
最終更新日:

本日はコミュニケーションを数値で”見える化”するサービス「UpSighter(アップ・サイター)」について、コグニティ株式会社 (英語表記:COGNITEE Inc.)の代表取締役・河野さんにお話を伺いました。
”見える化”の仕組み、具体的に何が出来るのか…詳しく教えて頂きました!
目次
コミュニケーションを”数値で”表す

中川

河野さん
たとえば、営業トークですね。エース社員とそうではない社員のトークをそれぞれ数字で表して、比較できるようにします。
どの項目がエースと異なるのかが値で分かるので、課題を明確にすることができるのです。

↓スピーチ展開の傾向も、このようなグラフで見ることができます。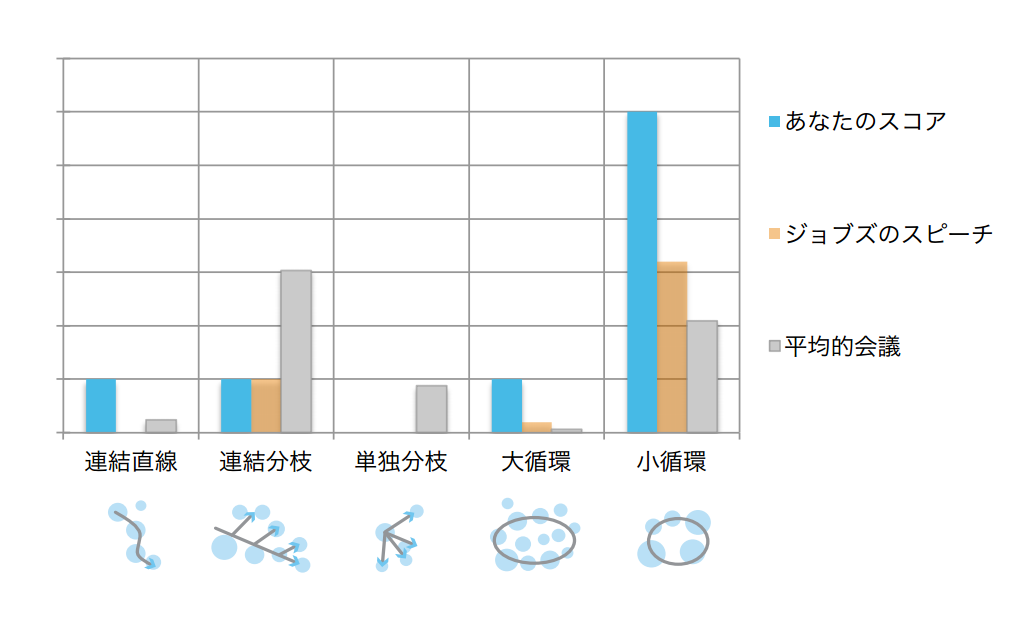
ジョブズのスピーチは「別の話題への広がり」がほとんどなく、「事実情報」や「深堀した説明の値」も低い点が特徴的で、”思い”が入った「根拠としての理由」にスポットを当ててプレゼン展開していることが分かります。
河野さん曰く、『TEDトークとジョブズのトークは似ている』のだそう。思い入れが強いことを訴えることで、洗脳のような効果があるようです。
このパターンのプレゼンは、理系お医者さんやエンジニアなど、理系タイプの聞き手には通じないところが欠点なのだとか。
ということは、私たちも取り上げる話題を減らして思い入れを主張するパートを多く盛り込んだ構成に挑めば、ジョブズのようなプレゼンができる…かもしれませんね。
現在、携帯ショップの店員さんや塾講師など様々なシーンのコミュニケーションでアップ・サイターが活かされているのだそうです。
他にも人事面談や会社説明会など…あらゆるコミュニケーションのシーンの数値化が可能であるとのこと。
IoTにも取り組まれており、小型のデバイスを身に着けて頷きや緊張感などの「空気感を測る」プランもあるのだとか。

