Google AI Languageチームが2018年10月に発表した自然言語処理のモデル「BERT」は、質疑応答や自然言語推論といったさまざまな自然言語処理のタスクにおいて先行する言語モデルを凌駕する性能を実現しました。
国内では、2019年2月にチャットボットシステムを展開する株式会社サイシードが、「BERT」を文章の類似度を算出するためのキーワード抽出を自動で行う『sAI FAQ Builder』のサービスをリリースした他、株式会社ABEJAが2019年5月に「BERT」を活用したコンタクトセンター向けの新サービス「ABEJA Insight for Contact Center」をリリースするなど、徐々に活用が進んでいます。
今回取材したのは、ストックマーク株式会社のCTO 有馬 幸介氏です。ストックマークは、組織の情報収集の活性化ツール「Anews」や営業活動をAIを活用して効率化する「Asales」など、自然言語処理を活用したサービスを多く手がけてきました。
そして、ストックマークが新たにリリースした経営戦略の判断にAIを活用する新サービス「Astrategy」は、収集した情報を「BERT」などの自然言語処理技術を活用して分類し、競合の情報や業界動向を日々まとめ、意思決定をサポートするツールです。
今回は有馬氏のインタビューを通して、「BERT(自然言語処理技術)」の実態や事業への正しい活用方法をお伝えします。
目次 [非表示]
自然言語処理技術の簡単な変遷を教えてください
まずは、簡単に自然言語処理技術の簡単な変遷を振り返りましょう。
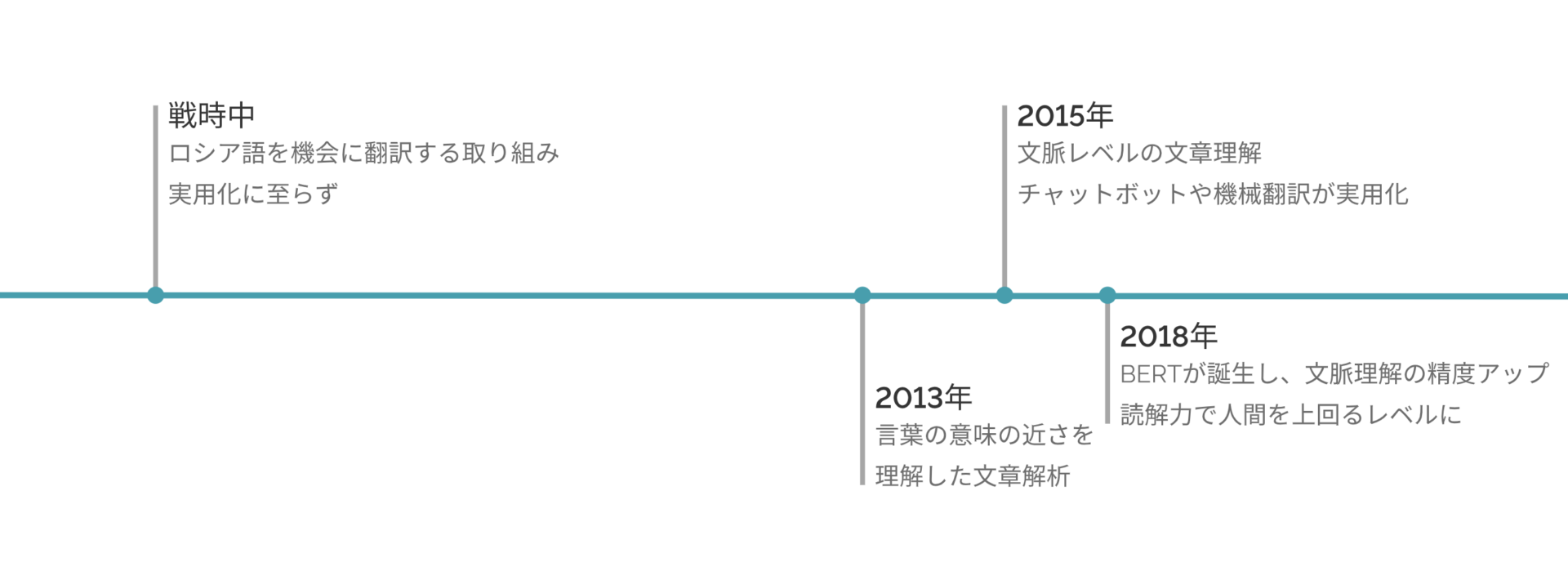
有馬氏:自然言語処理技術は古くは戦時中から、アメリカがロシアを諜報する目的で、ロシア語を機械に翻訳する取り組みなどが行われていましたが、ほとんどが実用レベルに至ることはありませんでした。
2013年頃にようやく、言葉の意味の近さを理解した文章解析ができるようになり、自然言語処理技術を活用した実用レベルのアプリを安価に制作できるようになりました。それまでは、例えば「AI」と「人工知能」のように同じ意味でも、全く意味の異なる単語として処理されてるレベルの理解にしか及んでいなかったんです。
2015年頃に、言葉の意味から更に、文脈レベルでの文章理解が実用レベルで発展したために、チャットボットや機械翻訳などが実用化され始めました、
そして2018年に、BERTなどが誕生したことで文脈を理解する精度がさらに高まり、読解力で人間を上回るレベルになり、ホワイトカラーの業務の一定程度を代替できるレベルまでになりました。
自然言語処理技術は、古くから研究開発されていたものの、なかなか実現にはいたりませんでした。多くの企業が研究開発にあたっていますが、ここまでの処理能力を得たのはここ数年のことです。
