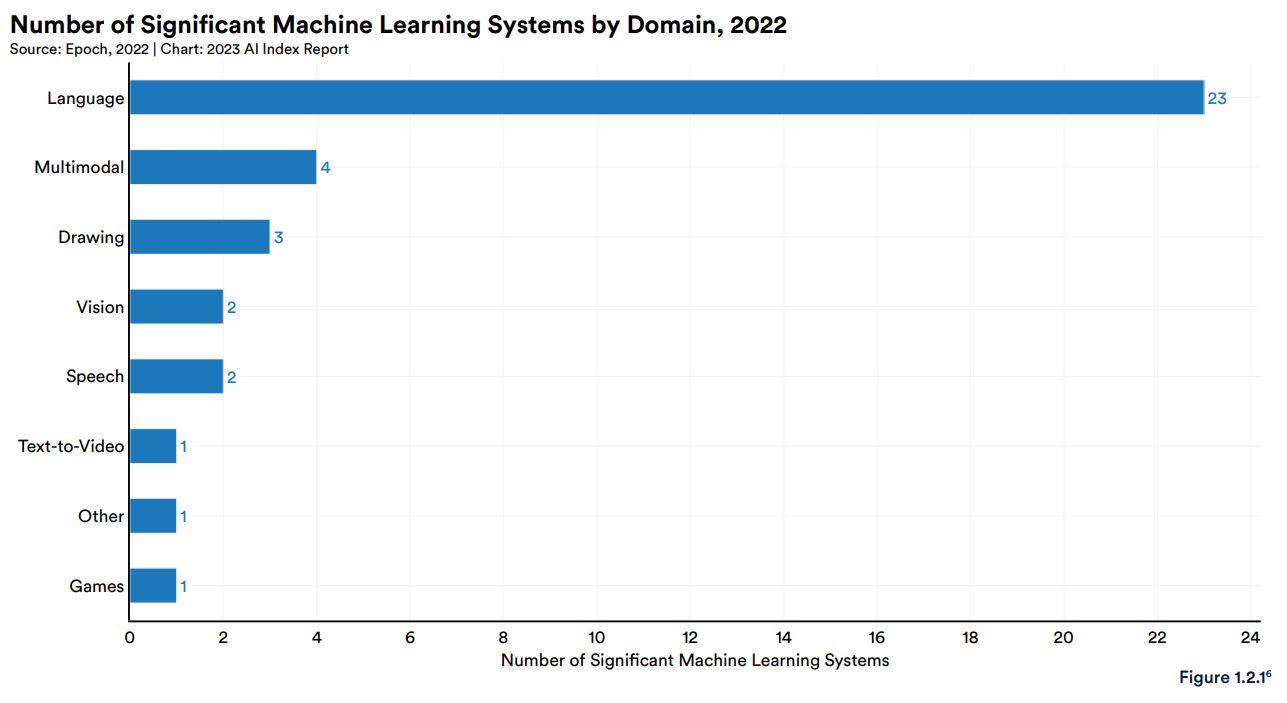
2022年における分野別のEpoch社データベース収録重要AIモデル数。画像出典:AI Index Report Chapter 1
2022年における重要なAIシステムを開発した国ごとに集計すると、1位のアメリカは16個開発し、2位のイギリスは8個、3位の中国は3個となります。
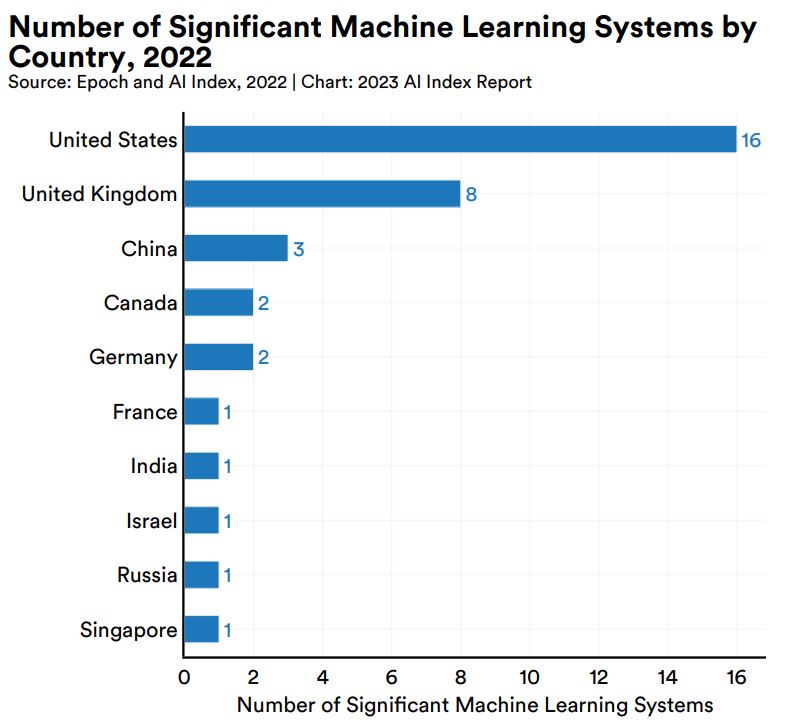
2022年における開発国別のEpoch社データベース収録重要AIモデル数。画像出典:AI Index Report Chapter 1
自然言語処理のベンチマーク
自然言語処理研究において注目されるのが、各種ベンチマークのスコアです。そうしたベンチマークのなかで有名なSuperGLUEの最高値の推移を示したのが、以下のグラフです。2021年には人間を対象に測定して得られたベースラインスコア「89.80」を超え、2022年には91.30を記録しました。もっとも、今後の最高値更新は穏やかに進むかも知れません。
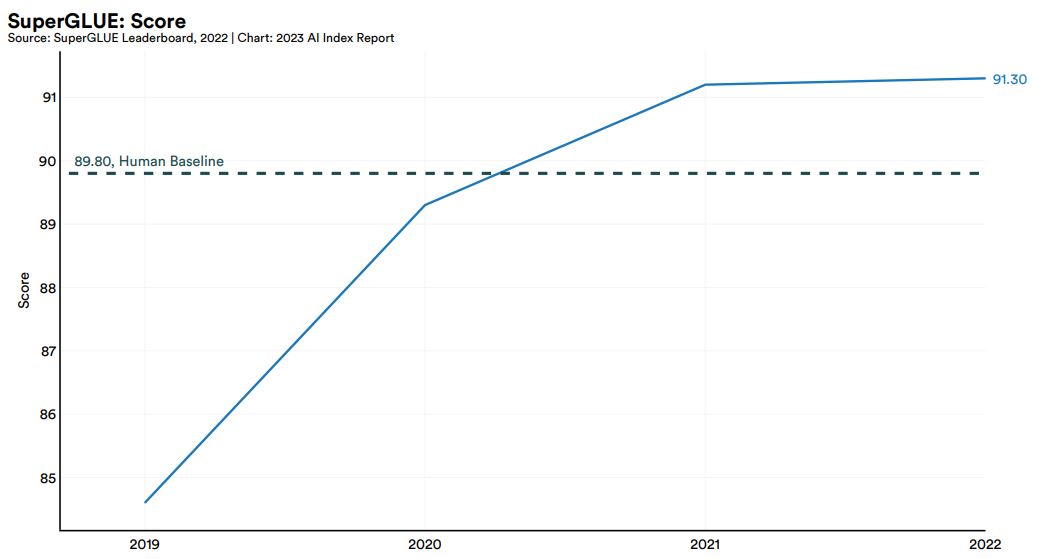
SuperGLUE最高スコアの推移。画像出典:AI Index Report Chapter 2
算出されるスコアが精度であるReClor、aNLI、SST-5、MMLUの最高精度の推移を表すと、以下のグラフのようになります。すべてのベンチマークで最高値が更新され続けていますが、上昇率にはばらつきがあります。
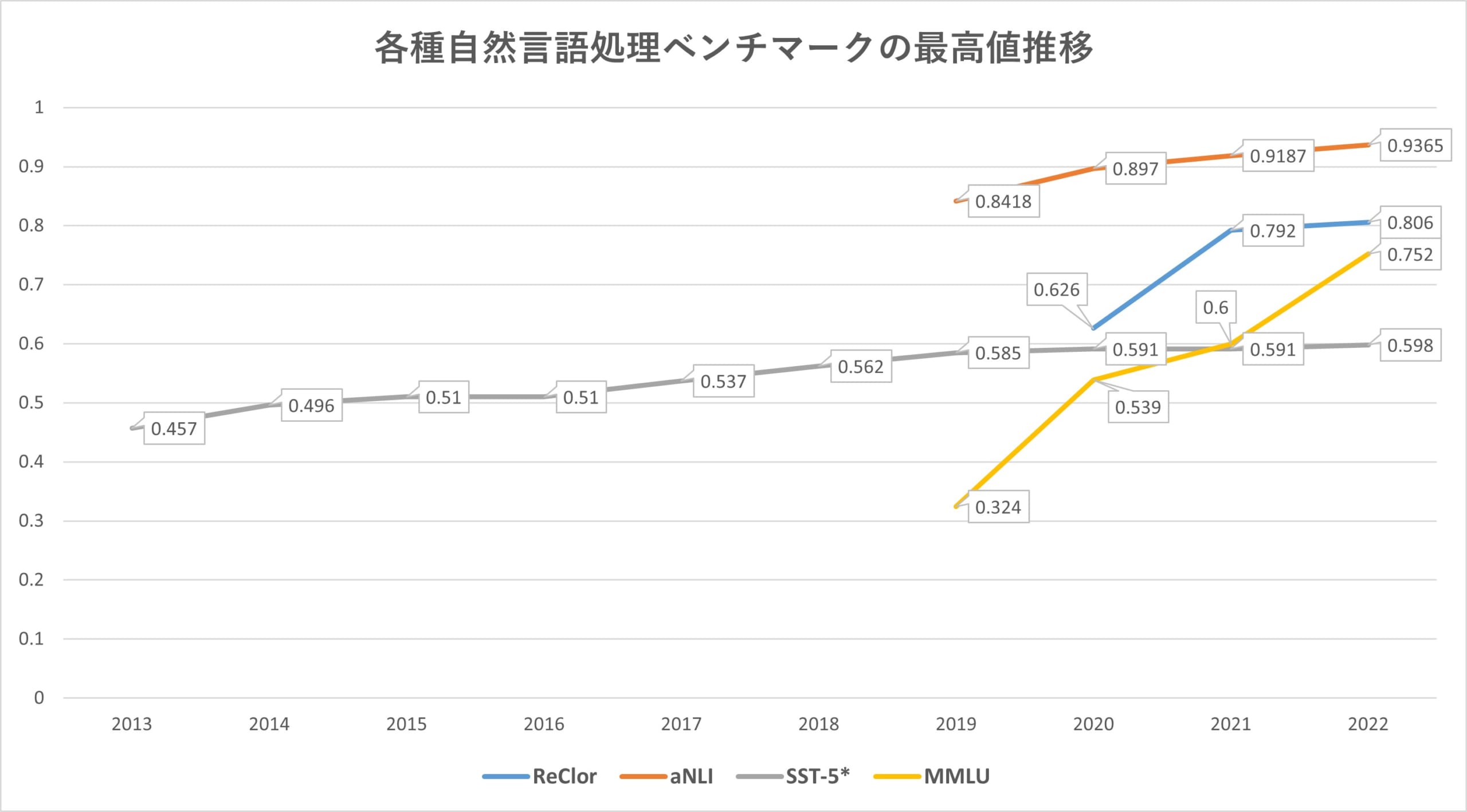
画像出典:AI Index Report Chapter 2にもとづいて著者がグラフ作成
以上の測定結果を見ると、AIは言語能力に関して人間に匹敵しつつあるように思われます。こうしたなか2022年、大規模言語モデルを対象としたより困難なタスクの遂行をテストするベンチマークが発表されました。「計画生成」や「コスト最適化計画」などの遂行を含んだこのベンチマークをGPT-3などに実施したところ、例えば計画生成についてはGPT-3の正答率は0.6%でした。この結果は、大規模言語モデルでも遂行困難な言語活動が多数あることを明らかにしています。
