

「自然言語処理」という言葉を目にしたことがある人も多いでしょう。人間の言葉を機械が扱えるようにする自然言語処理は、チャットボットなどに活用され、研究も盛んに行われています。
今まで人間の言葉を「理解する」ことに主眼が置かれていた自然言語処理の研究ですが、現在の英語圏における自然言語処理の最新記事においては、「予測」や「生成」といった単語がキーワードとなっています。
そこでこの記事では、グローバルな自然言語処理研究のトレンドを紹介し、それを生かしたどんなビジネスが生まれているのか、そして生じてくる課題を詳しく紹介していきます。
目次
世界の自然言語処理研究の最前線
解析から予測、そして生成へ
自然言語処理(英語表記:Natural Language Processingの頭文字をとってNLPと略記されることもある)とは、コンピュータに(英語や日本語のような)ヒトが使っている言語を処理させる技術を意味します。この技術はチャットボットや機械翻訳に応用されており、すでに日常生活に溶け込んでいるとも言えます。
自然言語処理の研究は、与えられた文章の構造を解析することを通して意味を理解する形態素解析を中心に発展してきました(下のAINOW記事を参照)。

ところが最近では、形態素解析による意味の理解をふまえたうえで、与えられた文章に対して適切な文章を返す「言葉のやりとり」の実現に研究開発の焦点が移ってきています。
こうした最近の研究動向は、「任意の入力文字列に対して適切な出力文字列が何であるか予測する」という問題設定のもとで進められています。新たに設定された問題を解くためには、入力と出力のあいだにある関係を理解し、その関係にもとづいて未知の入力に対して適切な出力を予測する必要があります。幸いなことに、この要求に応えるのにうってつけの技術がありました。それが、AI技術のひとつである教師あり学習です。
教師あり学習とは、教師データを学習する機械学習の手法で画像認識などに応用されています。AIにイヌについて画像認識させたい場合には、大量のイヌの画像を学習データとして与えることによって、AIにイヌの特徴を学習させます。イヌの特徴を学習したAIに対して未知のイヌが写っている画像を与えると、AIは画像のなかにイヌの特徴を見出すことを通して「イヌ」の画像だと認識します。
自然言語処理においても、画像認識と本質的には同じようなプロセスが実行されています。例えば機械翻訳では、対訳事例集に相当するコーパスと呼ばれるものから翻訳における言語間の関係を学習します。そして、未知の文章を与えられた時には学習済みの言語間の関係にもとづいて、適切な翻訳を予測して出力します。質疑応答や自然言語推論をAIに学習させたい場合には、コーパスの代わりに質疑応答や推論に関する学習データを与えればよいのです。
自然言語処理における予測技術は、さらに文章の生成にも応用されます。予測技術を応用して文章を生成するには、予測した文字列を再び入力文字列としてAIに与えることによって可能となります。つまり、再帰的に出力文字列の予測を繰り返せば文章を生成することになる、というわけなのです。汎用人工知能の実現を目指す非営利団体OpenAIは、こうした自己回帰(autoregressive)モデルを採用した言語AI「GPT-2」を開発しました。このAIは、ファンタジー小説の一節を入力文字列として与えるとその一節に続くようなファンタジー小説風の文章を出力することに成功して大きな話題となりました(下の画像参照)。

