

アメリカの人気クイズ番組・「ジョバディ!」のスタジオに颯爽と登場するやいなや、人間のクイズ王を敗ったWatson。そのWatsonを世に放ったのは、アメリカのIT業界の巨人・IBMでした。
そのIBMが、今度は、「ディベート」という舞台で、人間のチャンピオン(イスラエル国内チャンピオン)を負かしました。
このニュースは、いまから3ヶ月前に世界をかけめぐりましたが、「IBM Debater」と名づけられたこのAI「ディベート」マシン(IBMはAIと呼ばずに、Cognitive computingという言葉を用いていますが)は、一体、どのような仕組みで動いているのでしょうか。
「Watson」については、開発に携わったIBM Research Centerの研究員たちが執筆した論文が、IBM公式ウェブページから、数多く公開されています。これらの(英語)論文を読むことで、クイズ番組「ジョバディ!」に出場して、人間のクイズ王チャンピオンを破った当時の「Watson」の「動作アルゴリズム」の一旦をうかがい知ることができます。
この論文は、以下のIBM公式ウェブーページからダウンロードして、無料で閲覧することができます(ただし英文です)。
▼ IBM Research公式ウェブページ
“The DeepQA Research Team”
なお、その後、医療産業や金融産業などに商用展開されている商用版の「Watson」は、深層ニューラル・ネットワーク(いわゆる「ディープ・ラーニングモデル」)ベースのアルゴリズムに置き換えられているなど、クイズ番組「ジョバディ!」登場当時の「Watoson」とは、エンジンやアーキテクチャはかなり様変わりしているようです。(どのような「ディープ・ラーニング」モデルに置き換えられたのかについては、未だ確たる技術情報は公開されていません)
では、今度の「IBM Debater」についてはどうでしょうか?
2018年9月7日現在、「IBM Debater」にまつわる(IBM公認の「純正」)技術資料としては、IBM米国本社のウェブページ「IBM Project Debater –Debater Datasets」に、トピック別の論文一覧が掲載されています。
このウェブページは一見すると、「IBM Debater」で用いられた「データセット」をダウンロードできるだけのものかと思いきや、そこには以下の論文へのリンク一覧が掲載されているのです。

IBM社「IBM Project Debater –Debater Datasets」より転載
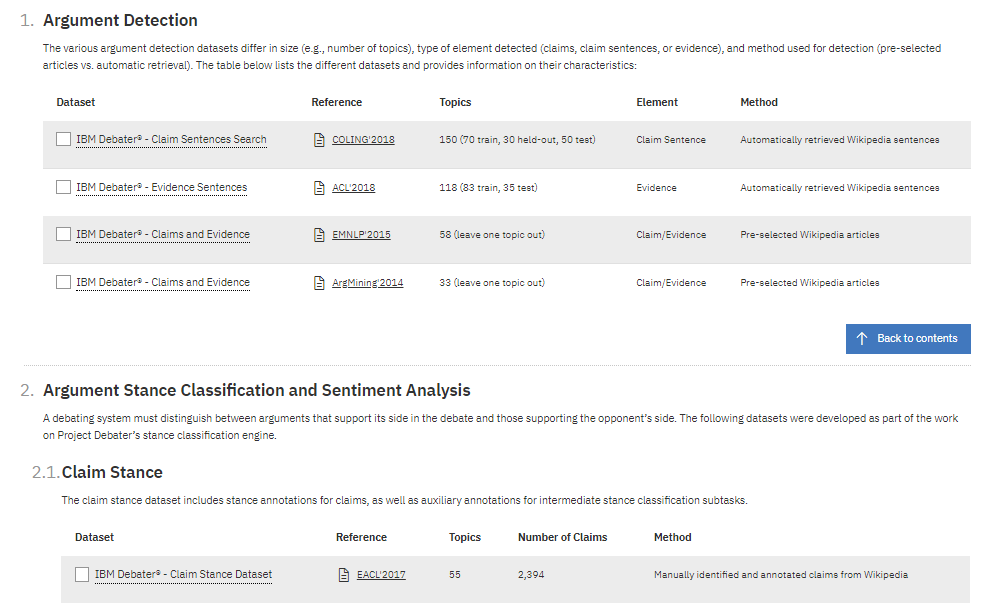
IBM社「IBM Project Debater –Debater Datasets」より転載
ここに掲載されている論文については、まだ内容に立ち入って解説しているウェブページがあまり見当たらないため、今回、新たに連載シリーズとして、これらの論文の中身をひとつひとつとりあげてみていくことを試みてみます。
なお、私は、IBM Debaterの背後に、「IBM Watson」の技術――とくに、LATとよばれる「問われている事柄の実体属性カテゴリ」を推定する「質問意図解釈」技術――が活用されているのではないか、という仮説を立てています。
この連載記事では、この「Watsonの質問意図解釈技術」を、IBM Debaterの仕組みを探るための前提情報として、取り上げていきます。
なお、「AI Machine・AI Agentがディベートを行う」というテーマは、IBMの専売特許ではないようです。
この分野では、すでに、”Argumentation mining“(「議論構造解析」)や”Evidence detection”(「根拠検出」)といった名称の学術研究領域が立ちあがっているからです。
本連載シリーズで取り上げていくように、この学術領域では、日立製作所や、日本の大学に所属する日本人の研究者からも、複数の論文が提出されています。
なお、これらの領域は、英文や日本語の文(章)を解析する自然言語処理(NLP: Natural Language Processing)領域のなかの部分領域に位置づけられるようです。
それでは、ここで、先ほどのIBMのウェブページに公開されている論文の一覧を眺めてみます。
イスラエル(ハイファ)、インド(バンガロール)、アイルランド(ダブリン)の3つの都市にある複数のIBMの研究拠点が連携・協力して、「IBM Debater」の研究が進められている様子を垣間見ることができます。
【 登場する3つの研究拠点 】
・IBM Research – Haifa, Mount Carmel, Haifa, 31905, Israel
・IBM Research – Bangalore, India
・IBM Research – Ireland, Damastown Industrial Estate, Dublin 15, Ireland
【 論文一覧 】
- Ran Levy (IBM Research) et.al., Towards an argumentative content search engine using weak supervision
- Eyal Shnarch (IBM Research) et.al., Will it Blend? Blending Weak and Strong Labeled Data in a Neural Network for Argumentation Mining
- Ruty Rinott (IBM Research – Haifa) et.al., Show Me Your Evidence – an Automatic Method for Context Dependent Evidence Detection
- Ehud Aharoni (IBM Haifa Research Lab) et.al., A Benchmark Dataset for Automatic Detection of Claims and Evidence in the Context of Controversial Topics
- Roy Bar-Haim (IBM Research – Haifa) et.al., Stance Classification of Context-Dependent Claims
- Charles Jochim (IBM Research) et.al., SLIDE – a Sentiment Lexicon of Common Idioms
- Orith Toledo-Ronen (IBM Research) et.al., Learning Sentiment Composition from Sentiment Lexicons
- Orith Toledo-Ronen (IBM Research – Haifa) et.al., Expert Stance Graphs for Computational Argumentation
- Liat Ein Dor (IBM Haifa Reseacrh Lab) et.al., Semantic Relatedness of Wikipedia Concepts – Benchmark Data and a Working Solution
- Ran Levy (IBM Haifa Research Lab) et.al., TR9856: A Multi-word Term Relatedness Benchmark
- Yosi Mass (IBM Haifa Reseacrh Lab) et.al., What did you Mention? A Large Scale Mention Detection Benchmark for Spoken and Written Text
- Liat Ein Dor (IBM Research, Haifa, Israel) et.al., Learning Thematic Similarity Metric Using Triplet Networks
なお、上記のリストには掲げられていませんが、以下の論文も関連するとおもわれます。
・ Ran Levy (IBM Haifa Research Lab) et.al., Context Dependent Claim Detection
IBMの研究員による論文以外に、「IBM Debater」に言及している論文として目に留まる論考としては、一例として以下があります。
・ Paul Reiser (Tohoku University) et.al., Deep Argumentative Structure Analysis as an Explanation to Argumentative Relations, 言語処理学会 第23回年次大会 発表論文集 (2017年3月)
・ Marco Lippi (DISI – Universita degli Studi di Bologna) et.al., Argumentative Ranking
・ (スライド)Elena Cabrio ( INRIA, Sophia Antipolis, France) et.al., ArgNLP 2014 Frontiers and Connections between Argumentation Theory and Natural Language Processing
この連載シリーズでは、上記の論文を一つ一つ取り上げて論じていきます。
目次
- IBMの新プロジェクト「IBM Project Debater」
- 「Debater」の裏側では、「IBM Watson」のエンジンが動いているのか?
