人工知能(AI)技術は、近年劇的な進歩を遂げています。特に、言語生成AIの分野では、GPTシリーズなどのモデルが幅広い用途で活用され、社会に大きな影響を与えています。しかし、これらのモデルは限界も持ち合わせており、特に生成内容の正確性や特定分野への適応能力に課題があります。これらの課題に対処するために、RAG(Retrieval-based Language Model)やファインチューニング技術が開発され、AIの能力をさらに拡大しています。
人工知能(AI)技術は、近年劇的な進歩を遂げています。特に、言語生成AIの分野では、GPTシリーズなどのモデルが幅広い用途で活用され、社会に大きな影響を与えています。しかし、これらのモデルは限界も持ち合わせており、特に生成内容の正確性や特定分野への適応能力に課題があります。これらの課題に対処するために、RAG(Retrieval-based Language Model)やファインチューニング技術が開発され、AIの能力をさらに拡大しています。
本記事では、生成AIの現状として、特にハルシネーション(誤った情報の生成)や特化分野への適用困難性といった問題点を検討します。さらに、これらの問題を解決するための鍵として、RAGやファインチューニングの技術がどのように重要性を増しているのか、その具体的なメカニズムやユースケースを詳しく解説します。また、今後の課題として、データベースの品質依存性や回答の精度向上の困難さなどを考察し、最終的にはこれらの技術がAIの未来にどのような展望をもたらすのかを探ります。
AIの世界は常に進化し、その可能性は限りなく広がっています。RAGやファインチューニングは、その進化の次の段階を形作る重要な技術であり、本記事を通じて、その全貌を深く理解することを目指します。
目次
生成AIの現状とRAG / ファインチューニングの必要性
ハルシネーションが課題に
AI分野、特に生成AIの進歩は著しいものがありますが、この分野で顕著な課題の一つが「ハルシネーション」と呼ばれる現象です。ハルシネーションはAIが事実に基づかない情報を生成する現象を指し、ビジネス上の決定に誤った情報が影響する可能性があるため、非常に深刻な問題です。
例えば、AIがニュース記事を生成する際に、存在しない出来事や人物についての情報を作り出してしまう場合がこれにあたります。また、歴史的な事実についてAIが誤った解釈を提供することもハルシネーションの一例です。このような情報は、ビジネス決定や学術研究において誤った方向を示唆する可能性があり、非常に深刻な問題となります。
ハルシネーションの原因の一つは、AIモデルが訓練データからの学習に依存している点にあります。訓練データが偏っていたり、不十分だったりすると、AIは不正確または不完全な情報を基に判断を下します。さらに、データの特定のパターンを過剰に一般化することも問題を引き起こす原因の一つです。
ハルシネーション問題の解決には、多様で広範なデータセットの使用、多角的な検証、AI生成情報の正確性評価のための追加的なチェックポイント設置といった取り組みと合わせて、RAGやファインチューニングの適用が重要となります。これらの手法を組み合わせることで、生成AIの精度を高め、ハルシネーションの問題を軽減することが期待されます。
活用が進まない生成AI
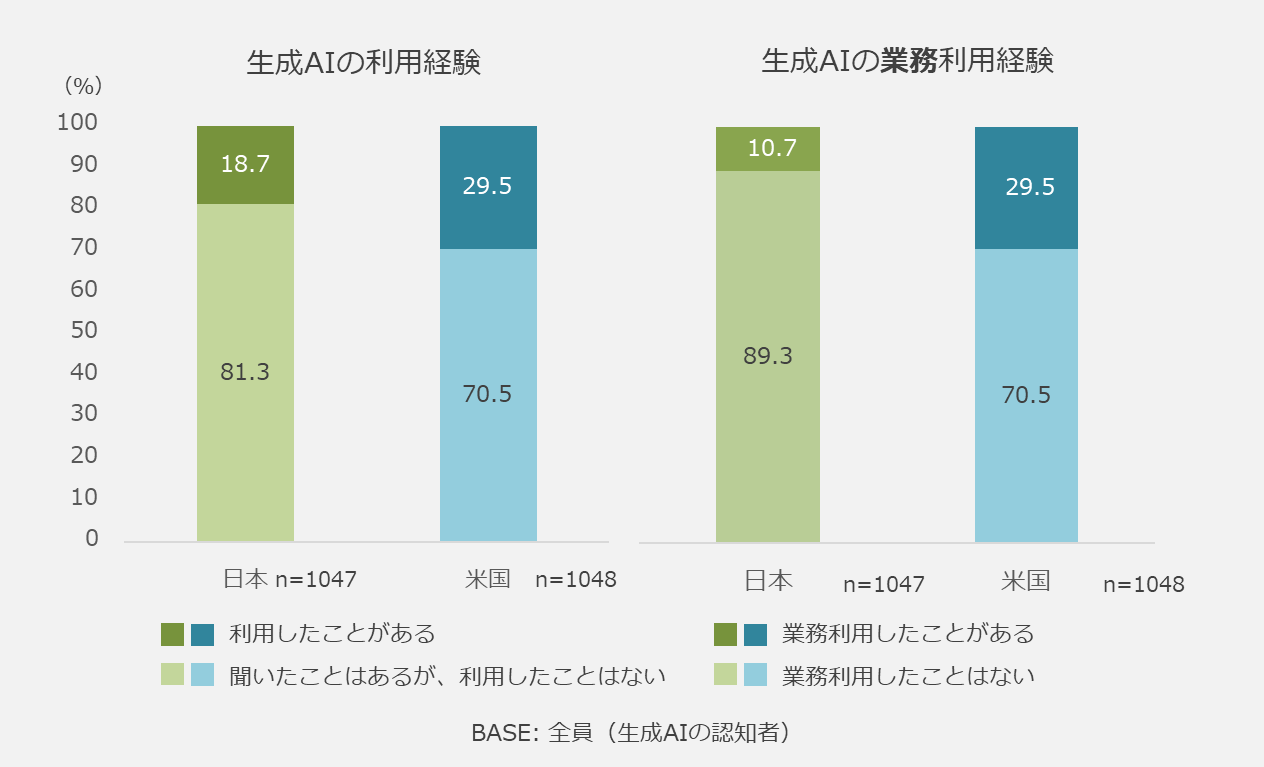
GMOリサーチが2023年10月に公開した調査結果によると、生成AIを認知している人のうち、既に利用経験のある人は、日本18.7%、米国29.5% と、米国の方が生成AIの活用が進んでいます。さらに、業務利用経験がある人については、日本10.7%に対して、米国29.5%と日米間では約3倍の大きな差のある結果となりました。
生成AIが用途に特化した活用で苦戦している理由の一つに、プロンプトの高度化が求められる点が挙げられます。これまでの主流となっているアプローチは、ユーザーがプロンプトに多くの詳細情報を含めることですが、この方法は複数の問題点を含んでいます。