GPT-2が生成したテキスト。画像上部の段落がヒトが与えたファンタジー小説の一節
画像出典:OpenAIブログ「Better Language Models and Their Implications」
以上のような自然言語処理研究の歩みは、ヒトが言語能力を習得する過程に似ているのではないでしょうか。子供が単語を覚え、聞いた文章を理解する過程は形態素解析に相当し、言われたことに対して返答できるようになる過程は出力文字列の予測、自分の考えを文章で構成する「書き方」を習得する過程は文章の生成にそれぞれ相当していると言えます。
英語圏における標準ベンチマーク「GLUE」
出力文字列の予測に焦点が移った現在の自然言語処理研究において、研究目標として掲げられるのが予測精度の向上です。予測精度を研究目標として掲げるためには、客観的な予測精度の測定方法が必要となります。客観的な予測精度は、研究者であれば誰でも利用できる測定用のテストセットを用意することによって測定可能となります。こうしたテストセットとして、英語圏ではGLUE(General Language Understanding Evaluation:一般言語理解評価)ベンチマークが整備されています。
GLUEは同義言い換え、推論、質疑応答といった言語活動に関するテストデータが含まれており、こうした多数のテストデータを使って総合的な言語能力に関するスコアを算出します。GLUEスコアは英語圏の自然言語処理における言わばデファクトスタンダードとなっており、新しい言語AIに関する学術論文を発表する時には論文にGLUEスコアを掲載することが慣わしとなっています。また、GLUEベンチマーク公式サイトにはGLUEスコアの高い言語AIをランキングしたリーダーズボードが公開されています(下の画像参照)。2019年5月時点でトップなのは、クラウドソーシングして集めたヒトを被験者として算出したスコアです。しかし、おそらく近い将来、ヒトのスコアを超える言語AIが現れることでしょう(画像認識の精度を競うイメージネット画像認識コンテストでは2015年にヒトの誤認率を下回りました)。
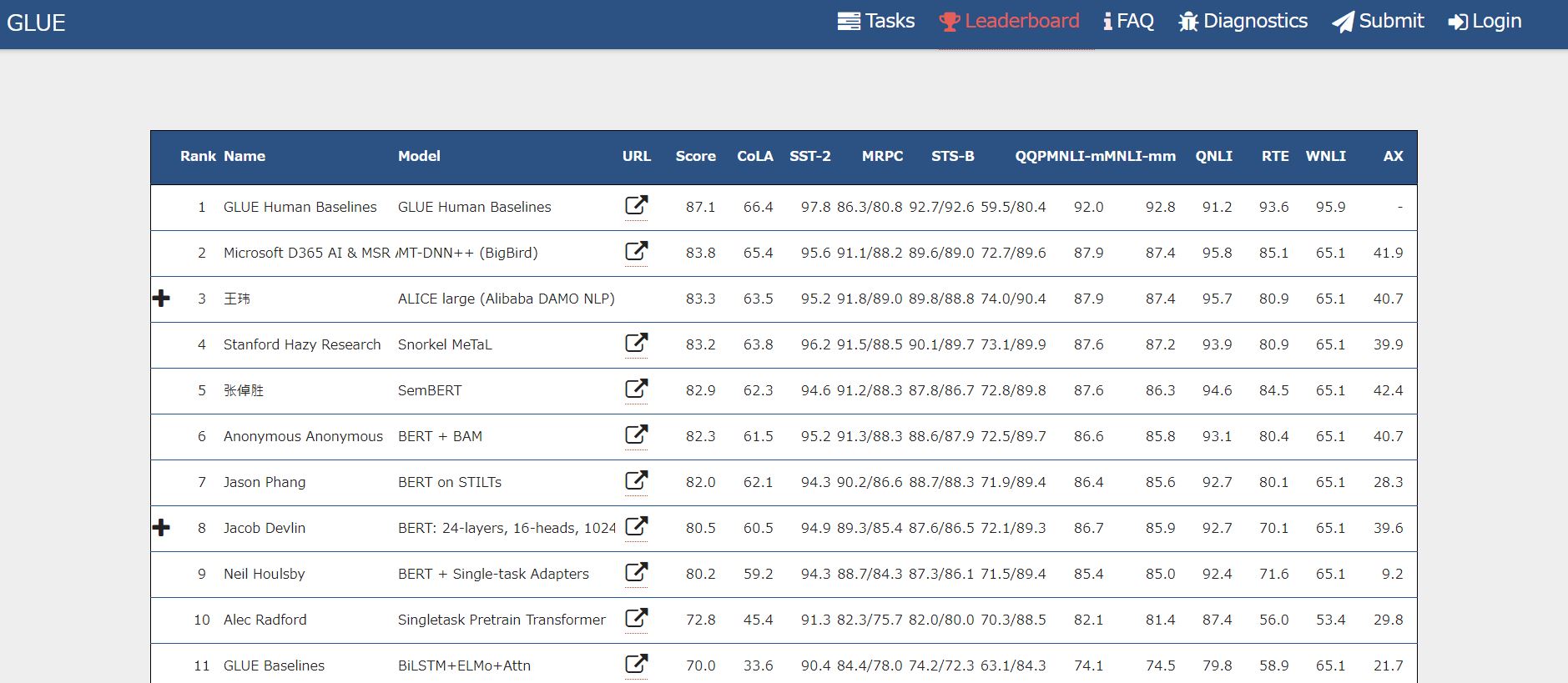
GLUEベンチマークのリーダーズボード画面
画像出典:GLUE benchmark 「Leadersboard」
| モデル名 | 開発者 | 論文提出日 | GLUEスコア | 概要 |
|---|---|---|---|---|
| RoBERTa | Facebook AI | 2019/7/26 | 88.5 | FacebookのAI研究所のチームが開発した言語AI。BERTをベースにして、ハイパーパラメータと学習データを改良した。 |
| XLNet-Laege(ensamble) | XLNet Team | 2019/6/19 | 88.4 | 一般化された自己回帰的事前トレーニング法(eneralized autoregressive pretraining method)という手法を採用したことによって、BERTを凌駕した言語AI。 |