音声認識…ではない!コグニティが積み上げたクリーンデータの強み
中川
河野さん
河野さんは「音声認識について自社で突き詰める考えはありません」とキッパリ。
河野さん
センシング技術は精度を上げるためにお金がかかる大企業向けの技術であり、検出・判別のためのアルゴリズム部分は今後論文でオープンになっていくと踏んでいます。
中川
河野さん
ひとつの情報の中にどんな種類がいくつあって、その情報の関係性は…そういったブロックごとのコミュニケーションのルールを形成し、ルールに基づいて膨大なデータを生成しています。
中川
河野さん
中川
河野さん
↓図にするとこんなイメージ
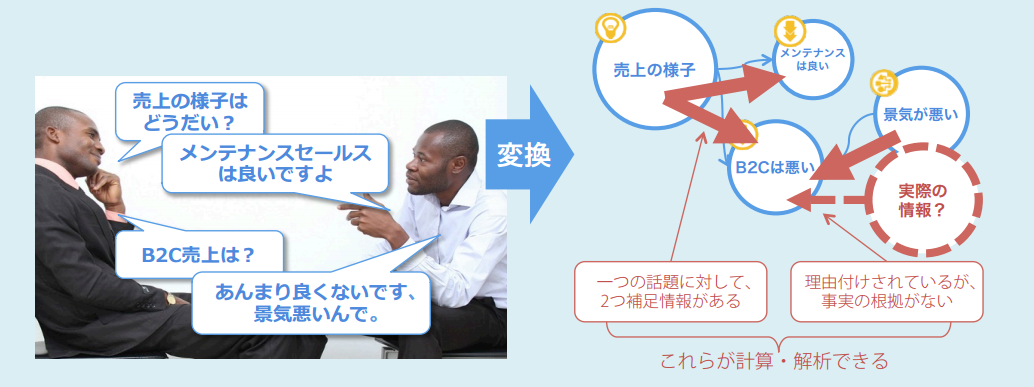
固有名詞に左右されずに意味のまとまりを作りし、それぞれの関係構成を表現。
さらに補足情報まで提示できるという…まるで現代文の先生です。
人間の”知恵”や”知識”のパターン化を目的としたモデリング作成をされているアップ・サイター、その汎用性の高さに驚かされました。
情報工場で人間が生産 5,000本以上のコミュニケーションデータ
中川
河野さん
中川
河野さん
価値あるデータは、クリーンであるべきと考えます。
ノイズデータを作らないためには、まだまだ人のちからが必要です。
ルールに基づいて人が手作業でデータを作る、その先にアルゴリズムのフェーズに至る、と河野さん。
現時点で5,000本以上のシーン毎コミュニケーションデータを分析、データベース化されているのだとか。
中川
河野さん
中川
河野さん
工場生産方式も、工程の単純化によるミスの削減という意図を含みます。
着任前には適正検査を行って適切なパートに作業者を配属したり、それぞれの役割ごとのマニュアルやドリルによる学習を実施しています。
↓作業レクチャーの様子。
テキストを開きながら、みなさんタブレット端末でもくもくと作業をこなされています。
中川
河野さん
これでデータを作り続けているところに、我々のアドバンテージがあると考えています。
多くの企業では、大学生のバイトに辞書作らせてはいおしまい…という展開が多いのではないでしょうか。
このような場合、分野ごとに辞書の作り直しが発生し、かつ汎用性も低くなってしまいがちです。
コグニティでは、役割を細かく分業してマニュアル化・ドリル作成等の教育体制を整えることで、汎用性が高く安定したデータ作成を実現されていました。
河野さん
『AIじゃないじゃん』と言われることもありました。最近、やっと認められてきたと思っています。
多くの人が置き去りにしてきた課題と、数年にわたり粘り強く向き合ってきたコグニティ。
どうやら、最初からアップ・サイターのような「コミュニケーションを見える化するサービス」を作ろうとしていたわけではないようです。
アップ・サイター誕生に至るまでのお話を、河野さんに伺いました。
オートファシリテーションサービスの挫折から渡米経験 アップ・サイターが誕生するまで
河野さん
中川
河野さん
システム導入のハードルが高すぎて、売れなかったんです。
中川
河野さん
ですが、これは日本でまったく売れなかったんです。
商品が売れない頃は、社員の心も離れがちに。社内メンバーからはその頃のことを、『暗黒期』と例えられています。笑
中川
河野さん
検索エンジンは膨大な情報をランキング形式で我々に提供してくれますが、それだけでは納得できる意思決定ができないはず。
情報の偏りを解決する、これが次の時代で勝てる要素になるはずだと思いました。
そこで、コミュニケーションのデータをため続ければコミュニケーションの傾向がわかる・そこから作れるソフトウェアがあるはず…とずっと信じて取り組み続けたとのこと。
契機を求めて、一昨年はアメリカのアクセラレーターに飛び込んだのだそうです。
河野さん
やりたいことよりも”求めてくれるサービスをやるのが一番だ”と考えられるようになり、やっと営業トークの需要が見えたんです。
そうして、アップ・サイターが商品化されました。
現在は製薬メーカーや省庁などとの契約が主立っており、コンサルへのOEM提供等もされているのだそうです。
資金調達が進み、拡大時期を迎えたコグニティの目標は『2021年上場』。
今年は特に海外展開を見据えているのだとか。
オフィスは人がまばらで、在宅勤務の働き方が浸透しているようでした。
取材の際にお話を伺った人事の方も普段は海外で、今回たまたま一時帰国されていたとのこと!
信念を持って突き進む河野さんやコグニティのみなさんと一緒に働きたい方は、こちらの求人をぜひチェックしてみてくださいね。
