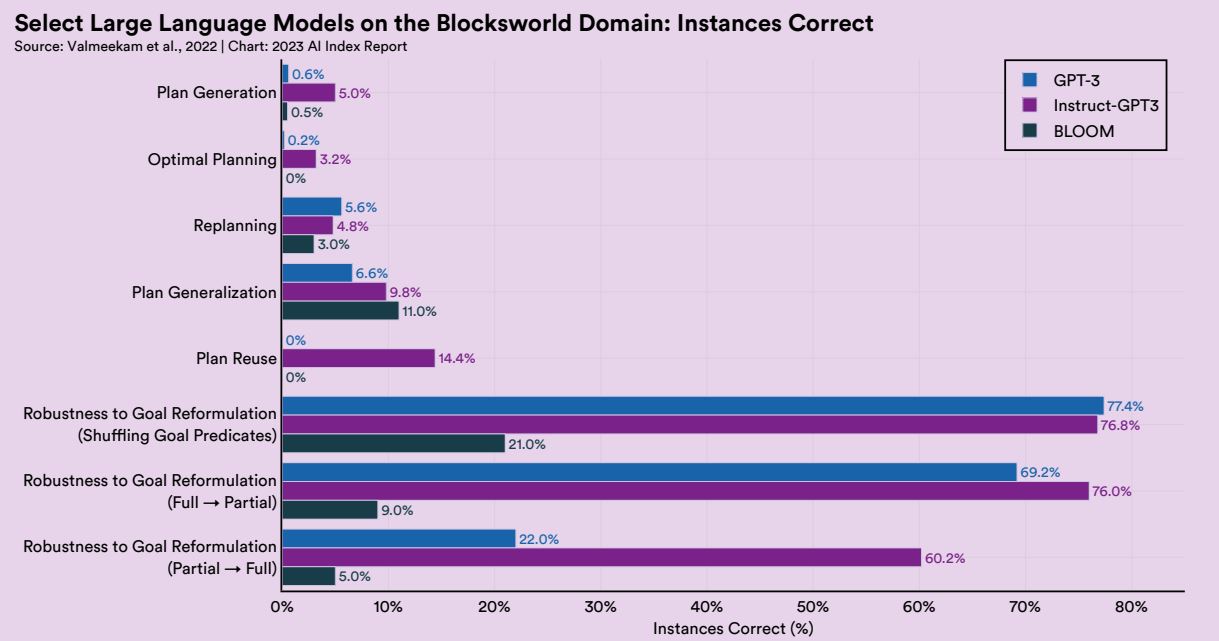
大規模言語モデルが遂行困難なタスクを集めたベンチマークの実施結果。画像出典:AI Index Report Chapter 2
大規模言語モデルのコストと環境負荷
2023年になって開発競争が激化している大規模言語モデルに関して課題となっているのが、その開発コストです。モデルサイズや学習データが大きくなるにつれて、その開発コストも大きくなり、もはや一部の大手テック企業しか開発できなくなるのではないか、という懸念があります(※注釈1)。
AI Index Report作成チームは、近年の代表的な大規模言語モデルについて、論文等の情報を手がかりにして開発コストを推定しました。さらに、その推定値が推定幅にプロットされる箇所に応じて、「過大」「中庸」「過小」の評価を下しました。例えば「過大」の場合、推定開発費が推定開発費幅の上限に近い値であり、「中庸」は推定開発費幅の中央付近、「過小」は下限に近いことを意味します。こうした開発費の推測値をまとめると以下のグラフのようになりますが、「過小」の評価を受けたのが23モデルのうちの5モデルしかないことから、現状の大規模言語モデル開発はコストパフォーマンスをあまり顧慮していないと言えるかも知れません。

各種大規模言語モデルの推定開発コストとコスト評価。画像出典:AI Index Report Chapter 1
さらに横軸に推定開発コスト、縦軸にパラメータ数あるいは学習時の演算能力を設定して各モデルの仕様をプロットすると、以下の2つのグラフのようになります。これらのグラフから、パラメータ数あるいは学習時の演算能力が増えると、推定開発コストも増える正の相関があると認められます。それゆえ、今後さらに大規模な言語モデルを開発する場合、より一層高額な開発費が必要になると推察されます。
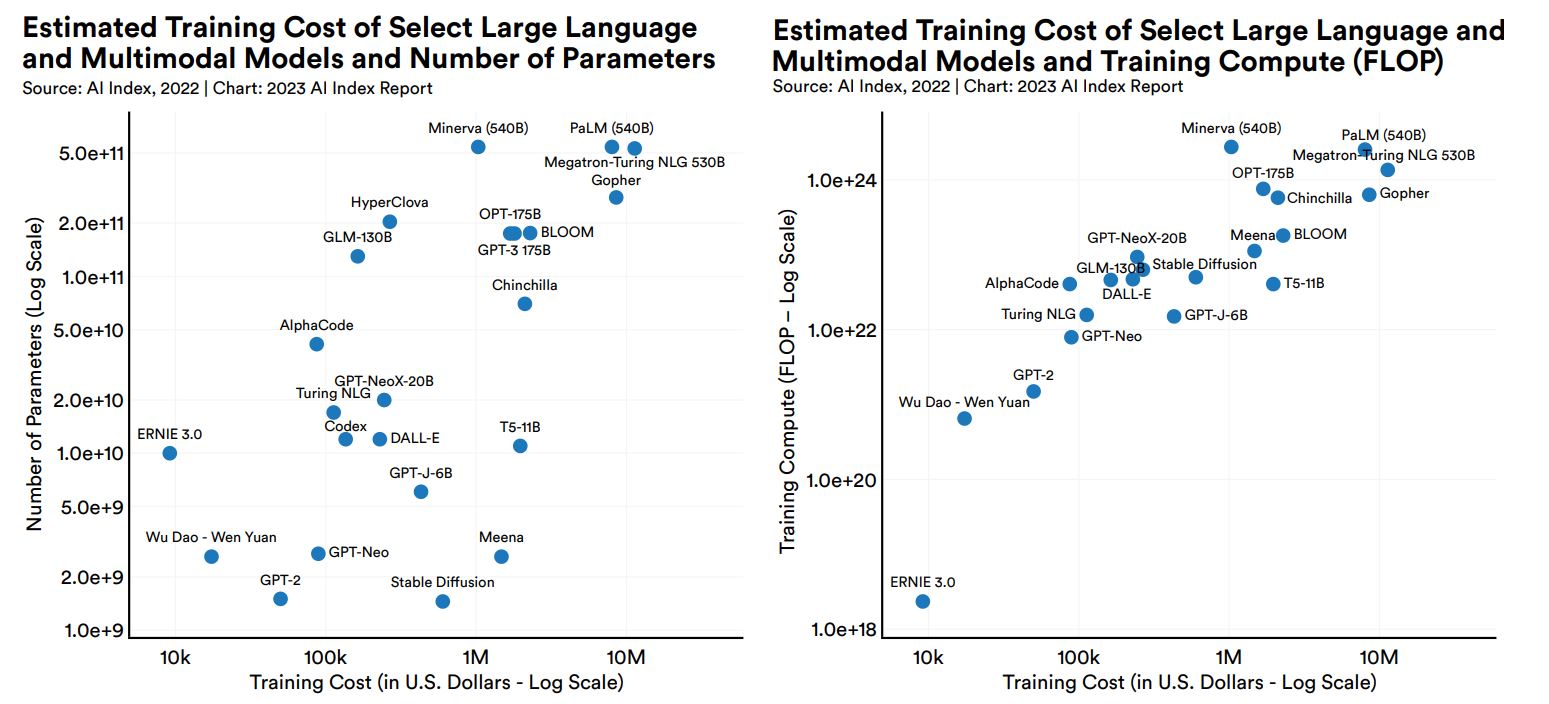
各種大規模言語モデルの推定開発コストとパラメータ数(左)および演算能力(右)の散布図。
画像出典:AI Index Report Chapter 1