| MT-DNN-ensamble | Microsoft D365 AI &MSR AI | 2019/5/30 | 87.6 | MicrosoftのAI研究チームが開発した言語AI。正則化を有効活用したことによってBERTを凌駕した。 |
| GLUE Human Baseline | GLUE Human Baseline | – | 87.1 | クラウドソーシングによって集計されたヒトのGLUEスコア |
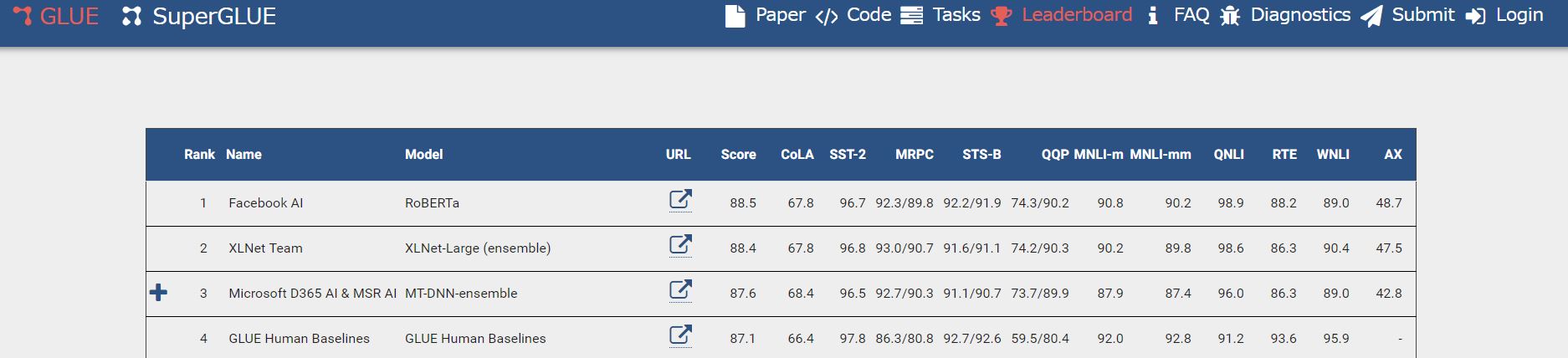 2019年7月末時点のGLUEベンチマークのリーダーズボード画面
2019年7月末時点のGLUEベンチマークのリーダーズボード画面画像出典:GLUE benchmark 「Leadersboard」[/caption]
以下の表では、GLUEベンチマークに含まれているテストデータの一部を示します。
| テスト名 | 概要 | テストセット数 |
|---|---|---|
| The Corpus of Linguistic Acceptability(CoLA) | ニューヨーク大学が作成したテスト対象の文が文法的に正しく、なおかつ常識的にみて有意味な文であるかどうか文の許容性を判定するテスト。 | 10657 |
| The Stanford Sentiment Treebank(SST) | スタンフォード大学が作成したセンチメント分析のテストセット。従来のセンチメント分析のテストセットでは、文中にある数語の単語だけにもとづいてポジティブかネガティブかを判断していた。対して、SSTでは文脈を考慮して文の感情的価値を計測してうえで、各文に感情を意味するラベルを付与している。テストでは、与えられた文に付与された感情ラベルが予測される。 | 215154 |
| Microsoft Research Paraphrase Corpus(MRPC) | Microsoftが作成した同義語に関するテストセット。ふたつの文が一組となったデータから構成されており、一方が他方の同義的な言い換えかどうかを予測する | 5800 |
| Semantic Textual Similarity Benchmark(STS-B) | 英語のニュース記事から作成されたデータセット。任意のふたつの文を選び出して、内容的に類似しているかどうかを予測する。 | 8628 |
| Quora Question Pairs(QQP) | Q&AサイトのQuoraの質問にもとづいて作成されたテストセット。ふたつの質問文のペアから構成されており、ふたつの文が意味的に同じかどうかを予測する | 400000 |
| MultiNLI (MNLI) | ニューヨーク大学が作成した自然言語推論に関するテストセット。テストデータはふたつの文から構成されており、これらの文の論理的関係に応じて「矛盾」「中立」「含意」のラベルが付与されている。テストでは、入力として与えられたテストデータのラベルが予測される。以上のテストセットは、ふたつの文が同じ引用元から採取されたmatchedと引用元が異なるmismatchedというサブクラスがある。 | 433000 |