そんな自然言語処理技術のレベルについて、最新のモデル「BERT」でも、純粋な精度では人間のほうが平均的に上だと有馬氏は指摘します。
有馬氏:BERTは確かに、これまでの機械学習技術よりも確かにかなり精度が高いことが特長です。実用上もかなり精度が高いケースが多々あります。
実際、ストックマークが運営する企業に向けたニュース配信サービス「Anews」で使われている記事をジャンルごとに分類するタスクについては、5年前主流だった手法と比較しても正答率が75%から92%になり、20%近くもの向上が見られました。
しかしながら、 純粋に精度だけの観点からの話をすると、まだ本気の人間の方が平均的には上です。
囲碁などではAIが人間を上回る結果をマークしているケースもありますが、人が本気でやったら人間が精度の点ではまだ上というのがBERTを実適用をして見た素直な結果です。

「BERT」は一長一短
「BERT」は汎用言語生成モデルとも呼ばれ、汎用的にさまざまなタスクに対応できることが強みです。生成にも強みを持つことから、会話AIへの実装の可能性も広がっています。
実際にサービスに「BERT」を取り込んだ有馬氏にメリット・デメリットを伺いました。
有馬氏:BERTはこれまでのAIと同様、あるいはこれまで以上に「常識」という名のバイアスがありません。そのため、実問題に適用した時に「いや、それはありえないだろ!」というようなアウトプットを出してくることがあります。
例えば「シリコンバレーの一流エンジニアが手がける開発プロジェクトサービス」という文章を解析した時に「一流エンジニア」という言葉は企業の名詞だという結果をBERTは出しました。人間が見たらその単語は常識的にどう考えても企業ではないと判断できますが、BERTは文脈から企業と判断しました。確かに「一流エンジニア」を「Google」に置き換えても文意は通じるので、論理的には企業と判断することはできますが、実用的ではありません。
ただし、処理できる量は人間をはるかに上回ります。例えば記事の分類では人間がやった場合1記事あたり3秒程度かかりますが、AIでは0.01秒などでできるので、300倍ぐらい早いことになります。Astrategyでは1日10万記事の分類を行なっていますが、それを人間でやると83時間かかります。
AIでは30分弱でできるので、サービスの運営をするにはAIでやるしか道はありません。100%の精度が必要な処理ならば人間でやるしかありませんが、どちらを取るかはビジネス上の質を捉えた上での意思決定となるでしょう。
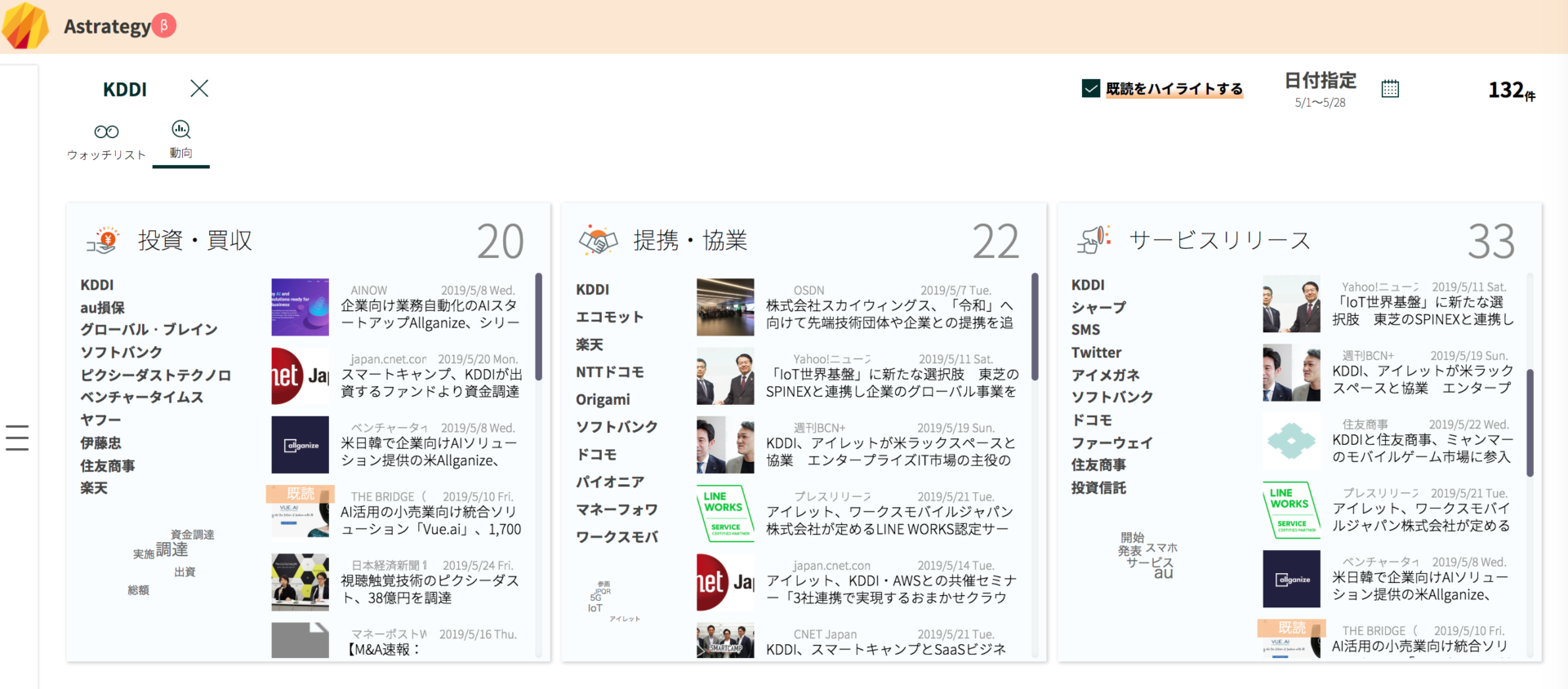