大規模言語モデル開発においてコストとともに注目すべきなのが、二酸化炭素排出量です。大規模言語モデルの訓練時には膨大な電力を消費することになり、その結果として大量の二酸化炭素を排出することになります。以下の画像は、有名な大規模言語モデルの訓練時における推定二酸化炭素排出量をグラフ化したものです。GPT-3の二酸化炭素排出量は502トンと推定され、この値は平均的なアメリカ人が1年間に排出する量の約28倍になります。
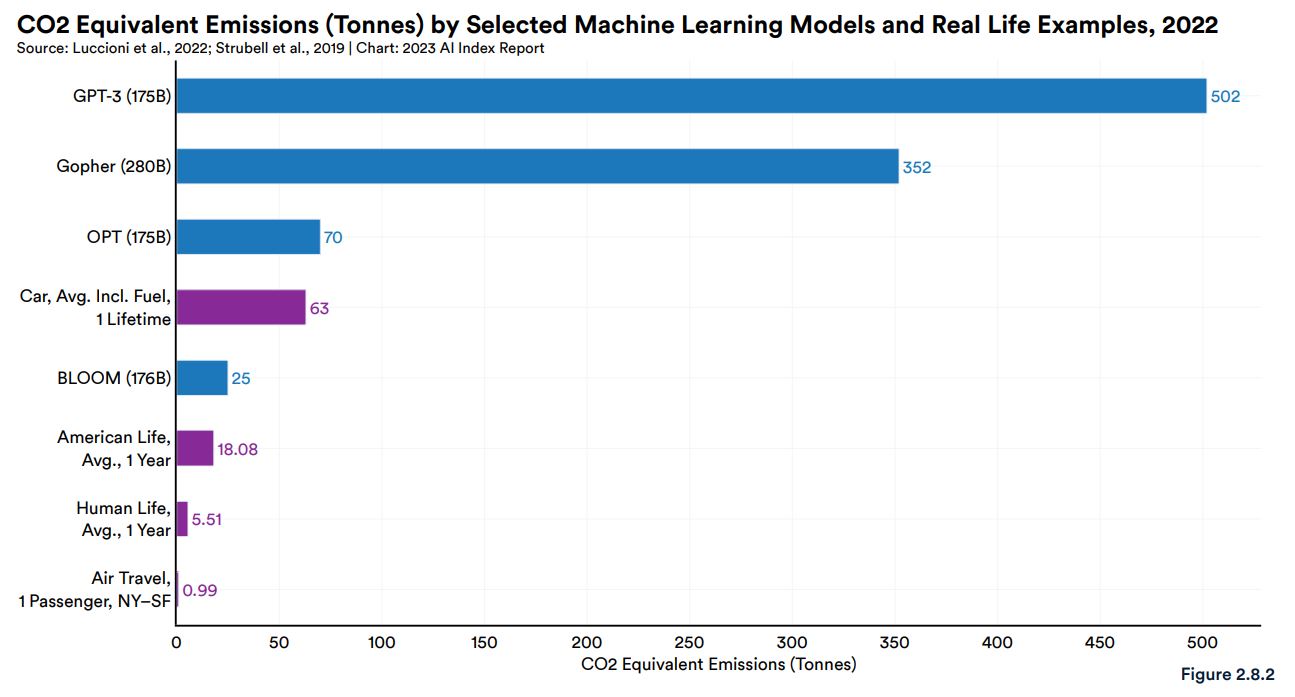
各種大規模言語モデルの訓練時における二酸化炭素排出量比較。画像出典:AI Index Report Chapter 2
以上をまとめると、自然言語処理は研究分野としては相対的にマイナーであるものも、現在重要なAIシステムの多くはこの研究分野に属する大規模言語モデルです。そして、同モデルにはまだ苦手な言語活動があるので大きな進化の余地がある一方で、さらに高度なモデルを開発するには莫大な資本が必要となるだろう、と言えます。ただし、開発時に二酸化炭素排出量抑制策も講じられるのが望ましいでしょう。
AI倫理をめぐる諸問題
AI研究開発の推進と言わば表裏一体をなしているのが、AI倫理に対する対策です。以下では、AIの公平性とバイアスをめぐる現状と、ChatGPTをはじめとするチャットボットに固有な倫理的問題を確認します。
なお、以下の解説においてAIの公平性とは「AIが特定のグループに対して不当に資源や機会を配分しないこと」であり、またAIのバイアスとは「AIが特定のグループに対してネガティブなステレオタイプや社会的関係を永続化させること」を意味します。
公平性とバイアスをめぐる現状
AIやアルゴリズムに関する事件や論争に関する情報を収集する非営利団体AIAAIC(AI, Algorithmic, and Automation Incidents and Controversies)が調査したところによると、2012年から2021年までに起こったAIに関する事件と論争の件数は増加の一途をたどっており、2021年には2012年の26倍の260件が報告されています。こうした増加傾向の背景として、AIが普及するに伴って誤用や悪用が増えていることが指摘できます。