| Question NLI(QNLI) | スタンフォード大学が作成した質疑応答能力を測定するテストセット。テストデータは事項の定義、事項に対する質問、その質問に対する答えから構成されている。テストでは言語AIに質問し、正しい回答を返すかどうかを評価する。 | 100000 |
| Winograd NLI(WNLI) | 1語あるいは2語が異なるだけで意味が大きく異なる文はウィノグラード・スキーマを有している、と言われる。テストではウィノグラード文を提示して、言語AIに文の意味に関する選択問題を解かせる。テストセットに収録されたウィノグラード文の日本語訳もある。 | 150 |
日本におけるテストセット
日本語の自然言語処理の研究開発においては、GLUEベンチマークに相当するものはまだないようです。しかし、研究開発に有効活用できるテストデータは多数公開されています。以下の表では、そうした日本語の自然言語処理に関するテストデータを紹介します。日本のテストセットは、形態素解析の研究のために用意されたものが多いという傾向が認められます。
| テストセット名 | 概要 | テストデータ数 |
|---|---|---|
| 京都大学テキストコーパス | 毎日新聞の1995年1月1日から17日までの記事から抽出した約2万文、および同年1月から12月までの社説記事から抽出した約2万分、合計して約4万文に対して人手で形態素・構文情報を付与したテストセット。形態素解析にはJUMANとKNPを使い、その結果を人手で修正している。 | 40000 |
| 京都大学ウェブ文書リードコーパス | ウェブ上で公開されている日本語のニュース記事、百科事典記事、ブログといった様々なジャンルのウェブ記事のリード(冒頭の導入部分)3文に対して、人手で言語情報を付与したテストセット。形態素解析にはJUMANとKNPを使い、その結果を専門家が修正している。 | 5000 |
| 青空文庫 形態素解析データ集 | 青空文庫に収録されている著作に文に対して、textsearch_jaで形態素解析を実行した結果を表にまとめたテストセット。 | 11176 |
| Twitter日本語評判分析データセット | 奈良先端科学技術大学でビックデータに関して研究している鈴木優准教授が公開しているテストセット。携帯電話等に関してつぶやいている2015年から2016年ごろのツイートに対して、人手で感情ラベルを付与している。 | 534962 |
自然言語処理の市場予測
以上のように進化している自然言語処理のビジネス活用は、画像認識のそれのように大きな成長が見込まれています。調査会社Market Research Futureが2019年1月に発表したレポートによると、世界の自然言語処理ビジネス市場は2017年より年平均成長率24%で成長し、2023年には約250億ドル(約2兆8,000億円)規模になると予想されています(下のグラフ参照)。また、自然言語処理の普及が進む業界には小売、医療、法務が挙げられています。
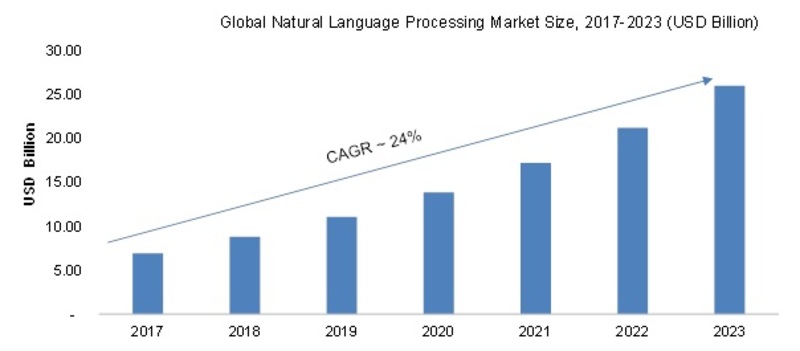
2017年から2023年までの世界の自然言語処理市場の成長予測