- IBM Watsonの「質問意図解釈」エンジン
- Watsonは「質問型」を分類している:「質問で問われている内容は何か?」
- Watsonは、「質問型」を”LAT: the lexical answer type”と呼んでいる。
- 「ジョバディ!」版WatsonのLATは、2,500以上あった模様
- 「変なLAT」
- Watsonの公式技術資料(論文)
- 関連研究領域: 「議論構造解析」(“Argument mining”)・「根拠検知」(”Evidence Detection”)・「サポート性推定」(“Supportive Recognition”)
- 「自動化」の現状:まだ人力で定義した「ルールベース」の特徴量に頼るモデルである
- 日本では、日立製作所から一連の研究成果が出ている。
- シンプルながらも深層ニューラル・ネットワークモデルも提案され始めている。
- 全体を包括する研究領域の名称は、「議論解析」(Argumentation mining)
IBMの新プロジェクト「IBM Project Debater」
それでは、まずはこの「IBM Debater」プロジェクトについてみていきましょう。
以下は、IBM Project Debaterのウェブページです。
IBM公式ウェブページより転載。URL:https://www.research.ibm.com/artificial-intelligence/project-debater/
IBMのこのプロジェクトは、日本のオンライン誌でも記事にとりあげられており、これらの記事を目にした方も大勢折られるとおもいます。
- ITmedia NEWS」2018年6月19日付け記事『IBMのAI「Project Debater」、ディベートチャンピオンを打ち負かす』
- C|net Japan誌 2018年6月20日付け記事『IBMのAIシステム「Project Debater」、ディベートで人間に勝利』
- Gigazine日本語版(2018年06月20日 13時00分配信)「IBMが人間とほぼリアルタイムでディベートできるAIを開発」
(以下、C|Net記事より転載)

(以下、Gigazine記事より転載)

日本IBM公式ウェブページ (2018年6月29日付け記事)「IBM Research AIがディベート術を学ぶ」
「Debater」の裏側では、「IBM Watson」のエンジンが動いているのか?
「ディベートするAI」(”IBM Debater”)の裏側では、「事実(Fact)に関する問い(Question)に答えるAI」である、あの「IBM Watson」が動いているのでしょうか?
というのも、”IBM Debater”は、以下の段階を踏んで「考えている」ように思えるからです。
- 人と会話するなかで、対話相手の人が”いま、話題にしていること”(主題)を、まず、言語解析によって推し量る。
- 次に、(推定した)話題(「主題」)について、対話相手が「賛成」・「反対」、「好意的」・「否定的」のどちらの立場に立っているのかを見極める。
- (1で推定した)いま話されている「主題」(「論点」)について、話し相手とは「『反対』の立場」に立つ「考え」を構築する。このとき、 「反対意見」を裏付ける材料(「根拠」(Evidence))を、アクセス可能な論文データベースや知識文書データベースから探索して、引っ張り出してくる。
上記をみたとき、私は、以下の2つのステップを踏む「Watson」のエンジン(IBMは、AIとは呼ばず、「Cognitive Computing」エンジンと呼んでいる)のデータ処理過程と、
重複する部分があるのではないか、と感じたからです。
クイズ番組「ジョバディ!」(Jeopardy!)に登壇した当時の”Watson”は、少なくとも、大まかに見て以下の2つのステップを踏むことで、「考え」て「答え」ていた、と、IBMの公式論文(後述)は説明しています。
- 「いま、質問文で問われている内容は何(5W1H)か?(地名?年代?人の名前?方法・手段?理由?)」を1つに絞り込んで(「質問意図解析」)
- 「答えとして期待されていること(問われていること)」= 回答「カテゴリ」と、「カテゴリ」(地名、年月日、人名など)が一致する回答候補(の単語 or 語句)を、知識情報データベースのなかにある膨大な文章データのなかから、検索して探し出してくる。
IBM Watsonの「質問意図解釈」エンジン
今日、医療領域や金融領域などの個々の産業分野ごとに商用展開されているIBM Watsonは、深層学習モデルに置き換えられたようですが、クイズ番組 「Jeopeardy!」(ジョパディ!)に登場した頃のWatsonの「質問意図解釈」エンジンは、質問文を構成する単語が事前に定義した特定語を含むかチェックしたり、質問文の文法上の構文構造が、事前定義済みの構造パターンに該当するかといった、個々のチェック項目を、複数の機械学習モデルと統計モデルを同時に走らせてチェックし、個々のチェック結果を、アンサンブル学習的にヒューリスティックに組み合わせるものであったことが、IBM社から公開されている一連の論文によって、すでに明らかになっています。
質問文で何が問われているのかを推定する「質問意図解釈」エンジンも、現在は、深層学習(ディープ・ニューラルネットワーク)モデルに置き換えられた、と見る向きが強い(真相は、IBM社から公式に技術開示がなされていない)ですが、”IBM Debater”の裏側で、「いま議題(争点)になっていることは何か?」=「問われていることは何か?」を判断する工程で、Watsonの一部をなしていたこの「質問意図解釈」エンジンが、動いている可能性が高いと感じています。
(以下、その他 参考)
- 日本IBM「クイズ番組に挑戦した IBM Watson」
なお、「ジョバディ!」出場当時のWatsonと、各業界に商用展開中の現在のWatsonとの技術的な違いについては、以下が参考になります。
- 日経BP (2015年9月11日付け)「Watsonは単なる「質問応答システム」にあらず、CTOが語る全貌 -IBM Watson Solutions Vice President兼CTO、Rob High氏」
Watsonは「質問型」を分類している:「質問で問われている内容は何か?」
KPMGが発行したレポート「KPMG Insights KPMG Newsletter Vol.21, November 2016」では、次のように書いています。
『WatsonはAIというよりも、自然言語を翻訳しているような印象を受けます。
しかし、「この州は、アメリカ合衆国で、もっとも西に位置しています」という問題が出されると、Watsonはまず構文を解析し、「位置する」という動詞をキーに、「州」、「もっとも西」、「アメリカ合衆国」
などにかかっていることを自然言語処理し複数の候補の中から、質問の型の一致、条件の一致、該当語へのリンクの多さなどを見て、総合点から確率を計算し、「アラスカ州」と回答するわけです。こういた点からも、Watsonは人間が理解する仕組みとは違うアプローチを取っているように思われます。
上記のように説明されるWatsonのデータ処理の流れについて全体像を得るために、まずは、日本IBM株式会社が公開している以下のスライドをご覧下さい。
・ 日本アイ・ビー・エム株式会社「質問応答システムWatson: クイズ番組への挑戦」
出典:https://www.obci.jp/wp-content/uploads/2011/11/20110716_OSC_kansai_kyoto_IBMWatson.pdf

出典:https://www.obci.jp/wp-content/uploads/2011/11/20110716_OSC_kansai_kyoto_IBMWatson.pdf
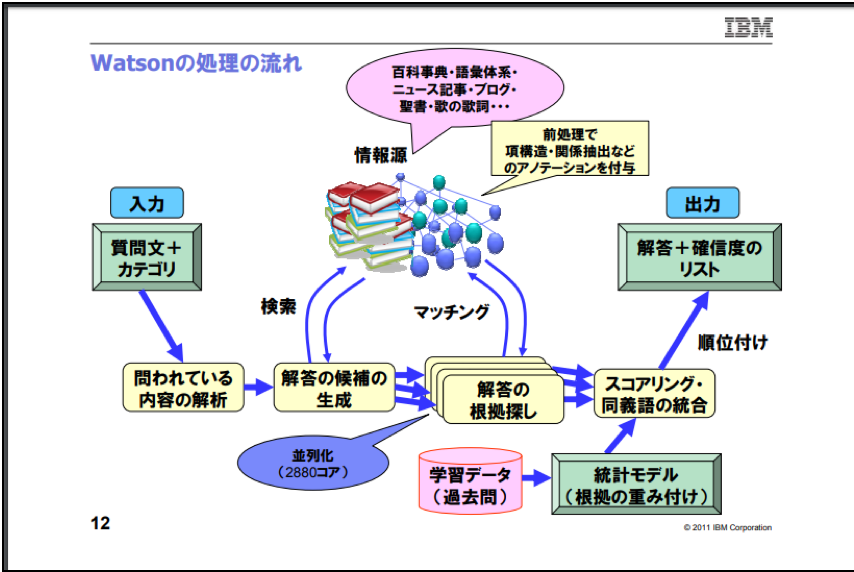
出典:https://www.obci.jp/wp-content/uploads/2011/11/20110716_OSC_kansai_kyoto_IBMWatson.pdf
Watsonは、「質問型」を”LAT: the lexical answer type”と呼んでいる。
- 米国人工知能学会(AAAI)『AI Magazine』”THE AI BEHIND WATSON — THE TECHNICAL ARTICLE” では、LAT(the lexical answer type)と呼ばれる、この「質問の型」が(人間によって事前に)定義されていることが明らかにされています。