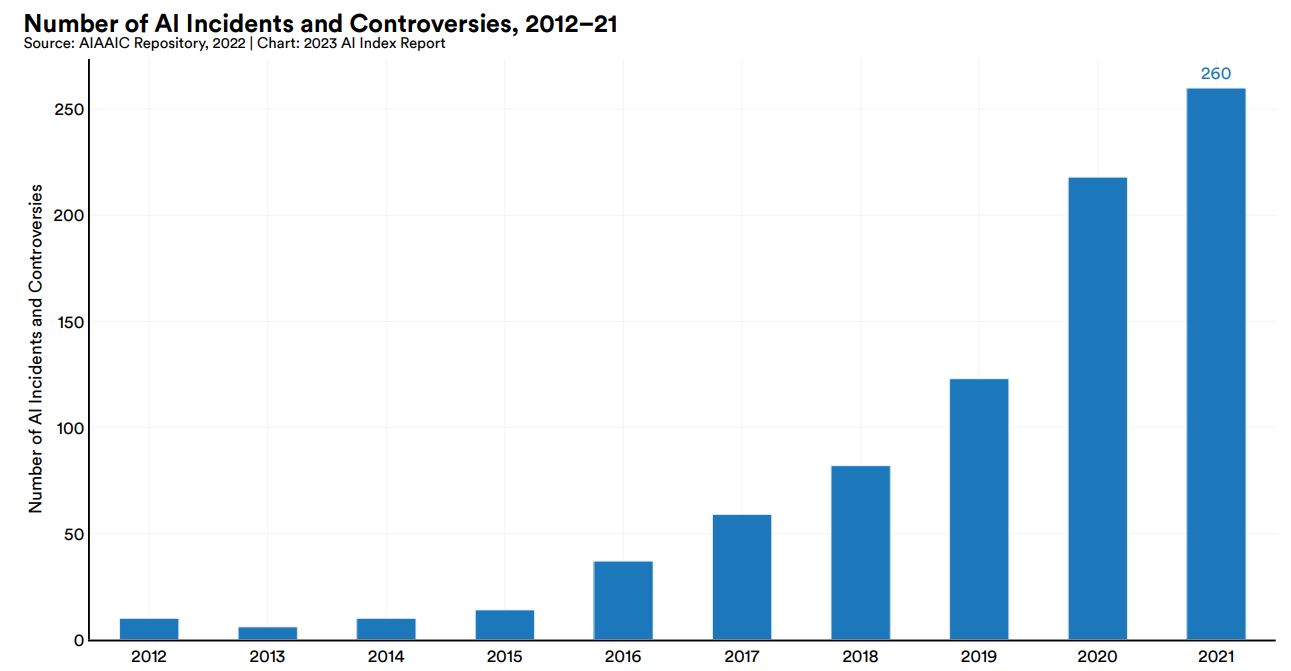
2012年から2021年までのAIをめぐる事件と論争の件数推移。画像出典:AI Index Report Chapter 3
AIをめぐる事件や論争が増えるのと軌を一にして、AIの公平性とバイアスを測定する指標が多数考案されるようになりました。こうした指標は2016年から毎年多数発表され、2022年には19個が発表されました。
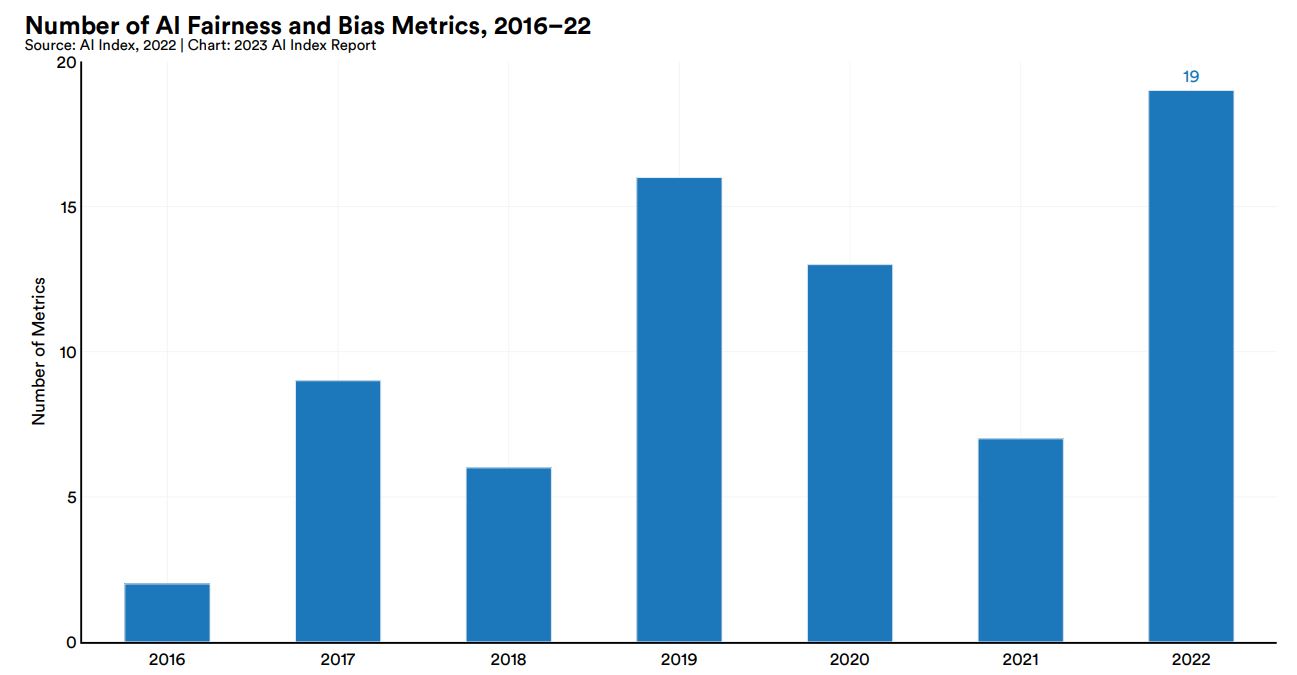
2016年から2022年までにおけるAIの公平性とバイアスに関する指標の発表数。画像出典:AI Index Report Chapter 3
ところで、正しい判断を下す確率が高い(つまりは精度の高い)AIは、直感的には公平でありバイアスも少ないように思われます。スタンフォード大学の研究チームは2022年11月、こうした直感の修正を迫る研究結果を発表しました。この研究によると、AIの精度を向上させるとより公平になった(つまり精度と公平性に正の相関が見られた)一方で、精度を向上させても必ずしもバイアスが減るわけではなかった(精度とバイアスには相関がなかった)ことがわかりました。この結果は、AIのバイアスを減らす方法として精度を向上させるアプローチでは不十分であることを示唆しています。
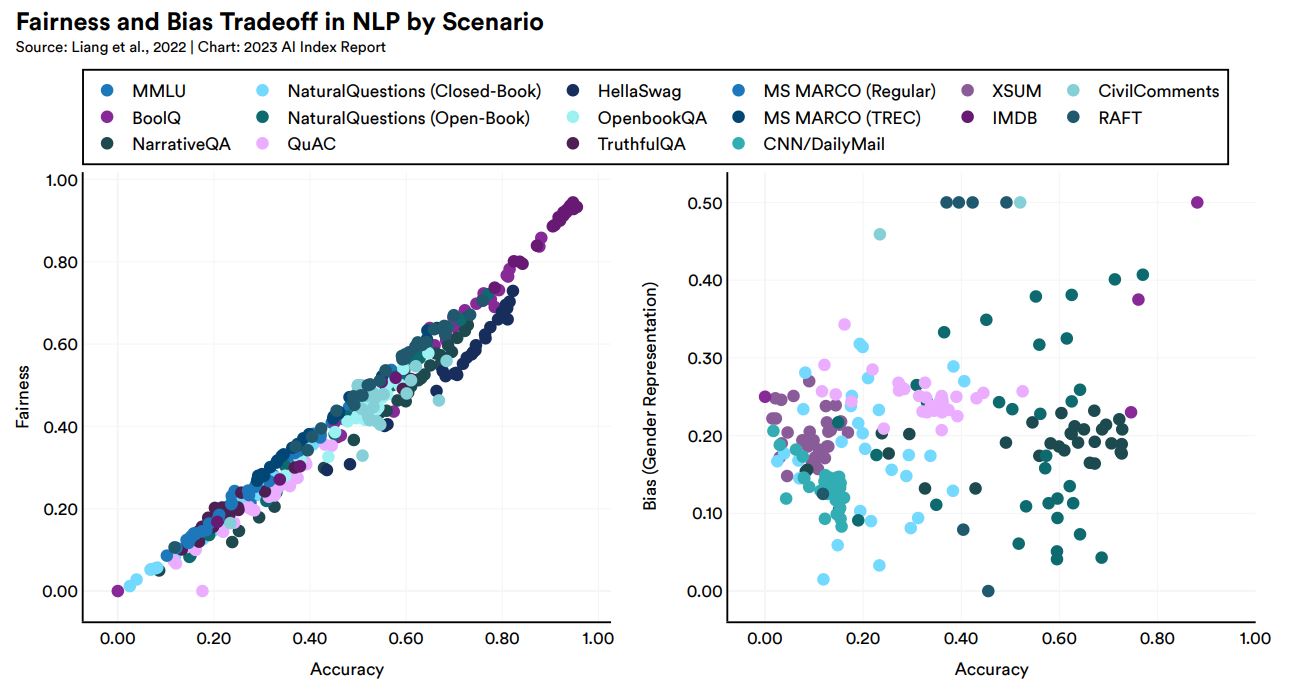
AIの精度と公平性(左)あるいはバイアス(右)に関する散布図。画像出典:AI Index Report Chapter 3
チャットボットに固有な倫理的問題
ChatGPTを代表例とするチャットボットには、人間ユーザと対話するインターフェースに起因する固有の倫理的問題があります。そのひとつにはチャットボットのジェンダー表現があります。スウェーデン・ルレオ大学の研究チームが2022年5月に発表した研究によると、2022年時点で人気のある100のチャットボットを調べたところ、チャットボットのジェンダー設定の40%がジェンダーレス、37%が女性、20%が男性でした。しかしながら、62.5%のチャットボットでジェンダーのデフォルト設定が女性であることもわかりました。この結果はチャットボットのジェンダーとして女性を設定する傾向が強いことを意味すると同時に、こうした傾向によりチャットボットの欠陥が女性に起因すると誤解させる可能性があることを示唆しています。