画像出典:Market Research Future「Natural Language Processing (NLP) Market Research Report- Global Forecast to 2023」
同市場の成長率を地域別に見た報告もあります。調査会社Mordor Intelligenceが発表したレポートによると、同市場を地域別に見ると現在は北米市場が大きいものも、今後は日本と中国を含むアジア地域が著しく成長し大きな市場となるだろう、と予想されています(下のグラフ参照)。アジア地域の成長は、英語以外の言語における自然言語処理の研究開発が大きく発展するであろうことも含意しています。
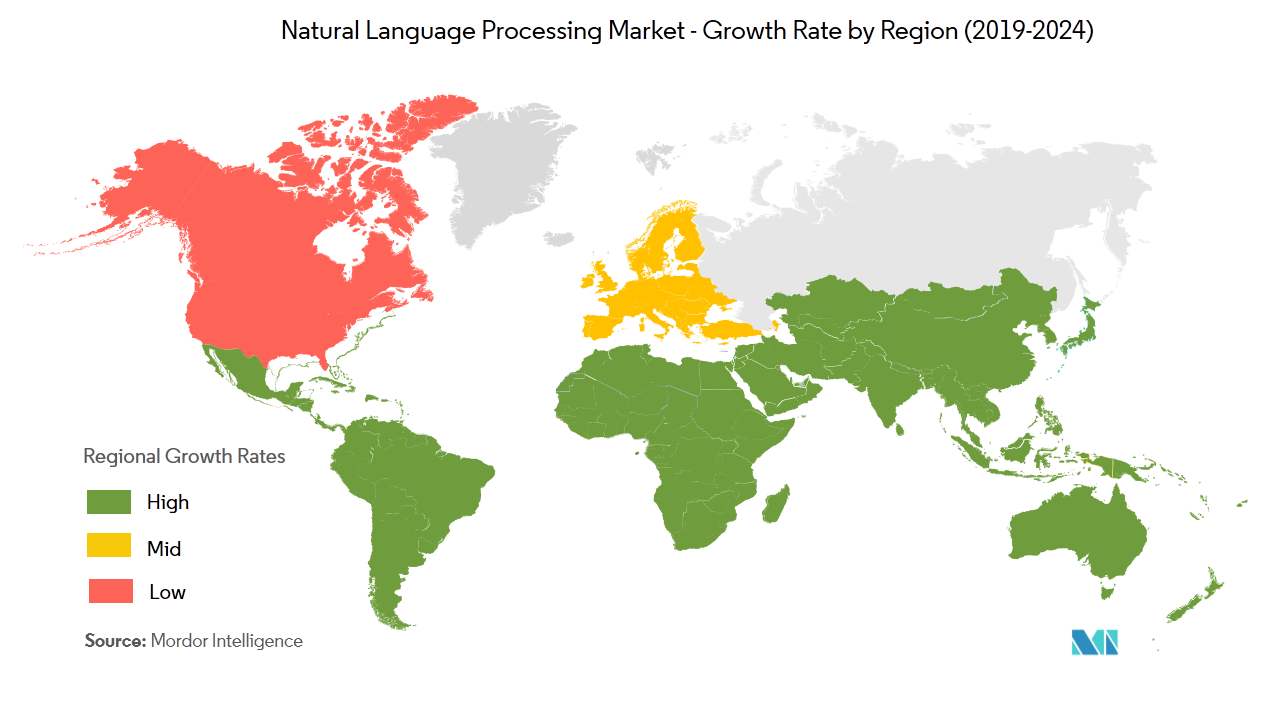
2019年から2024年の地域別に見た自然言語処理市場の成長予測
画像出典:Mordor Intelligence「NATURAL LANGUAGE PROCESSING MARKET – GROWTH, TRENDS, AND FORECAST (2019 – 2024)」
自然言語処理の活用事例
以下では、自然言語処理研究の最新の成果を生かした具体的なビジネス活用事例を小売、医療、法務の業界ごとに確認していきます。
なお、以下の事例では文書の分類を行うタスクがしばしば登場します。分類と出力文字列の予測は、直観的には結びつかないように感じられます。しかし、文書の分類においては「特定の特徴をもった入力文字列に対して学習したルールにもとづいた分類ラベルを予測し、そのラベルを付与する」というタスクが処理されているので、予測と同様に教師あり学習による処理の一種と見なすことができます。
小売
小売業における自然言語処理のビジネス活用は、チャットボットの導入によって急速に進んでいます。こうしたチャットボットは、カスタマーサポートにおける自動応答を担当することが多いようです。チャットボットのほかには、以下のような事例があります。
TwentyBn「millie」
ドイツに本社をおくAIスタートアップTwentyBnが開発・提供する「millie」は画像認識、音声認識、そしてVR技術が複合したバーチャル・アシスタントです。同製品の特徴を簡単に表現するならば、「ディスプレイにヒトとして表示されたチャットボット」です。言葉で説明するよりも同社が公開している動画を見れば、同製品を即座に理解できるでしょう(以下の動画を参照)。
同製品は1,000以上のジェスチャーに反応し、120以上の言語に対応しています。搭載されているカメラは、監視カメラとして活用することも可能です。また、導入する企業のニーズに合わせてジェスチャーや言語コミュニケーションのカスタマイズ学習もできます。
Wonderflowの「The Wonderboard」
イタリア人の起業家たちが創業したAIスタートアップWonderflowが開発・提供する「The Wonderboard」は、自然言語で運用可能なマーケティング支援ツールです。同ツールは自動的に製品やサービスに関するレビューをSNS等から収集し、収集したレビューに対してセンチメント分析を実行します。こうした分析から好意的なレビューにおけるキーワードや否定的なレビューを投稿したユーザの属性といった情報を取得します(下の動画参照)。