As a measure of the Jeopardy Challenge’s breadth of domain, we analyzed a random sample of 20,000 questions extracting the lexical answer type (LAT) when present. We define a LAT to be a word in the clue that indicates the type of the answer, independent of assigning semantics to that word. For example in the following clue, the LAT is the string “maneuver.”
Category: Oooh….Chess
Clue: Invented in the 1500s to speed up the game, this maneuver involves two pieces of the same color.
7 Answer: CastlingCategory: Oooh….Chess
Clue: Invented in the 1500s to speed up the game, this maneuver involves two pieces of the same color.
7 Answer: CastlingAbout 12 percent of the clues do not indicate an explicit lexical answer type but may refer to the answer with pronouns like “it,” “these,” or “this” or not refer to it at all. In these cases the type of answer must be inferred by the context. Here’s an example:
Category: Decorating
Clue: Though it sounds “harsh,” it’s just embroidery, often in a floral pattern, done with yarn on cotton cloth.
Answer: crewelThe distribution of LATs has a very long tail, as shown in figure 1. We found 2500 distinct and explicit LATs in the 20,000 question sample. The most frequent 200 explicit LATs cover less than 50 percent of the data. Figure 1 shows the relative frequency of the LATs. It labels all the clues with no explicit type with the label “NA.” This aspect of the challenge implies that while task-specific type systems or manually curated data would have some impact if focused on the head of the LAT curve, it still leaves more than half the problems unaccounted for. Our clear technical bias for both business and scientific motivations is to create general-purpose, reusable natural language processing (NLP) and knowledge representation and reasoning (KRR) technology that can exploit as-is natural language resources and as-is structured knowledge rather than to curate task-specific knowledge resources.”
この(LATと呼ばれる)「質問(で問われている事柄が属する)型」について、推定したことを手がかりに、Watsonは膨大な文章データ集合のなかから、(問われていることに一致する)適切な回答を探索してくることを、日本IBM東京基礎研究所の金山・武田両氏は、次のように述べています。
金山 博・武田 浩一(日本IBM東京基礎研究所)「Watson: クイズ番組に挑戦する質問応答システム」
(以下、上記の金山・武田より引用する。但し、太字と下線部は、伊藤による。また適宜、改行を入れた)
Watsonが対応しているのは英語の質問文と情報源の処理であるが、ここでは理解を容易にするために、日本語の例を導入する。
質問文:「本州のなかで最も西に位置するこの県は、1871年に発足した」
正答:「山口(県)」
まず、質問文の中のキーワード、この場合「本州」「最も」「西」「県」「1871」などを検索条件として、情報源の中を検索し、それと一緒に出現しやすいキーワードを列挙する。すると、「広島」「山口」「鳥取県」「中国地方」「奥多摩」など、解候補が得られる。問われているもの(これを「質問の型」と呼ぶ)が「県」だということが分かっても、最初から日本の43の「県」だけを考えればよいわけではない。解答は日本の県に限るという知識が質問文には明示されておらず、Watsonには本州に位置する県というものが実質的に日本の県を意味するということは容易には結論づけられないからである。このほかにも、質問の型が「作曲家」だったらどの集合を調べて場よいか、「液体」なら、または「形式」なら一体何を調べるか・・・と考えていくと、質問の型と其の解答になる語句の組合せには際限がなく、関連しそうな語句を大量に調べてもるほかはない。
次に、これらの候補が答えとして適切かどうかを調べるため、情報源の中から根拠を探す。根拠を調べる観点には、「候補が、質問の型である『県』であるか?」「候補が、質問文中の制約『最も西にある』と記述されているか?」「問題文中と同じ時間表現とともに現れるか?」「該当する語句への参照(リンク)がいくつあるか?」などがある。
それぞれの候補について、これらの観点から根拠を見出せるかを表-2に示す。
以下、上記で言及されている「表-2」を転載します。
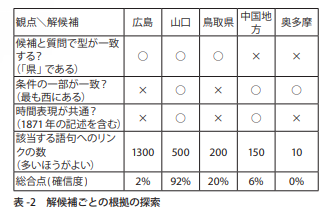
引用:金山 博・武田 浩一(日本IBM東京基礎研究所)「解説 Watson クイズ番組に挑戦する質問応答システム」
すべての観点で根拠を見いだせる解答は存在しないことが多いので、過去の問題から学習した重み付けに基づいた確信度を計算する。この例の場合、正解である「山口」に最も高い確信度が与えられた。なお、このほかに「山口県」という候補もあった場合は、それらを統合した上で確信度を計算する。最終的な確信度が十分に大きければ、ボタンの押下を試みて、それが対戦相手よりも早ければ回答ができる。
問題を解くために必要な情報には、大きく分けて2種類ある。1つは辞書、語彙体系、意味的関係(「坊ちゃん」の著者=「夏目漱石」といった事物の関係)のように構造化されたデータで、もう1つはニュース記事、百科事典の本文、Weblogの記事など、通常の英語で書かれた非構造情報のテキストである。
知識を整理するという意味では、前者の構造化情報が重要かつ扱いやすいが、Jeopardy!が扱うような広い分野の知識を網羅するのは困難である。また、言語の多義性、意味的な曖昧性があるときに、矛盾がないような概念体系を人手で構築するのは困難である。たとえば、Schwarzeneggerは俳優か政治家か、「イヌ」は「ネコ」であるか否か(原注:イヌ科はネコ目であるという点においては正しい。)のように構造化が難しい現象は枚挙におとまがない。