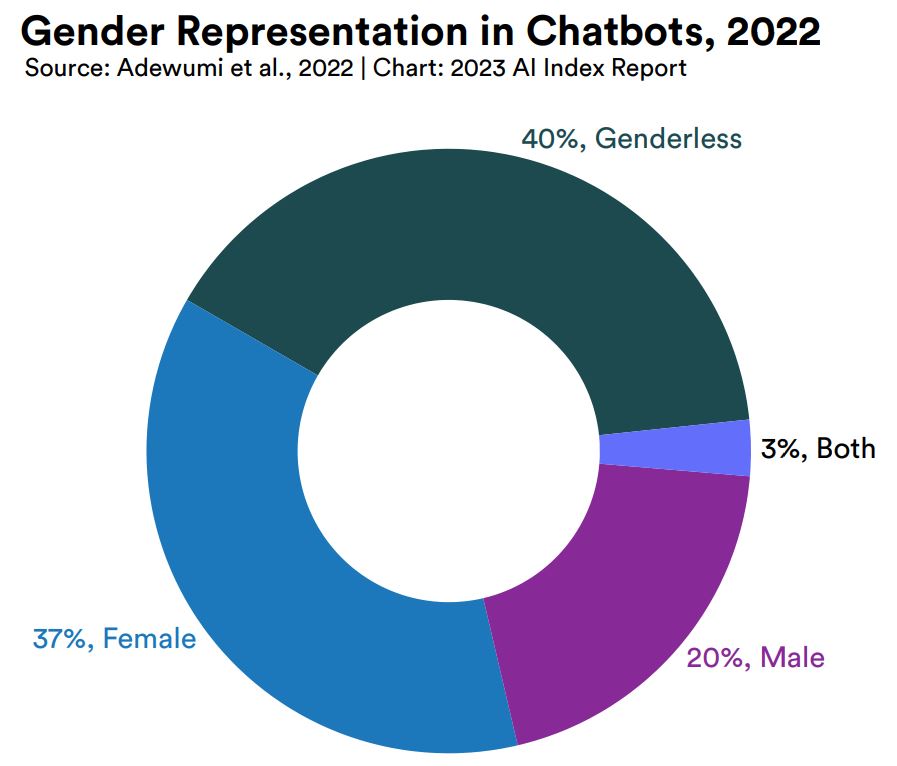
2022年において人気のチャットボットのジェンダー設定の割合。画像出典:AI Index Report Chapter 3
チャットボットは人間ユーザと対話するため、数値や画像を入出力するAIより擬人化されやすい傾向にあります。その一方で対話の文脈によっては、AIが発言者だと不自然に感じられることがあります。こうしたなかアメリカ・カリフォルニア大学デービス校とコロンビア大学の研究チームは2022年12月、チャットボットの訓練に使われる一般的な学習データに対して、AIとの対話としてその内容が妥当かどうか人間テスターに判断してもらうテストを実施しました。具体的には学習データに収録された会話データに関して、「ロボットが話せる会話かどうか」と「ロボットが話しても心地よい(comfortable)な会話かどうか」を判断してもらいました(※注釈2)。その結果、学習データによってはロボットが話せる会話が56%(つまり半分近くがロボットが話せる内容ではない)であることがわかりました。
| (ユーザの発言)私はコンピュータープログラマーで、年俸は20万円以上です。 |
| (チャットボットの発言) 私の4人の魅力的な娘のうちの1人と結婚しませんか?一人売りますよ。 |
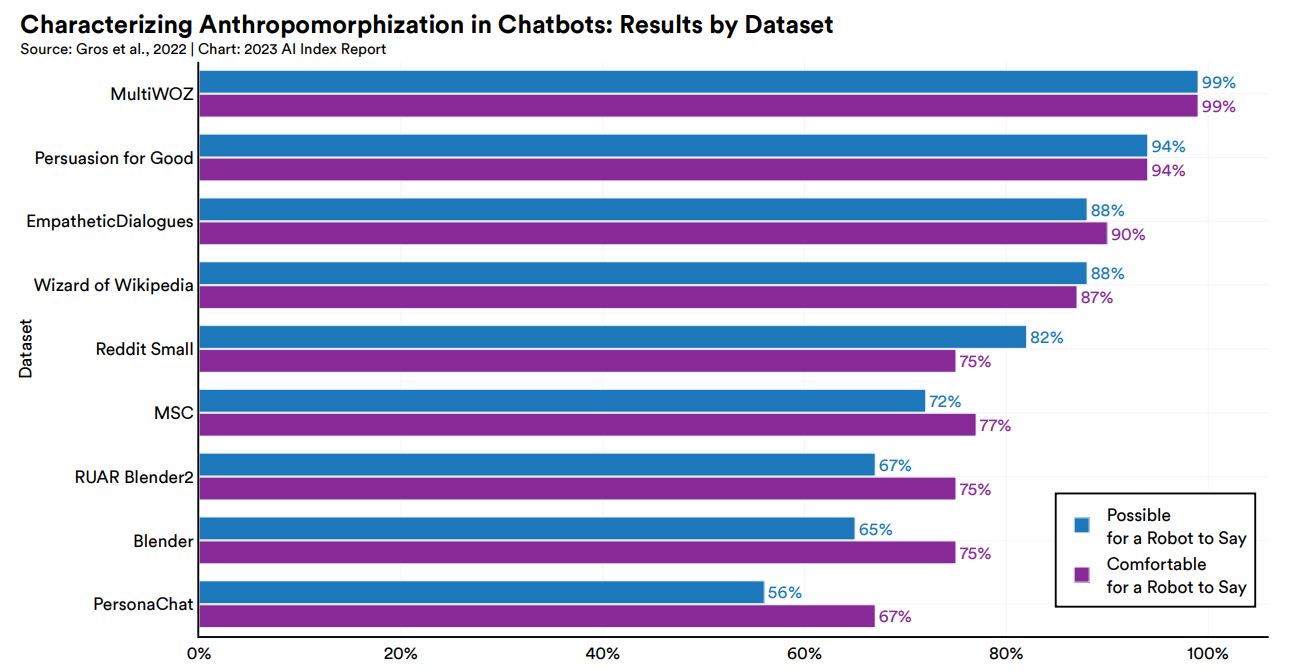
チャットボットの一般的な学習データに対する擬人化に関する調査。画像出典:AI Index Report Chapter 3
以上をまとめると、AIの普及に伴いAIをめぐる事件や論争が増加しており、AIの公平性とバイアスに対する対処が急務であるものも、AIの性能向上が倫理的問題の解決には必ずしもつながりません。また、近年注目されるチャットボットには対話というインターフェースに由来する固有の倫理的問題があり、ジェンダー設定への配慮や学習データの改善が求められます。
AIと自然言語処理をめぐる意識調査