まず、プロンプトに必要な情報を詰め込むことは、ユーザーに高度なスキルや知識を要求します。例えば、医療や法律などの専門分野において、AIに正確な情報を生成させるためには、その分野の深い理解が必要になります。ユーザーがその分野の専門知識を持っていない場合、適切なプロンプトを作成することが難しくなります。
さらに、プロンプトを改善することだけでは、回答の精度に限界があるという問題も存在します。AIはプロンプトに基づいて情報を生成するため、プロンプトの質が生成結果の質を大きく左右します。しかし、たとえプロンプトが適切であっても、AIが持つ知識の範囲や理解の深さには限界があり、必ずしも正確な情報や解答を得られるとは限りません。
これらの課題を克服するためには、AI技術のさらなる進化が必要です。AIがより広範な知識を持ち、複雑な文脈やニュアンスを理解する能力を備えることが重要です。また、ユーザーが容易に操作できるインターフェースの開発や、専門知識を持たないユーザーでも効果的にAIを活用できる支援ツールの提供も、生成AIの活用を促進する上で鍵となるでしょう。
RAG / ファインチューニングの重要性の高まり
上記のように生成AIの活用を妨げているのは「特化した活用の難しさ」から生じています。この問題に対処するため、RAGやファインチューニングなどドメインに特化した活用の重要性が高まっています。
生成AIをビジネス活用できている企業の少なさが課題となる中、生成AIの注目度と活用度の乖離を解決するために、RAGやファインチューニングについて詳しく解説していきましょう。
RAGとファインチューニングの基本概念
RAGとは
RAGは、生成AIに外部の情報源を組み込むことによって回答の質を向上させる技術です。この手法では、AIが特定のクエリや質問に基づいて、インターネットや企業内データベースなどの外部情報源から関連する情報を取得し、その情報を基に回答を生成します。これにより、AIは外部情報源にある固有の知識にアクセスし、特定のトピックや質問に対してより関連性の高く、正確な回答を得ることが可能となります。
なお、RAGは主に2つの使われ方をすることがありますが、ここでは狭義の「モデル名称」としてのRAG(Retrieval Augmented Generation)ではなく、広義の「取得ベースの言語モデル」であるRAG(Retrieval-based Language Model)について扱います。
ファインチューニングとは
ファインチューニングは、AIモデルが特定のタスクやデータセットに特化するように調整するプロセスです。このプロセスでは、既存のAIモデルに特定のデータや知識を「追加学習」させます。この方法により、モデルは特定の業界、言語、話題、または企業固有の情報により適切に回答できるようになります。ファインチューニングにより、企業はAIを自社の特定のニーズに合わせてカスタマイズすることができ、より精度の高い結果を得ることが可能になります。
RAGとファインチューニングの違い
RAGとファインチューニングの違いについて「情報源」「応用範囲」「実装の複雑さ」の観点から以下の表にまとめます。
| 特徴 | RAG | ファインチューニング |
|---|---|---|
| 情報源 | 外部のデータベースや情報源からリアルタイムでデータを取得 | 特定のデータセットに基づいてモデルを調整 |
| 応用範囲 | 特定の質問に対して関連性の高い回答を提供 | モデル全体が特定の文脈やデータセットに対応 |
| 実装の複雑さ | 情報を検索するシステムを組み込むが、LLM自体の変更はなし | モデル自体に直接追加学習を施す必要あり |
これらの違いを理解したうえで、RAGとファインチューニングを適切に使い分けることが重要となります。
簡単にまとめると、RAGは最新かつ広範な情報へのアクセスが重要なシナリオに適しており、ファインチューニングは特定のタスクやドメインに深く特化したシナリオに適しています。