そこでWatsonでは、従来の質問応答システムで試みたように1つの知識体系を整備するという方針ではなく、利用可能な複数の知識を用いることにした。語と語の関係などを整理した語彙体系として、WordNet, DBPedia, YAGOなどを参照している。これにより、「AはBである」というis-aの関係を検証する場合(質問の型がBで、解候補Aが答えとして適切かどうかを調べる)、それぞれの語彙体系に関係が見つかるかをべつべすの観点で見る(表-2に独立の行として○・×を付けるイメージ)ことにより、各体系が網羅性や一貫性に欠ける場合のリスクを低減することができる。
もう一方の情報源の形が、非構造情報、すなわち生のテキストの情報である。重要な事実が多く書かれている百科事典や新聞記事が有用なのは想像に難くないだろう。そのほか、数々の実験を通して、(小野寺注:クイズ番組「ジョバディ!」に勝利するという目的を果たすために)正しい解答を得るために必要な情報は何かを議論していった結果、シェイクスピアの戯曲、聖書、歌の歌詞など、その引用やパロディが問題文中に使われやすいものを加えていった。最終的に情報源は70GBとなった。これはインターネット全体のデータ量よりは遥かに小さいが、無料であるなど入手が容易であり、後述の前処理が妥当な時間で実行できて、実メモリに載せられる量であり、かつ出題される問題の多くをカバーするという点で絞り込まれたものである。
人間の頭脳では決して憶えきれない量の生のテキストを一語一句違わすに暗記していることになるが、文字列そのものよりも意味的内容が重要である場合が多い。そこで、テキストに対して事前に構文解析や関係抽出をして、その結果を生のテキストに付与しておくという「前処理」を施す。これにより、豊富な情報を高速に検査することが可能となった。
テキストからの情報抽出は、非構造情報を構造情報に転換し、扱いやすい観点を増やすことに寄与する。たとえば、WikipediaのBackgammonの項目の1文目には、”Backgammon is one of the oldest board games for two players.”という記述があるが、「A is B」や「A is one of B」などの構文パターンが「AはBの一種である」ことを示すという知識を用いれば、「Backgammon」は「game」であるという知識が得られる。この手法により全文書を解析しておけば、新たなis-aタイプの概念体系を生成することができる。会席誤りによってノイズが生じることもあるが、人手で作った既存の概念体系とは異なる客観的で網羅性のあるデータを作ることができ、答えらしさの判定に寄与した。筆者らのIBM東京基礎研究所チームは、2007年12月にWatsonプロジェクトへの参画を依頼され、以後このような情報源からの情報抽出に主な貢献をした。
UIMA (Unstructured Information Management Architecture)は、自然言語のような解釈に曖昧性のあるデータに対して、其の構造や意味を、順次メタデータとして加えていく仕組みで、2006年からオープン・ソース。ソフトウェアとして公開され、2009年からOASIS (Organization for the Advancement of Structured Information Standards)の標準となっている。Watsonでは、質問文の分析・根拠の探索と、情報源の前処理を含むすべてのプロセスがUIMA上のプラグインとして実装されている。例として、図-5に質問の解析の概略を示す。
以下、上記で言及されている「図-5」を転載します。

引用:金山 博・武田 浩一(日本IBM東京基礎研究所)「解説 Watson クイズ番組に挑戦する質問応答システム」
次に、PC Watch誌とのインタビューで語られている内容もおさえておきます。
PC Watch「■森山和道の「ヒトと機械の境界面」■ クイズ王を破ったIBMの質問応答システム「Watson」とは ~ 人間より速くクイズを解く知的処理の仕組みと今後の可能性」のインタビューで、武田氏はWatsonについて、次のように解説しています。
『質問は多様である。いったん使われた質問は出てこない。だから過去問を単純に覚えるだけでは何の役にも立たない。過去問は、答えの信頼性を計算する仕組みづくりにのみ役に立つ。
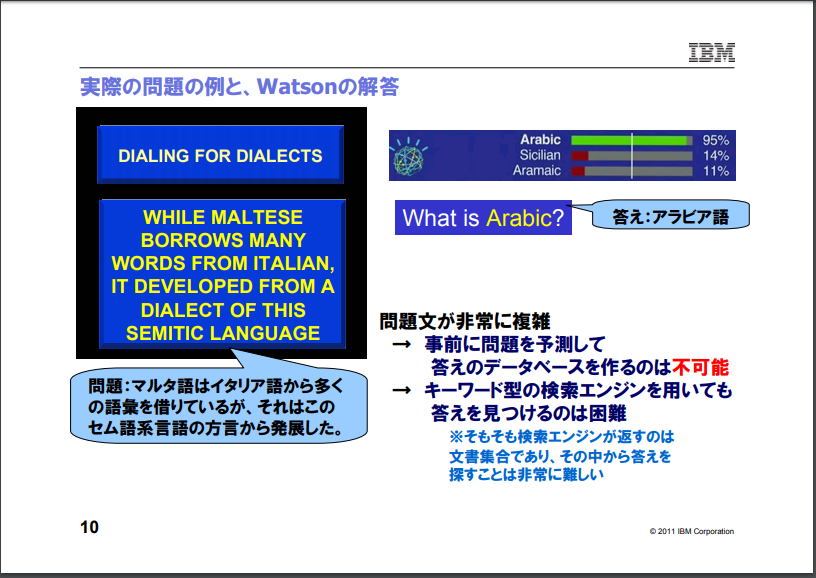
問題文には「型」がある。例えば「4文字の言葉」だったら「4文字」、国だったら「国名」が「型」になる。もっともよく出てくるような型、すなわちカテゴリの質問でもすごく少ない。「Jeopardy!」の問題製作者は毎回カテゴリを作っているようなものなのだ。過去問が同じ物を使わないという特徴があるので、常に新しい質問があたえられても、安定して答えられなければならない。
例えば「マルタ語はイタリア語から多くの語彙を借りているが、それはこのセム語系言語の方言から発展した」という問題文がある。この答えは「アラビア語」である。しかし、問題文をよく読めば分かるが、問題文の一部(イタリア語から多くの語彙を借りている)は解答の手がかりにまったく寄与していない。つまり問題文が何を意味しているのか、どこが手がかりなのかをまず探さなければならないのである。
人間とWatsonのような質問応答システムの処理の違いを示すために、日本語での例として武田氏は「この県は本州の中でもっとも西に位置しています」という問題文を示した。人間の場合、「本州」という言葉を聞いたとたんに、これが「日本」のことだとわかるし、「県」に関する問題だとわかる。つまり人間は「本州」という単語について紐づけられた非常に豊富なセマンティクス(意味情報)を持っている。
しかしWatsonはそのような情報を持っていない。日本であることすらわからない。全ての単語について意味情報を想定して入力することは不可能なので、「本州」という言葉が日本と関係しているらしいということは、豊富な情報源から読み取る必要がある。だが問題文と全く同じ形式で情報が表現していることは少ない。
( 中略 )
Watsonの場合は、質問文が構造的にどうなっているかを分析して、「この県」が聞かれている対象だろうとあたりをつける。そして背後にある豊富な情報源、すなわち百科事典やWikipediaなどデジタル化された知識の情報源から、「こういう情報」と表記しやすいものは解の候補だとする。つまり文字通りでなくても内容に近いものを探して列挙する。これが答えの候補になる。
次にその答えの候補を、さまざまな観点で検証する。例えば、質問の型が一致しているか、条件が一致しているか、性別が一致しているか、該当語へのリンク数はどうか。このような「観点」で見ていく。正解に近ければ近いほど多くの観点を満たしていると考える。山口は本州の西にある、山口は県だといったことを確認していくのだ。観点の重み付けが難しいところだが、重み付けについては過去問が使われる。それぞれの観点がどんな問題のときでもまったく同じ重みではうまくいかないので、場所を問う質問にはこういう観点でいこうといった、解き方が正しいかどうかを過去問から検証するのである。
そのためのアーキテクチャ、Watsonを構成する処理のフローはこうだ。まず質問とカテゴリが来る。その構文を解析して何が問われているか手がかりの部分と、対象の問われている「型」を推定する。その手がかりで情報源を調べにいく。候補をいくつかあげる。その候補を再度、情報源に照らし合わせる。候補が得られたら、その候補を手がかりに埋め込む。手がかりのところに候補を埋め込んだものが「仮説」になる。その仮説を再度知識源に検証に行く。それが正しい解答であれば情報源の中に一致が見られるはずである。それを「観点」ごとに行なって、結果をスコアとして和をとる。それを合わせることでもっとも高い確信度のものを解答として答える。おおまかに言えばWatsonはこういう計算をしているという。
以上、Watsonにおいて、「質問型」の推定を行う仕組みが、重要な役割を果たしていることを見てきました。
この「質問型」推定エンジンについては、IBMが過去に公開した以下のWatson技術論文が、詳しく論じています。
- Question analysis: How Watson reads a clue, Publication Year: 2012, Page(s):2:1 – 2:14
この論文の概要(Abstract)は、まず次の一文で始まります。
The first stage of processing in the IBM Watson™ system is to perform a detailed analysis of the question in order to determine what it is asking for and how best to approach answering it. Question analysis uses Watson’s parsing and semantic analysis capabilities