ストックマークのサービス「Astrategy」のUI |それぞれのニュースに対して、どのカテゴリの記事なのかを「BERT」を通して推定し、分類しています。
人間には限界がある処理速度。量を取るか確実な精度を取るかはサービスの特性に合わせて選択する必要がありそうです。そして有馬氏は「バイアスがない」こともメリットになると強調します。
有馬氏:BERTは「常識」という名のバイアスバイアスがないと述べました。
それはメリットでもあると考えています。バイアスがないからこそ、バイアスで選択肢を絞りがちな(特に熟練した)人間では導出できなかった観点やインサイトを導出し、それが大きいビジネスインパクトを導くこともできます。そういう意味では、「人間を超えた」ということもできると思います。

自然言語処理技術と人の関わり方、活用のコツ
近年、凄まじいスピードで発展する自然言語処理技術。これからもさらなる発展が期待されます。
では、今後自然言語処理技術とどのように関わって行けばいいのでしょうか。最後に有馬氏に自然言語処理技術との関わり方について伺いました。
有馬氏:AIに人間が「問題」だと考えている内容を教えるのは、これまでのAI技術だろうとBERTだろうと、やはり難しいです。データ化できない「問題」はAIに教えられません。
例えば、恋愛のような人間の通有性に深く根ざした問題は解決できません。あくまで、データ化できる問題しか解かせることはできないということを承知しておくことです。
バイアスがないからこそ、人間には辿り着けないインサイトを導出することができるというわけです。
問題設定を人間が行う代わりに、人間には考察しようのない洞察を、膨大な文章から得ることができる。それが自然言語処理技術との正しい付き合い方のようです。
BERTで陥りがちな「学習モデル何個作るんだよ問題」
BERTに関しても活用のコツを伺いました。
有馬氏:実行論の話になりますが、BERTを無邪気に実適用すると、学習モデル何個作るんだよ問題に直面し、大赤字を垂れ流すシステムが出来上がっています。
人間は多軸で物事を判断している。先程述べた問題で「一流エンジニア」を企業だと人間が判断しないのは、「文脈」という軸以外に、「字面」という軸で判断し「一流エンジニア」はどう考えても字面的に企業名ではないと判断できるからです。
「文脈」を学習したBERTと、「字面」を学習したBERTを両方持っているイメージですね。人間に近づき、人間を超えるためには、軸ごとのBERTが必要になり、それを組み合わせて物事を判断するようなロジックを作る必要がありますが、人間が持っているおおよそ無数にあるすべての判断軸に対してBERTを作るのは実際問題かなり難しいのではないかと思います。実運用上はかなり高コストになることが予想されます。