ファインチューニングやRAGの実装方法
RAGの実装方法
RAGの構成要素
- Query Encoder: 質問やプロンプトをベクトル形式にエンコード。
- Document Retriever: エンコードされたクエリを用いて、外部データベースから関連するドキュメントを取得。
- Answer Generator: 取得されたドキュメントとクエリを基に、最終的な回答を生成 。
RAGの実装ステップ
- データベースの選定: RAGが参照する外部のベクトルデータベースを慎重に選定。
- Query Encoderの設定: 質問やプロンプトをベクトル形式にエンコードするQuery Encoderを設定。通常、LLMがこの役割を果たす。
- Document Retrieverの構築: 関連する情報を取得するDocument Retrieverを構築。高度な検索アルゴリズムやベクトル空間モデルが用いられる。
- Answer Generatorの設計: 取得した情報を基に回答を生成するAnswer Generatorを設計。大規模言語モデルが一般的に使用される。
- テストと調整: 実装後、システムの性能をテストし、必要な調整を行う。
- 継続的な更新: 新しいデータや改善されたアルゴリズムによってシステムを常に更新する 。
これらのステップにより、RAGは質問応答や自然言語処理タスクで高度な性能を実現します。
ファインチューニングの実装方法
ファインチューニングの構成要素
- 事前学習済みモデル: LLMなどの既存の大規模な事前学習済みモデル。
- 追加学習データ: 特定のタスクや目的に関連する新たなデータセット。
- 学習アルゴリズム: モデルのパラメータを新たなデータセットに合わせて調整するアルゴリズム。
ファインチューニングの実装方法とステップ
- 事前学習済みモデルの選定: 特定のタスクに適した事前学習済みモデルを選定。
- 追加学習データセットの準備: タスクに関連する新たなデータセットを準備。
- 学習アルゴリズムの設定: モデルの微調整に使用する学習アルゴリズムを設定。
- モデルの微調整: 新たなデータセットを用いてモデルをトレーニング。
- パフォーマンスの評価と調整: 微調整されたモデルのパフォーマンスを評価し、必要に応じてさらに調整。
- 継続的な改善: 新しいデータや洞察に基づいてモデルを継続的に改善。
これらのステップにより、ファインチューニングは特定のタスクやデータセットに対するモデルのパフォーマンスを最適化します。
RAG / ファインチューニングのユースケース
ユースケース1:社内FAQへの利用
RAGやファインチューニングを活用する方法の1つとして、社内FAQシステムがあげられます。従業員がよく尋ねる質問に対して、これらの技術を用いることで、より正確でタイムリーな回答を提供できます。
例えば、RAGを使用すると、企業の最新のポリシーやプロジェクト情報に基づく回答を生成することが可能になります。
また、ファインチューニングを活用すると、特定の業界用語や企業固有のシナリオに特化したAIが、従業員からの質問に対してより精度の高い回答を生成することができます。
従業員は、FAQシステムから迅速かつ正確な回答を得られることにより、社内業務の効率化や成果物の品質向上が期待されます。
ユースケース2:教育・学習支援への利用
企業内での教育やトレーニングプログラムにおいても、RAGとファインチューニングは有用です。RAGを用いて、最新の業界トレンドや技術に関する質問に対して、最新の情報を基にした回答を提供することができます。一方で、ファインチューニングは、特定の業界や企業文化に合わせたトレーニング資料を生成するのに役立ちます。
トレーニングプログラムの内容が常に最新の状態に保たれ、企業にカスタマイズされたトレーニングを提供できることにより、教育の効果が大きく向上することが期待されます。