ここで、”a detailed analysis of the question in order to determine what it is asking for and how best to approach answering it.!”(伊藤による試訳:「質問で問われていることは何なのかを、質問(文)を解析することで突き止める。次に、問われている事実について、うまく答えるための最良の方策を考える」)
が、鍵になります。
上の文に続けて、概要は次のように言います。
2) terms in the question that indicate what type of entity is being asked for (lexical answer types); 3) a classification of the question into one or more of several broad types
(「2. 問われている事項の属性・類型は、どれに属するのか(例:地名、年代、人名、方法など)3.質問(文)が「どの属性の質問」に属するのかを見極めること」)
このあたり、blackaplysia氏のQiita記事(最終更新日:2015年09月28日)「密かに日本語化されたWatson Natural Language Classifier (NLC)でテキスト分類」は、IBMの2本の論文の内容を以下のように要約しています。
- ( blackaplysia氏が参照しているIBMの論文 )
A. Lally, et al. (2012). Question analysis: How Watson reads a clue. IBM Journal of Research and Development, 56(3), 2:1-14. - Rob Yates (2015). Introducing the IBM Watson Natural Language Classifier. IBM Watson Developers Community Blog.
たとえば、When was Mozart born?という質問について考えてみましょう。Watson QAでは、このテキストを解析するにあたり、Lexical Answer Type (LAT)というカテゴリを選定します。Jeopardy!の使用したデータセットでは、この質問に対するLATはDATE_OF_BIRTHという値が高い確信度をもつように多数のルールを作成することでチューニングされていました。つまり、Jeopardy!型Watson QAの本質は、対象ドメインに合致したLATを恣意的に選択し、適切なLATを選択するためのルールセットをWikipedia、DBPedia、WordNetなどから機械学習によって大量に作成、それを数年かけて細かくチューニングし、並列処理によって反応速度を確保した、というものでした。
しかし、LATはIBM Watsonチームが長い年月をかけてJeopardy!用にチューニングしたものであって、汎用性はありません。たとえば、私たちが新しいドメイン(問題領域)での質問応答システムを構築したいと思うと、新たにこのチューニングを行う必要があります。前述の文献によればこの部分は多くのPrologプログラムで構成されており、一般の利用者がチューニングを行うことは至難であると思われます。
一方、NLCでは、質問分析を深層学習で行うことができます。詳細は公開されていませんが、すでにwikipediaなどの知識に基づいて構成された知識モデルに加えて、私達のドメイン知識を追加することで、自然な分類器を作ることができるようになっているようです。
- Leonard Swiezinski “Lifecycle of a Jeopardy Question Answered by
Watson DeepQA”
(以下、上記論文より引用。但し、太字と下線部は伊藤による)
1.1.2 Question Answering
In contrast to IR, the term question answering (QA) refers to a slightly different concept, where the
result is not a list of documents, but the actual answer to the question.2
It seems fair to say, that QA
is an extension of IR in a way, that it performs additional tasks and adds semantics:
- Determine the question focus. (e.g. “When” in “When was Mozart born?”)
- Determine the lexical answer type (LAT) for a question. (e.g. date of birth)
- Retrieve the single correct information fragment that answers the question (answer). (e.g.
27 January 1756)
– Retrieve nothing else.
- Optionally present the answer in natural language. (e.g. “Wolfgang Amadeus Mozart was
born on 27 January 1756.”)
Just like in IR, QA systems can either be bound to a specific domain, or otherwise follow a general
purpose approach. Usually the latter is less efficient with respect to result quality. In order to judge
the performance of a QA system, meaningful evaluation is needed. While precision, the percentage
of correctly answered questions, is a common measure, in some cases answer can be ambiguous. In
this case the answers need to be normalized by automatic methods or by human labor.”
・IBM Watson Group (Chantilly, VA, United States), Watson Discovery Advisor: Question-answering in an industrial setting(https://www.researchgate.net/publication/303864511_Watson_Discovery_Advisor_Question-answering_in_an_industrial_setting)
“What is clear, however, is that the (incorrect) candidates are not the “right type of thing” to be an answer to this question, i.e., they are not wars. One reason these non-war candidates are ranked above the correct answer, in this case, has to do with the identification of the question’s Lexical Answer Type (LAT), the word or phrase in the question that indicates the type of thing that an answer to the question would be an instance of.