同ツールのユーザは取得されたマーケティングに関する重要な情報を自然言語で尋ねることができ、その質問に対する回答も自然言語で返ってきます。こうした挙動の背後には、文章生成技術が動作していることが推測されます。
医療
自然言語処理の医療への応用に関しては、大手調査会社のマッキンゼーがブログ記事を公開しています。その記事によると、自然言語処理の医療への応用は医療データの整理・管理と診断の支援の2種類に大別されます。この2種類の応用は、言わば表裏一体の関係をなしています。医療機関が抱える大量の医療データを病名やキーワードで整理することによって疾病と症状のあいだにある関係が明らかになり、その明らかになった関係を参考にすれば、より高品質な診断ができるようになるのです。以下では、具体的に事例を紹介します。
Amazon Comprehend Medical
オンラインショッピング最大手Amazonが提供するAmazon Comprehendは、ユーザが書き込んだ製品レビューのようなテキスト文書を分析するツールです(下の動画参照)。同ツールを使えばキーワードや地名を抽出したうえでそれらの単語間の関係を分析したり、さらにはテキスト文書の内容が肯定的か否定的かを判定するセンチメント分析も実行できます。
Amazon Comprehend Medicalは、上記のような基本的な分析機能に医療情報を分析する機能を追加したツールです。あらかじめ学習した生体組織、疾病名、薬名といった医療用語にもとづいて問診票のような医療データを整理・分類することができます。整理・分類を行えば例えばある薬の効果について過去のデータを参照したい時に、投薬量や投薬頻度といった属性にもとづいて整理することが可能となります。
Health Fidelityの医療ソリューション
アメリカのスタートアップHealth Fidelityは、自然言語処理を活用した医療ソリューションを提供しています。同社のソリューションを使えば、医療データから国際的な疾病分類法であるICD-10と関連する記述が自動抽出されます。抽出された記述は、医療関係者の意思決定に役立てることができます。同社は、2012年にアメリカ・コロンビア大学と技術提携を締結しました。
法務
膨大なテキスト文書を扱う法務は、自然言語処理を導入することによって効率化される業務として期待されています。大手調査会社トムソン・ロイターは、アメリカにおける207の企業の法務部門に対して、法務にAIを導入することに関する意識調査を行いました。「企業法務部門の業務において、AI活用が主流になるのはいつ頃か」と質問したところ、「2~3年以内」は3%だったのに対し、「5年以内」は21%、「10年以内」という回答は39%にのぼりました。
また、「企業法務部門にAIを導入することによって得られる効果は何か」という質問に対しては、「時間の効率化/節約」が17%、「コストの削減」が13%、「支出やリスクの予測」が7%、「資料の整理と要約」が6%でした。また、法務部門の規模が大きくなるほどAI導入による時間の効率化/節約の効果が大きいと考えていることもわかりました(下の表参照)。以上の調査から法務部門のAI導入に対する意識の高さがうかがえます。
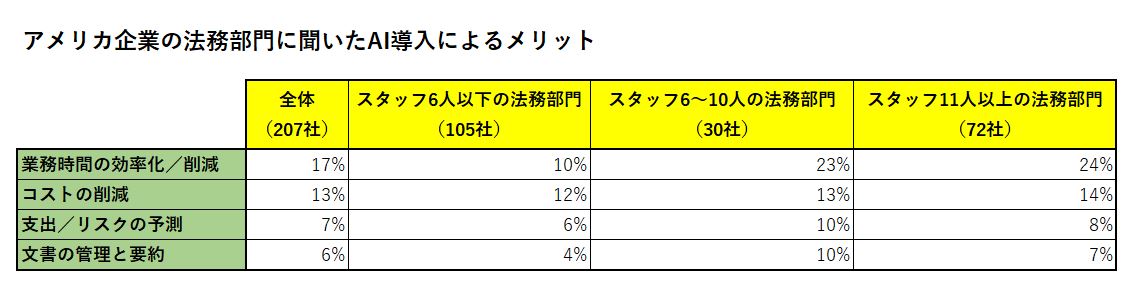