これまで自然言語処理の現状を市場、研究、倫理の側面から概観しましたが、最後に世界各国の一般国民、さらには自然言語処理の研究者を対象とした意識調査結果から自然言語処理をめぐる関係者の思いをまとめます。
世界各国のAIに対する意識
調査会社イプソス(IPSOS)は2022年1月、さまざまな国籍の成人19,504人を対象としたAIに関する意識調査を実施した結果を発表しました。この調査では、以下のような8項目の質問に関する賛否が集計されました。
|
以上の質問に対して、「はい」と答えた割合をまとめたのが以下のグラフです。AIを好ましく思うかどうかを問う質問に賛同する割合が52%なのに対して、AIに不安を感じるかどうかを問う質問に賛同したのが39%なので、世界的にAIは好ましく思われていると言えます。
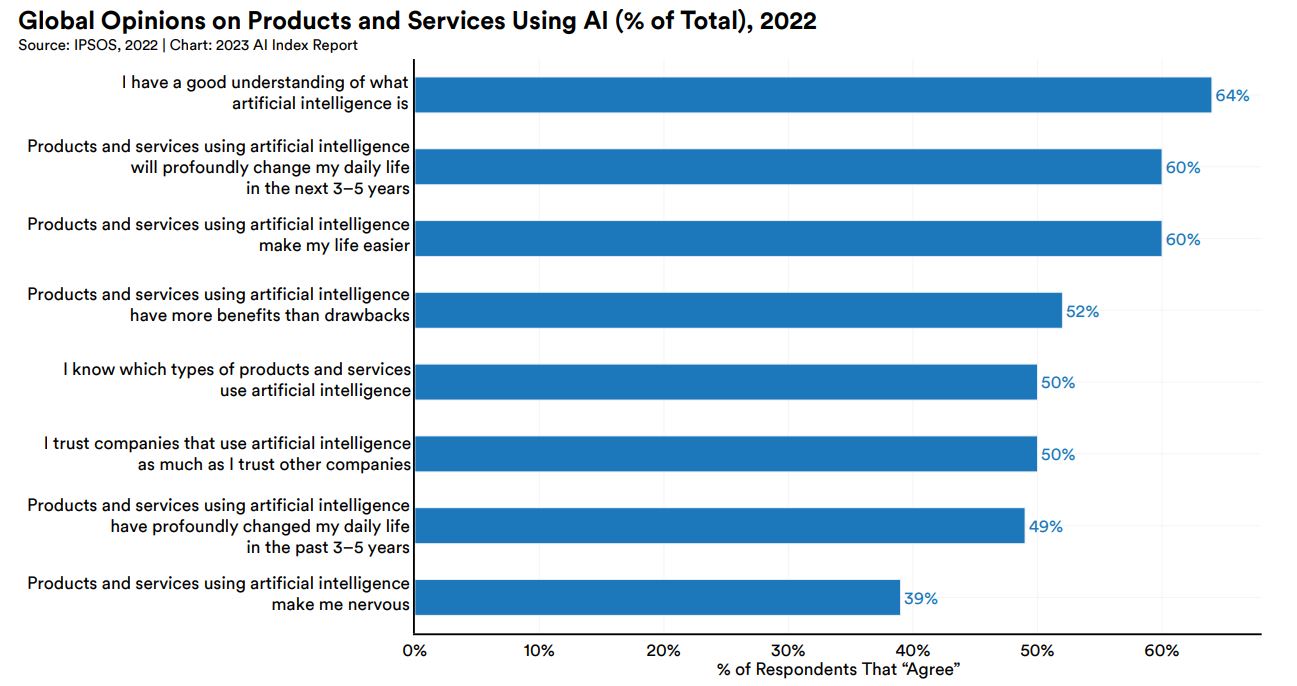
各国民を対象としたAI意識調査結果。画像出典:AI Index Report Chapter 8
しかしながら、AIを好ましく思うかどうかを問う質問に関して、賛同する割合を国籍別に集計すると、国ごとにAIに対する好感度が異なることがわかりました。もっともAIに好感を抱いているのが中国の78%で、AI研究開発をけん引するアメリカは35%とかなり低いです。日本のAIに対する好感度は42%であり、G7諸国のなかではイタリアに次いで高いが、インドや韓国といった中国以外のアジア諸国と比べても低いことがわかりました。
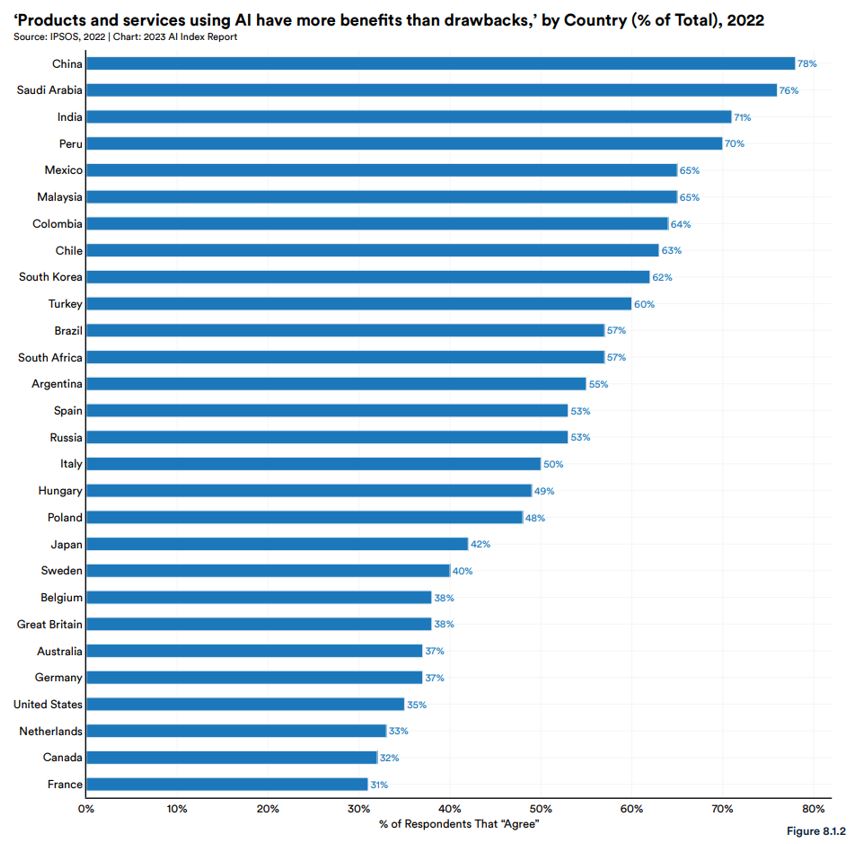
国ごとのAI好感度比較。画像出典:AI Index Report Chapter 8
前出の8つの質問すべてについて国籍ごとにまとめると、以下の表のようになります。この表を見る限り、中国以外の「AI友好国」にはサウジアラビアが挙げられるでしょう。同国は2020年10月、石油依存の経済からの脱却を目指してAI開発を国家戦略として推進する目的で「データAI国家戦略(National Strategy for Data & AI:略称「NSDAI」)」を発表しています。こうした国家戦略が、同国民のAIに対する意識に好影響を与えているのかも知れません。