WDA’s ranking models promote answers which are appropriate to the LAT above those that are not.
Since WDA fails to find the LAT for this question (war), the correct answer is not appropriately ranked.
One general complication with running WDA on Quiz Bowl questions is that they involve multiple sentences.
This complicates the LAT identification task.
The version of Watson designed for the Jeopardy! challenge assumed that the question clues would be a single sentence or a structured input of a single sentence clue and a short category label.
Both the Watson Jeopardy! system and WDA are optimized for that use case. To deal with the Quiz Bowl questions, the question analysis mechanisms, namely the LAT identification models, would need to be retrained to handle multi-sentence input.
このLATについては、以下の論文で、詳細に解説されています。
- Typing candidate answers using type coercion
JW Murdock, A Kalyanpur, C Welty, J Fan, DA Ferrucci, DC Gondek, L Zhang, H Kanayama , IBM Journal of Research and Development 56(3/4), 7:1 – 7:13, IBM, 2012
この論文の2ページ目で、LATは以下のように定義されています。
以下、上記論文からの引用
“The lexical answer types (LATs) that the question is asking for, as identified by DeepQA’s question analysis module [8].
・ A LAT is a text string indicating the type of answer being sought (e.g., Bactor,[ Bcountry,[ and Bscarefest[).
・A candidate answer from DeepQA’s candidate generation module [5].”
以上、入力文が「主題としている事柄」(LAT)を推定し、その「主題」について、的外れではない情報(回答なり受け答えなり、ディベートにおける「賛成」材料・「反対」材料なり)を、膨大なテキスト文書データベースから「検索」してくる「仕組み」として、「IBM Watson」の技術が、「IBM Debater」でも転用できる余地がかなり大きいことが、感じられてくるのではないでしょうか。
「ジョバディ!」版WatsonのLATは、2,500以上あった模様
この「LAT」ですが、クイズ番組「ジョバディ!」に出演した当時のIBM Watsonには、一体、何個のLATが定義されていたのでしょうか?
その疑問に答える鍵が、スティーブン・ベイカー(原著)・土屋 政雄(訳)『IBM 奇跡の”ワトソン” プロジェクト』(早川書房)の一節にあります。
まず、この本の180ページ目に、以下の記述があります。
(俊斎注: 以下、「フェルーチ」は、IBM Watson開発プロジェクトを率いたリーダー(当時)の名前です)
「フェルーチの言語処理プログラマが2年以上の時間をかけて、この種のヒントの解析方法を教え込んできた。ジョバディヒント集から2,500個のLAT(語彙的に見た答えの型)を抽出したとき、最も出現頻度の高かったのが「彼」、つまり人間の男だ。このヒントで男の名前が求められていると知ることは、ワトソンにとって難しくなかったはずだ。」
つまり、ジョバディ!に出場するために開発されていた一番初期の「Watson」は、少なくとも、その開発の途中の段階では、「2,500個のLAT」が、人間のプログラマによって「ベタ打ち」(hard coding)で書き込まれていたことになります。
しかし、最終的にクイズ番組「ジョバディ!」にお目見えしたときの「Watson」に、いったい何個のLATが搭載されていたのかは、上の記述からははっきりしません。
なお、先ほどの文献の121ページ目には、以下の記述があります。
「これまでの数週間で、ファンと同僚はジョバディヒント集の分析から2,500個のLATを見出し、頻度によってランクづけしていた。LATが具体的であればあるほど、ブルーJにはわかりやすい。歌・:王様・犯罪者・植物などは一瞬で探し当てられる。だが、ほとんどのLATはもっと曖昧だ。たとえば「彼」は最も出現頻度が高く、ヒントの残りをどう調べていけばそれが見極められるのか――これからの数ヶ月で、ファンはそれをブルーJに教えていかなければならない。」
なお、「ブルーJ」とは、「Watson開発計画」のプロジェクトの名称です。「ブルー」の文字は、IBMが1997年にチェスの人間チャンピオン(ガルリ・カスパロフ)を打ち負かした「ディープ・ブルー」から「ブルー」の文字を譲り受けてつくられたそうです。このあたりは、同書(『IBM 奇跡の”ワトソン”プロジェクト』)の中で以下のように解説されています。
「ビックブルーのブルーにJeopardy,(ジョバディ)のJをとり、プロジェクトを「ブルーJ」と名づけた。2006年暮れ、クリスマス休暇が始まる直前にホーンに会いに行き、可能かどうかの検討に6ヶ月ほしいと申し出た。」(前掲書、59ページ目)
「変なLAT」
また、先ほどの文献の121ページ目には、以下のとても面白いくだりがあります。
以下、少し長いですが、前掲書の243~244ページ目を転載します。
一方、ジェイムズ・ファンは、ワトソンが主題を把握しそこねたヒントの数々を見直していた。ホーソーンでのある日の会合で、特別に難しいヒントを持ち出した。部門は「郵便事情」、ヒントは「知られている最初の航空郵便サービスは、1870年、このコンベイアンスによってパリで始まりました」だ。
ワトソンはこのヒントを分析して、「コンベイアンス」を見つければよいと結論した。つまり、「コンベイアンス」がLAT(語彙的に見た答えの型)だ。
だが、コンベイアンスとは何だろう。手元にあるどのオントロジーを調べても、そんなグループ分けはない。樹木・色彩・大統領(さらにはアイスクリームのフレイバー)などのグループはあるが、コンベイアンスはない。辞書で調べても、コミュニケーションから権利譲渡書まで、さまざまな意味があってはっきりしない。確かに輸送手段という意味もあるが、これに的を絞って答えを見つけることは、コンピュータには至難の業だろう。
どうすればいい・・・・・・。ファンはLATの新しいグループ分けを試してみた。
6月の午後、あるアルゴリズムチームの会合で「変なLAT」というグループを提案し、ワトソンにどう扱わせるかを説明した。
フェルーチは顔をしかめた。響きが気に入らない。「変な?それは君がいま言い出しただけの言葉で、数学的に分類する方法などあるまい」と言った。
花とか大統領とは病気といった普通のLATは、ワトソンに重要な情報を与え、検索の範囲を劇的に狭める働きをする。だが、「変な」などという具体性のない言葉は、コンピュータをとんでもない方向に飛び出させるだけではないか。ヒントからあるかなきかの関連性を掘り出し、大量のノイズを――誤った可能性を――集めてくるだけではないのか・・・・・・。
「変かどうか判定する方法はあります」とファンは言った。「YAGOを使います。問題のLATがYAGOに何度出てくるかを調べ、なければ『変な』に分類します」。
YAGOとは、200万超のエンティティの詳細情報を集めた巨大な意味データベースだ。
「頻度による分類か」とフェルーチは言った。
ワトソンのプログラミングに残された時間は、あと数週間しかない。
この「変な」グループの追加は無駄な回り道に思えた。だが、結局、ファンにOKを出した。「妙だと思うことがあって、2、3日で直せそうだったら、やれ」と言った。言いながら、土壇場に来ての変更はどうなのだろう、と心配した。いくつかのヒントでは有効でも、他の多くをめちゃくちゃにしないだろうか。それに、解決すべき問題はまだ数限りなくある。」
「ジョバディ!」に初お目見えする「IBM Watson」が、IBMの研究所のワンフロアで開発されていた当時の血と汗と涙の雰囲気が伝わってくる文面です。
Watsonの公式技術資料(論文)
IBMがWatsonについて、これまで公式に公開してきた論文の一覧については、すでに述べたように、IBM Researchの公式ウェブページのなかの”The DeepQA Research Team“のページで掲載されています。