ユースケース3:研究支援への利用
研究開発部門においても、RAGとファインチューニングは重要な役割を果たします。RAGは最新の研究論文や特許情報など、外部のデータベースから関連する情報を取得し、それに基づいて研究関連の問いに答えることができます。ファインチューニングを用いると、特定の研究分野やプロジェクトに特化したAIアシスタントを開発することが可能です。
これにより、研究プロセスが効率化され、より迅速かつ品質の高い研究成果が生み出されることが期待されます。
今後の課題
データベースのデータの質に依存する
RAGの有効性は、大きくデータベースの質に依存します。適切な情報を抽出するためには、データベースに含まれるデータが正確で、最新であることが必要です。これは、特に急速に変化する業界やテクノロジー分野において、データベースを定期的に更新し、維持することが重要な課題となります。また、ベクトルデータベースの使用は検索精度を高めることができますが、これには高度な技術とリソースが必要です。
回答精度を高めることが難しい
RAGやファインチューニングを用いても、回答の精度を完全に保証することは難しいです。これは、生成AIがまだ完璧ではなく、誤った情報を提供する可能性があるためです。特に、ファインチューニングでは、追加学習に使用するデータの質が非常に重要となります。質の低いデータや偏ったデータを使用すると、AIが誤った情報を学習し、それを基に回答を生成する可能性があります。
RAG / ファインチューニングの今後の展望
データベースの質向上の取り組み
RAGの精度はデータベースのの質の高さに依存しており、その質を高めるための取り組みが重要です。これには、データの定期的な更新と検証、高品質なソースからの情報の取り込み、データの整合性と正確性の確保が含まれます。加えて、将来的には、足りない情報を特定し、その補完を提案するAIの能力の向上も期待されています。これにより、データベースの内容がより包括的かつ正確になることが期待されます。
Assistant APIなどアシスタントAIとの接続による自律性の獲得
2023年11月6日に開催されたOpenAIの開発者向け会議「OpenAI Dev Day」の発表の中で、新しいAPI「Assistants API」が発表されました。
今後、Assistants APIのようなアプリ開発をAIアシストしてくれる仕組みとRAGやファインチューニングを統合することで、AIの自律性と機能性が大幅に向上すると期待されています。これにより、AIはユーザーからの複雑なクエリに対しても、より効率的かつ効果的に応答することが可能になります。
マルチモーダル対応
現在のAI技術において、特に最新の大規模言語モデルはマルチモーダル対応を実現しています。これらのモデルはテキストと画像の入力を組み合わせて理解し、応答を生成する能力を持っています。
しかし、RAG(Retrieval Augmented Generation)やファインチューニングの分野では、マルチモーダル対応はまだ一般的ではありません。RAGは主にテキスト情報の検索に焦点を当てており、画像や音声などの非テキストデータを直接扱うことは限定的です。RAGのアーキテクチャは、データベース、検索メカニズム、プロンプト、生成モデルなどの複数のコンポーネントを含むため、システムの開発と展開には複雑さが伴います。
将来的には、RAGやファインチューニングを用いた生成AIがテキストだけでなく、画像や音声などのマルチモーダルなデータを取り扱う能力も持つようになることが期待されています。これにより、AIはより高品質なコンテンツを生成し、さまざまな業務やアプリケーションでの利用が拡大するでしょう。
執筆:林 啓吾
編集:おざけん
生成AIの概要から事例、導入方法まで体系的に解説
AINOW編集長 おざけんによる書籍「生成AI導入の教科書」では、体系的に生成AIの導入方法について解説しています。ぜひご覧ください。