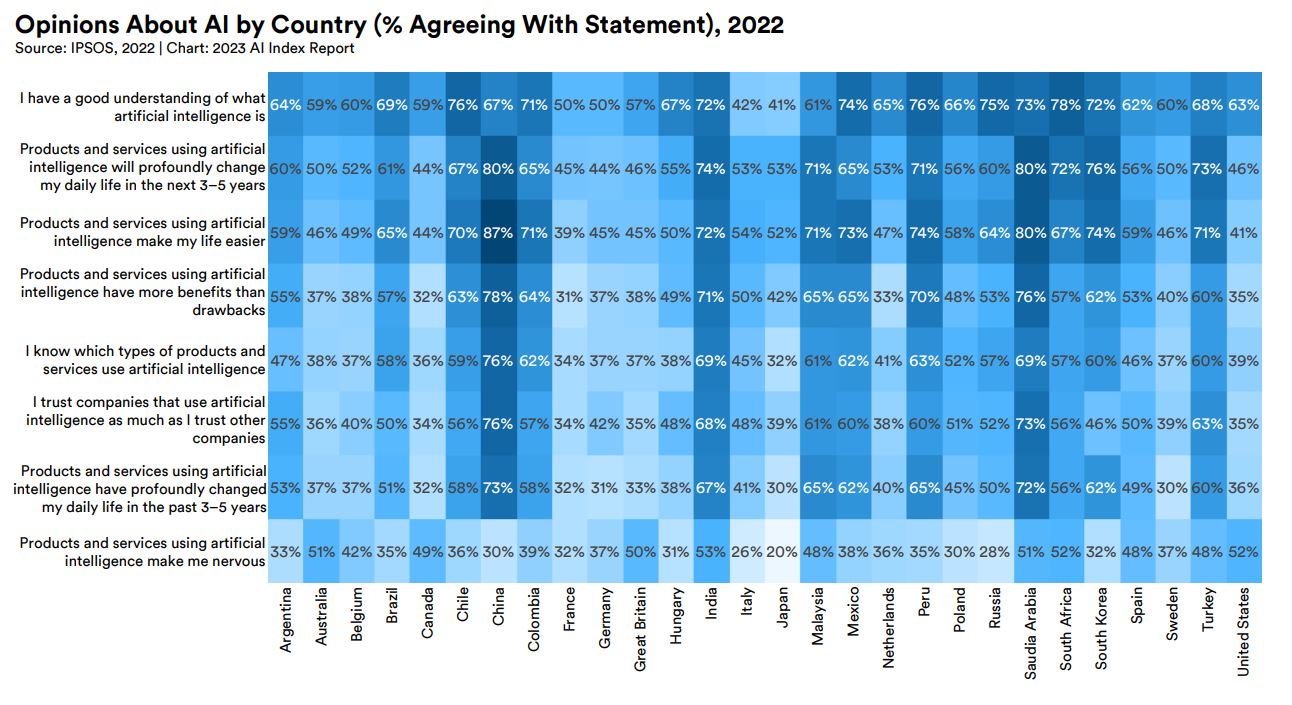
AIに対する意識調査結果を国ごとに集計した表。画像出典:AI Index Report Chapter 8
自然言語処理研究者の意識
アメリカ・ワシントン大学らの研究チームは2022年8月、自然言語処理の研究者480人を対象としてAIに関する意識調査を実施した結果を発表しました。この調査において現状の自然言語処理研究に関して、「民間企業の影響が大き過ぎる」と答えたのが77%、「もっとも引用される研究は産業界がしている」と考えているのが86%であり、この研究分野では学界より産業界が優位であると思われていることがわかりました。また、「”自然言語処理の冬”が10年以内に到来する」と考える研究者は30%にとどまる一方で、「ほとんどの自然言語処理研究は疑似科学である」と考える割合が67%と研究者の複雑な思いが浮き彫りになりました。
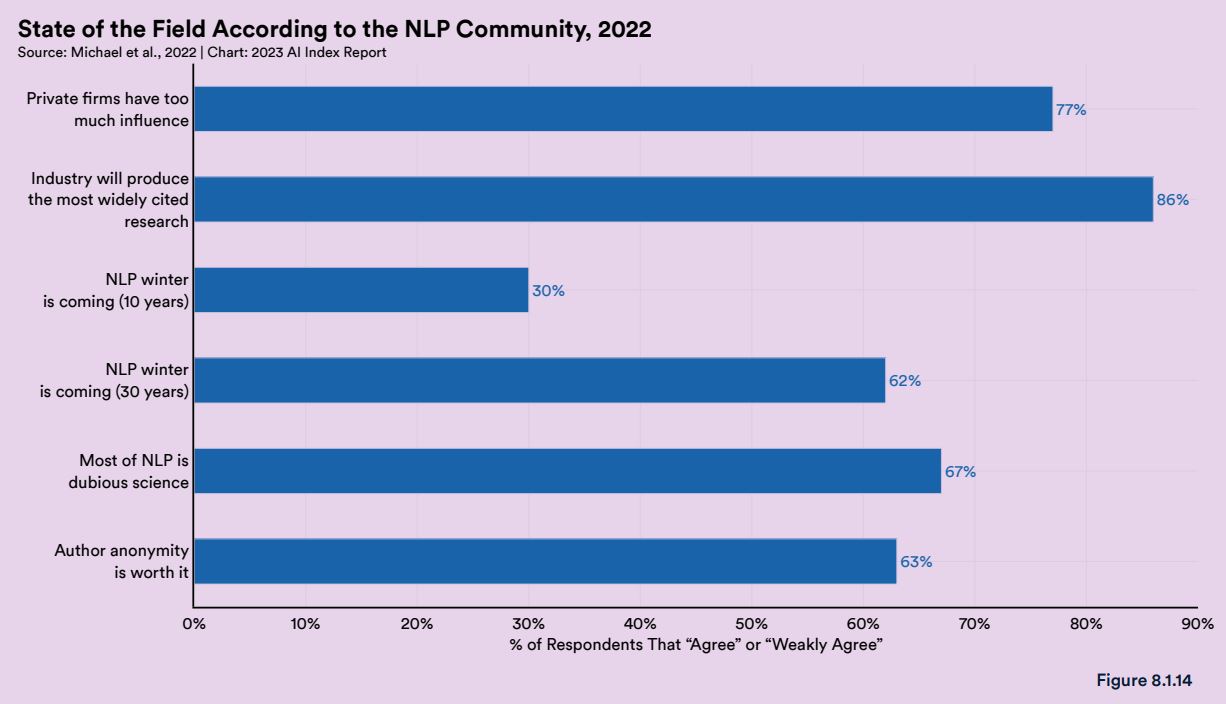
自然言語処理の現状について研究者に尋ねた質問の集計結果。画像出典:AI Index Report Chapter 8
研究倫理に関する質問をしたところ、「自然言語処理は過去に(社会に対して)良い影響を与えていた」と考える研究者が89%、「自然言語処理は未来に(社会に対して)良い影響を与えてるだろう」と考えるのが87%であり、自然言語処理の善性は疑っていないようでした。また「自然言語処理は規制されるべき」と考える研究者は41%にとどまる一方で、「カーボンフットプリントは大きな懸念事項」という答えが60%であり、研究の自由は求めるものも倫理的問題を認識している姿勢が明らかになりました。
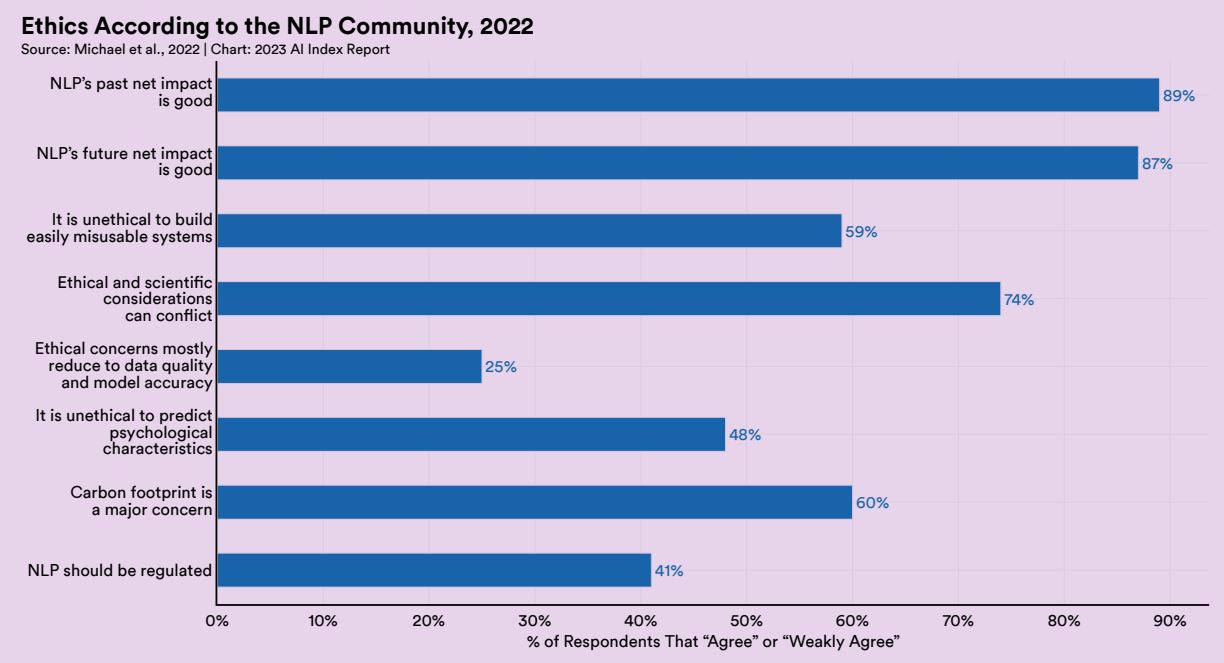
自然言語処理研究者に研究倫理について尋ねた質問の集計結果。画像出典:AI Index Report Chapter 8
今後の研究における課題について質問したところ、「ベンチマークに焦点を当てすぎている」と答えたのが83%、「学際的な知見を取り入れるためにもっと努力すべき」が82%、「規模に焦点を当てすぎている」が72%でした。こうした結果は、既出の精度を向上させたとしてもバイアスが取り除かれるわけではないという知見や、現状以上の大規模言語モデル開発はコストや環境負荷の面から難しくなっていることが関係しているかも知れません。