【 以下、上記ウェブページからリンクが張られている論文の一例 】
- Decision Making in IBM Watson Question Answering, J. William Murdock, Web presentation: Ontology Summit 2015
- Unsupervised Entity-Relation Analysis in IBM Watson, Aditya Kalyanpur, J William Murdock
- WatsonPaths: Scenario-based Question Answering and Inference over Unstructured Information Adam Lally, Sugato Bachi, Michael A. Barborak, David W. Buchanan, Jennifer Chu-Carroll, David A. Ferrucci*, Michael R. Glass, Aditya Kalyanpur, Erik T. Mueller, J. William Murdock, Siddharth Patwardhan, John M. Prager, Christopher A. Welty. IBM Research Report RC25489, IBM, 2014
- Question answering in natural language narratives using symbolic probabilistic reasoning, H Hajishirzi, E T Mueller, Proceedings of the Twenty-Fifth International Florida Artificial Intelligence Research Society Conference, 2012
- Question analysis: How Watson reads a clue, A. Lally, J. M. Prager, M. C. McCord, B. K. Boguraev, S. Patwardhan, J. Fan, P. Fodor, J. Chu-Carroll, IBM Journal of Research and Development 56(3.4), 2–1, IBM, 2012
- Fact-based question decomposition in DeepQA, A. Kalyanpur, S. Patwardhan, B. K. Boguraev, A. Lally, J. Chu-Carroll, IBM Journal of Research and Development 56(3.4), 2012
- When Did that Happen? — Linking Events and Relations to Timestamps, D. Hovy, J. Fan, A. Gliozzo, S. Patwardhan, C. Welty, Proceedings of the 13th Conference of the European Chapter of the Association for Computational Linguistics, 2012
- A framework for merging and ranking of answers in DeepQA, DC Gondek, A. Lally, A. Kalyanpur, JW Murdock, P. Duboue, L. Zhang, Y. Pan, ZM Qiu, C. Welty, IBM Journal of Research and Development 56(3/4), 14, 2012
- Relation extraction and scoring in DeepQA, C. Wang, A. Kalyanpur, J. Fan, BK Boguraev, DC Gondek, IBM Journal of Research and Development 56(3/4), 9, 2012
- Automatic knowledge extraction from documents, J. Fan, A. Kalyanpur, DC Gondek, DA Ferrucci, IBM Journal of Research and Development 56(3/4), 5, 2012
- Structured Data and Inference in DeepQA, A. Kalyanpur, B. Boguraev, S. Patwardhan, J.W. Murdock, A. Lally, C. Welty, J. Prager, B. Coppola, A. Fokoue, IBM Journal of Research and Development 56(3/4), 10:1 – 10:14, IBM, 2012
- Identifying implicit relationships, J. Chu-Carroll, E. W. Brown, A. Lally, J. W. Murdock, IBM Journal of Research and Development 56(3/4), 12:1 – 12:10, 2012
- Textual evidence gathering and analysis, J. W. Murdock, J. Fan, A. Lally, H. Shima, B. K. Boguraev, IBM Journal of Research and Development 56(3/4), 8:1 – 8:14, 2012
- Structured data and inference in DeepQA, A. Kalyanpur, B. K. Boguraev, S. Patwardhan, J. W. Murdock, A. Lally, C. Welty, C.; J. M. Prager, B. Coppola, A. Fokoue-Nkoutche, L. Zhang, Y. Pan, Z. M. Qiu, IBM Journal of Research and Development 56(3.4), 2012
- Statistical Approaches to Question Answering in Watson, J. W. Murdock, G. Tesauro, Mathematics Awareness Month theme essay, Joint Policy Board for Mathematics (JPBM), 2012
- Relevance Feedback Exploiting Query-Specific Document Manifolds, Chang Wang, Emine Yilmaz, and Martin Szummer, The 20th ACM Conference on Information and Knowledge Management (CIKM2011)
- Manifold Alignment, Chang Wang, Peter Krafft, and Sridhar Mahadevan, Manifold Learning: Theory and Applications, Taylor and Francis CRC Press, 2011
- Statistical source expansion for question answering, Nico Schlaefer, Jennifer Chu-Carroll, Eric Nyberg, James Fan, Wlodek Zadrozny, David Ferrucci, CIKM ’11 Proceedings of the 20th ACM international conference on Information and knowledge management , 2011
- Fact-Based Question Decomposition for Candidate Answer Re-Ranking, Aditya Kalyanpur, Siddharth Patwardhan, Branimir Boguraev, Adam Lally, and Jennifer Chu-Carroll, Proceedings of the ACM Conference on Information and Knowledge Management (CIKM), 2011, pp. 2045–2048
- Relation Extraction with Relation Topics, Chang Wang, James Fan, Aditya Kalyanpur, and David Gondek, The 2011 Conference on Empirical Methods in Natural Language Processing (EMNLP 2011).