データの出典:Thomson Reuters「Ready or not: artificial intelligence and corporate legal departments」
以下では、法務に導入することが想定されているビジネス事例を紹介します。
LawGeexの契約書レビューツール
ニューヨークとイスラエルのテルアビブに拠点を置くLawGeexは、法務契約書の内容を自動的にチェックするツールを開発・提供しています。同ツールを使えば、契約書に記載されるべき条項が自動的にチェックされます。問題がなければ契約書は承認されますが、条項の欠如や不適合が検出された場合は検出箇所にフラグが立てられます(下の動画参照)。ちなみに同ツールが実行する「欠如や不適合」の検出は、「欠如」や「不適合」といった特殊なクラスに文書を分類するタスクと見なせます。
同ツールは、権威あるビジネス誌Fortuneが毎年選出するFortune 500に選ばれるような大手企業にも導入され、契約書レビューに要する時間とコストの削減に寄与しています。
Eigen Technologiesの文書マイニング
2014年に創業して現在ではニューヨークとロンドンに拠点を置くEigen Technologiesは、文書マイニングツールを開発・提供しています。企業が蓄積している大量の文書を同ツールに読み込ませれば、文書の特徴を学習した後にその特徴にもとづいて文書を分類します。法務契約書を読み込ませられるのはもちろんのこと、金融関係の書類にも対応しています。
ちなみに、同社はCB Insightが選出するAI 100に選ばれています。
未来に向けた課題
自然言語処理は今後ますます予測精度が向上し、実行できる言語活動も広がっていくことでしょう。その一方で、新たに生じる問題も指摘できます。以下では、自然言語処理がさらに進化して普及していくうえで解決すべき課題を4つ挙げます。
学習データとテストセットの整備
自然言語処理を実行する言語AIを開発するためには、各言語に対応した大規模な学習データが不可欠です。こうした学習データは、企業やプロジェクトごとに個別に用意するのではなく、共通したものを用意して活用するほうが効率的です。また、日本語の自然言語処理研究に限定して言えば、GLUEベンチマークのような業界標準となるテストセットの整備も必要でしょう。
学習データやテストセットを整備するにあたっては、現実にヒトが使っている言語に内在している偏見は除去すべきです。学習データやテストセットに偏見が残存していると、言語AIが偏見を増幅することにつながってしまうからです。
偏見の除去に関しては、Googleが有害な言語表現を検出するAPI「Perspective」を開発しており、さらにはLGBTIQ+コミュニティから性的少数者に関する表現を集めるプロジェクト「Project Respect(尊敬プロジェクト)」も展開しています。
ヒトの認知能力を考慮したAIの開発
言語AIが現在よりさらに進化すると、ヒトの相談相手となって意思決定を支援するAIアドバイザーが出現することが予想されています(こうしたAIアドバイザーは、映画『アイアンマン』に登場するAI「ジャーヴィス」のようなものと考えられます)。AIアドバイザーの開発にあたっては、ヒトは言葉遣いや会話の文脈によっては異なった判断をくだすという事実を顧慮すべきです。ヒトの意思決定プロセスを考慮せずにAIアドバイザーを開発した場合、AIがヒトの意に反する判断に誘導してしまうことが起こり得ます。