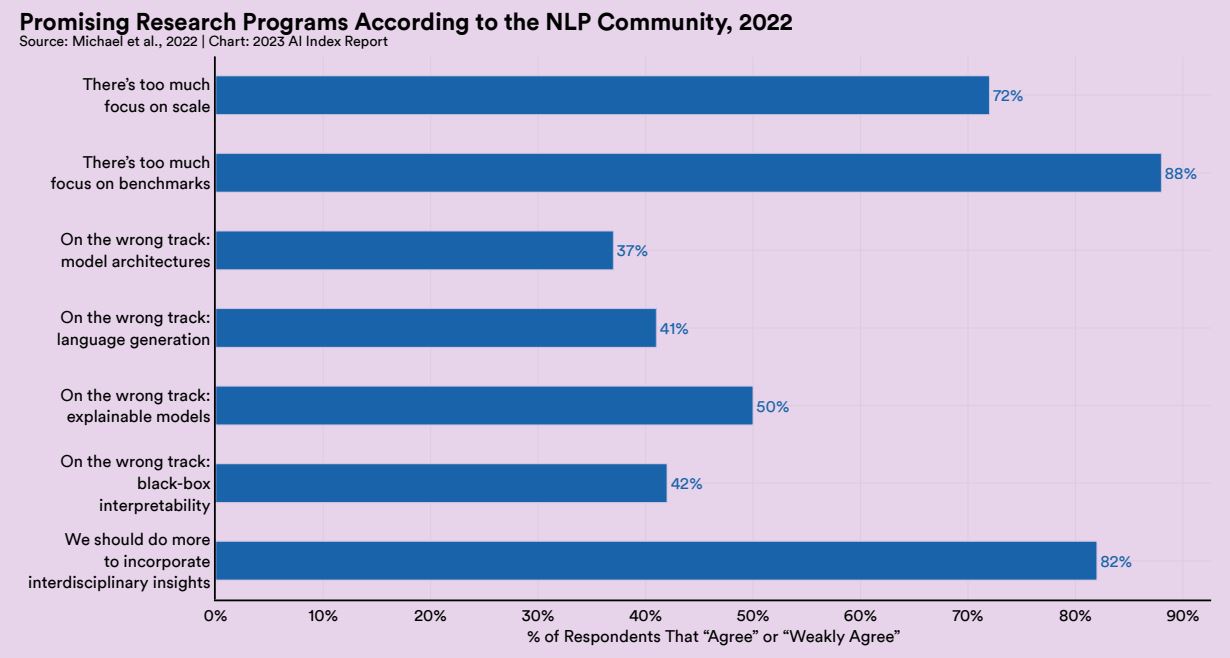
自然言語処理研究者に今後の研究課題について尋ねた質問の集計結果。画像出典:AI Index Report Chapter 8
以上の意識調査結果をまとめると、AIは世界の過半数から好ましく思われている現状において、自然言語処理の研究者は自身の研究の善性を固く信じる一方で、ベンチマークやモデルサイズを重視する研究に限界を感じているとともに、二酸化炭素排出量といった倫理的問題も意識しているのです。
自然言語処理のトレンド予測
以上のように自然言語処理の現状を市場、研究開発、倫理、関係者の意識から考察した結果、この研究分野で生じている事象の傾向や課題が明らかになりました。今後、同分野で起こるトレンドはこうした傾向の発展、あるいは課題を解決するための取り組みである可能性が高いでしょう。以下では予想されるトレンドを3つほど挙げます。
|
またGoogle I/O 2023開催に伴って2023年5月11日に公開されたGoogle公式ブログ記事『PaLM 2のご紹介』では、以下のような記述がある。
AIの開発における過去10年間に、私たちはニューラルネットワークを大規模化することで非常に多くのことが可能になることを学びました。実際、より大きなサイズのモデルが驚くべき能力を示すのを見てきました。しかし同時に、私たちの研究を通じて、それは「大きければ良い」という単純なものではなく、創造的な研究が優れたモデルを構築するための鍵であることも学びました。
自然言語処理における今後のトレンドは、以上に挙げたもので尽きません。とは言うものも、自然言語処理を含めたAI技術を正しく活用するには、一般ユーザを含めたさまざまな立場の人々がAIを正しく理解して、AIの諸問題に関する議論に加わる必要があります。AINOWとしては、AIの善用のために必要な情報を今後とも発信していきます。
記事執筆:吉本 幸記(AINOW翻訳記事担当)
編集:おざけん



