そのほか、和文の解説ウェブページとしては、以下があります。
- 【 IBM Watson Blog 】(2017年1月16日付け記事)「IBM Watson の仕組み:機械学習で洞察の精度を高める(前編)」
- 【 IBM Watson Blog 】(2017年1月16日付け記事)「IBM Watson の仕組み:機械学習で洞察の精度を高める(後編)」
(以下、上記の解説ウェブページ「後編」より引用)
基本的に Watson は活用する分野ごとに異なるデータを人間がインプット作業を行う。インプットしたデータから精度の高い提案をするために、すべての専門分野において Watson が用いる共通の手法がある。
名詞や動詞などの品詞を抽出し仮説を生成する「証拠加重スコア」という統計モデル手法だ。このモデル手法は、生成した仮説を、事前に読み込んだデータから証拠のスコアとランクを付け、応答がどの程度の評価を獲得したかで信頼度を評価するというもの。
上の文章は、実際に米国のクイズ番組「ジョパディー(Jeopardy)」で登場した問題だ。人間なら文章を見ただけでなんとなく質問のイメージが頭の中に湧く(理解できる言語の場合)が、 Watson のようなコンピューターにはそれができない。事前にインプットしたデータから文章を区切り、名詞や動詞などのワードの意味を理解する必要がある。
たとえば先ほど紹介した質問に回答する場合、まず「これはどんなタイプの質問なのか」「どんな回答を期待しているのか」を推測。文章のなかで Watson が重要だと判別した品詞をピックアップし、これらの品詞をパズルのように組み替えながら質問の意味を洞察する。
次に、過去にインプットした文章と照合し、回答として関連性の高いと思われるデータをピックアップ。ピックアップしたデータの中から、独自のアルゴリズムを用いて関連性の高いデータソースを抽出する。
いくつか関連性の高いデータソースを縦断的に解析し、最も信頼性の高い回答を洞察するのである。このように Watsonは、読み込んだ大量のデータを基に質問と回答を分析し、洞察を収集してより精度の高い考察を可能にしている。
これらの手法や過程を経て Watson は、人間の専門家が十分な情報に基づいた意思決定をサポートできるのだ。
以上、入力文が「主題としている事柄」(LAT)を推定し、その「主題」について、的外れではない情報(回答なり受け答えなり、ディベートにおける「賛成」材料・「反対」材料なり)を、膨大なテキスト文書データベースから「検索」してくる「仕組み」として、「IBM Watson」の技術が、「IBM Debater」でも転用できる余地がかなり大きいことが、感じられてくるのではないでしょうか。
関連研究領域: 「議論構造解析」(“Argument mining”)・「根拠検知」(”Evidence Detection”)・「サポート性推定」(“Supportive Recognition”)
ある主張を「支持する根拠となる材料」 or 「反論する根拠となる材料」を文章集合から自動検索するアルゴリズムとして、「根拠検知」(”Evidence Detection”)・「サポート性推定」(“Supportive Recognition”)と呼ばれる分野があります。
これらの分野は、「議論構造解析」(“Argument mining”)という、より大きな研究領域のなかの部分領域をなしているようです。
「自動化」の現状:まだ人力で定義した「ルールベース」の特徴量に頼るモデルである
これらのアルゴリズムは、テキスト解析して、ある主張を裏付ける根拠や、否定する反論根拠となるテキスト部分を自動抽出するアルゴリズムのようです。
自動抽出といっても、IBMから公開されている論文を見る限り、事前に定義済みの特定の文言を文字列検索したり、あらかじめ定義済みの文構造パターン(ひとつの文(sentence)の主語・述語・目的語(補語)の文構造)に該当するかどうかを2値判定(該否判定)したりといった、「ルールベース」の色合いの濃い「クラス分類」タスクモデルといったところです。
以下は、イスラエルにあるIBM Haifa Research Centerと、アイルランドとインドにあるIBMの研究所に所属する研究員による共同執筆論文
- ・ Ruty Rinott (IBM Research Haifa) et.al., Show Me Your Evidence – an Automatic Method for Context Dependent Evidence Detection, EMNLP 2015
以下はIBM Haifa Research Center所属の研究員による論文
- Automatic Claim Negation: Why, How and When, ACL Workshop 2015
日本では、日立製作所から一連の研究成果が出ている。
この領域におけるIBM以外の論文としては、2015年以来、日立研究所から同じ論文陣から、複数の論文が出ています。
日立の論文の多くは、(日本の)人工知能学会全国大会で発表されており、日本語で読むことができます。
- 佐藤 美沙(日立製作所 研究開発グループ)ほか「ディベート型人工知能によるサポート性推定に基づく反論生成」, 2018年度 人工知能学会第32回全国大会
- 柳井 孝介(日立製作所 研究開発グループ)ほか「ディベート型人工知能のための言語的証拠性推論問題の定式化」
- 佐藤 美沙(日立製作所 研究開発グループ)ほか「ディベート人工知能における影響関係認識のためのテキスト内の論理構造に関する考察」2016年度 人工知能学会第30回全国大会
- 柳井 孝介(1日立製作所中央研究所)ほか「ディベート人工知能における意見生成」, 2015年度 人工知能学会第29回全国大会
- 佐藤 美沙(日立製作所)ほか 「意見文章自動生成のための組合せ構文特徴を用いたサポート性推定」人工知能学会設立30周年記念論文特集, 人工知能学会論文誌31巻6号AI30-L (2016年)
日立から出ている英文論文としては、”End to end Augument Generation System in Debating”があります。
- Misa Sato (Hitachi Ltd. Research & Development Group) et.al., End-to-end argument generation system in debating, ACL-IJCNLP 2015
日立の論文も、アノテーション済みの教師用データをもとに、「教師あり学習」で、主張を裏付ける(supporting)文字列を参照文書集合から抽出したり、主張に反論を加える為の材料となる文字列を抽出するアプローチをとっていますが、そこで「素性ベクトル」を生成するに先立ち、あらかじめ人力で作成した「ルール」が用いられているようです。
シンプルながらも深層ニューラル・ネットワークモデルも提案され始めている。
「ルールベース」ではなく、人工知能モデルによって全自動(”end-to-end”)に行うモデルとしては、Imperial College of Londonから出ている”Identifying attack and support argumentative relations using deep learning”論文が、2017年に国際学会誌 EMNLPに掲載されています。
- Oana Cocarascu & Francesca Toni (Imperial College of London), Identifying attack and support argumentative relations using deep learning, EMNLP 2017
以下が論文中に掲載されているモデルの模式図ですが、LSTMブロックを含みながらも、SoftMax関数を最後の出力層にもつシンプルなMLP(多層パーセプトロン)です。
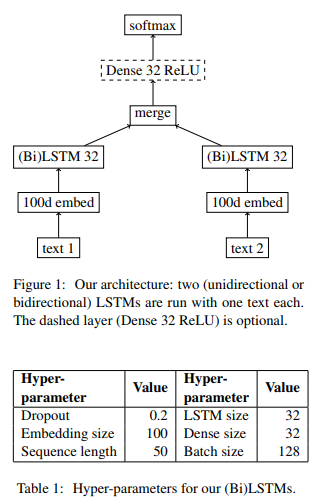
全体を包括する研究領域の名称は、「議論解析」(Argumentation mining)
なお、この分野は、「議論解析」(Argumentation mining)という名前がアカデミズムの世界では名づけられているようです。たとえば、以下の論文があります。
- Lucas Carstens & Francesca Toni (Imperial College London), Towards relation based Argumentation Mining, ACL Workshop 2015
日本語では、以下の解説資料があります。
- 岡崎 直観(東京工業大学大学院)「自然言語処理による議論マイニング」
- 柳井 孝介ほか 「AIの基礎研究 ディベート人工知能」
また、和文の論文としては以下があります。
- 森尾 学 & 藤田 桂英 「議論マイニングによる議論掲示板利用者の能力推定」情報処理学会第79回大会
以上、取り上げた論文について、後続の記事で、内容をひとつひとつとりあげてみていきます。
筆者:伊藤 俊斎

統計数学や機械学習に関心を寄せる下町・長屋暮らしの一職人。
本業は、金魚すくい屋。長屋のはす向かいに住む幼馴染(おさななじ
み)の坂東 萬作さん(ばんどう まんさく。浮世絵師(兼)和傘職
人)と、数年前に、いつのもように、しょうゆ団子を片手に、カルタ
遊びに興じていたところ、携帯ラジオから、「AIが人から仕事を奪う
時代がやってくるかもしれない」と声が聞こえてきて、金魚すくいや
花火師も、商売を召し上げられるのかと慌てふためき、2人で新宿に
ある紀伊国屋書店(南店)に駆け込んでAIについて調べ始める。
もともと、古来より日本に伝わる占い術を、和算や西洋数学(統計
学)で裏付けることが2人の趣味であり、数学の稽古は積んでいたこ
とから、数式が並ぶ機械学習や統計的学習理論の本は、さくさく読み
進めることができたころから、AIを学ぶ習慣が付いた次第です。
金魚がゆらゆらと水のなかをたゆたう姿を見ていると、うっとり時が
過ぎるのを忘れてしまう。だから、いくらAIに詳しくなっても、予
備校講師や「AI塾」を主宰して日銭を稼ぐ商売を替える気はさらさ
ら起きないのであろう。


