また、例えばストックマークが運営しているAnewsには既に数万を超えるユーザーさまにご活用いただいていますが、各ユーザーさまにBERTを使ってパーソナライズを行おうとすると、数万個のBERTモデルが必要になります。
さらにBERTのモデルは巨大であり、1つで500MBぐらい必要になるので、数テラバイトの学習モデルを日々運用/再学習していく必要があり、そこまでのROIは現状の技術では出せていません。
現状では、一世代前の、より軽量なアルゴリズムでも十分なレコメンドができており、中々コアの部分以外の全部をBERTに置き換えることに難しさはあると思います。
実務上は、BERTは組織単位で重要と判断できる課題(例えば採用の自動化など)への適用に留め、個人単位へのパーソナライズを行う場合は、一世代前の軽量のAIアルゴリズムで対応するような形となるのが2019年現在においては現実的かと思います。
ただし、BERTを用いると、準備すべき正解データ量が圧倒的に少なくて済むのは実適用上もメリットです。一世代前のAIでは数万件の学習が必要でしたが、BERTだと数百件で学習が収束し、しかも旧世代より10%も20%も高い精度を出すことができます。少ない学習データで済むので、はるかにAI適用、特にPOCの成功確率は格段と高まると思います。
今後は学習データの少ない大企業以外の企業においてもAI適用が進み、AIの民主化と共に第四次産業革命のスピードは加速するだろうと実感しております。

有馬幸介氏:東京大学大学院情報理工学系研究科修士課程卒業(2010年) 大学・大学院時代は機械学習を用いたテキストデータ解析及び分散環境における行列演算アルゴリズムの研究に従事。大学院修了後、新日鉄住金ソリューションズに入社。2000人月規模の会計業務システム開発案件等にてチームリーダーを担当し、社長賞に選出される。2016年にストックマーク株式会社を共同創業。同社にて開発したAIによるビジネスマン向け情報収集サービスは現在大手企業を中心に1000社超の導入を達成し、みずほ銀行によるMizuho Innovation Awardを受賞。
終わりに
注目される最新のモデルですが、コストを考えると、全ての領域に適用するには、まだハードルが高いことがわかりました。
技術動向と費用対効果を見極め、効果の得やすいような領域から活用していくことが大切です。
ストックマーク関連記事



自然言語処理、BERTに関する記事はこちら



■AI専門メディア AINOW編集長 ■カメラマン ■Twitterでも発信しています。@ozaken_AI ■AINOWのTwitterもぜひ! @ainow_AI ┃
AIが人間と共存していく社会を作りたい。活用の視点でAIの情報を発信します。