OpenAIは、すでに必ずしも合理的ではないヒトの意思決定プロセスを考慮した会話AIに関する研究に着手しており、公式ブログ記事でその研究方針を報告しています(下のAINOW記事参照)。

悪用に対する対策
言語AIが進化すると、AIが作成した文章がヒトの作成した文章と見分けがつかなくなると考えられます。こうした高度な言語AIを悪用すればフェイクニュースを自動的に大量に作成して世論を操作したり、ヒトになりすましてツイートするような「なりすましAI」を開発することが可能となります。将来起こるであろう言語AIの悪用に対して、何らかの対抗策を用意しておくべきです。
言語AIが悪用される可能性は、日増しに高まっていると言えます。言語AIの悪用を懸念した事例には、前述した「GPT-2」の発表をめぐる顛末があります。GPT-2は15億のパラメータをもち、800万にものぼるWebページを使って学習したという空前の規模をほこり、文章生成能力において画期的とも言える成果を出しました。にもかかわらず、OpenAIは自然言語処理研究の慣習に反してGPT-2のソースコードを公開していません(代わりに規模のより小さい言語AIを公開しました)。こうした措置をとったのは、GPT-2の悪用を恐れたからでした。
マルチモーダルな言語活動への対応
現在の自然言語処理の研究開発は、テキスト(書き言葉)で表現された言語表現を主な対象としています。ヒトの言語活動は、テキストだけではなく音声(話し言葉)も用いています。音声的な言語活動を理解するにあたっては、発語された文章の意味だけではなく発語に伴う表情やジェスチャーが重要になってきます。例えば「バカ」と発語することは、発語される状況や声のトーンによっては全く異なった意味を持ちます。
今後の自然言語処理の研究開発は、話し言葉に見られるようなヒトの表情やジェスチャーを伴うマルチモーダルな言語活動の理解と応答にも対応することが望ましいでしょう。こうしたマルチモーダルな自然言語処理の研究成果は、接客業や家庭に導入されるロボットに応用されることが期待されます。というのも、接客現場でともに働き家庭でいっしょに暮らすロボットにはヒトの「気持ちを汲む」ことや「空気を読む」ことが要求されるからです。そして、こうした「他人を尊重する」あるいは「ヒトをもてなす」ことに長けている日本は、この研究分野に関して大きなアドバンテージを有していると見ることができます。
・・・
自然言語処理は文章の意味を理解する形態素解析に始まり、質疑応答や推論、さらには文章の生成を実現することを通して実行可能なタスクの範囲を広げています。進化しつつある自然言語処理は、ヒトと共に暮らし働くAIとロボットの実現には必要不可欠な技術であると言って間違いないでしょう。とりわけ労働人口の減少が始まっている日本においては、自然言語処理の研究と社会実装は国力を左右する重要な課題ではないでしょうか。
記事執筆
吉本幸記(フリーライター、JDLA Deep Learning for GENERAL 2019 #1取得)
編集
おざけん



























