

※この記事は、株式会社ChillStackと三井物産セキュアディレクション株式会社の共同研究組織・セキュアAI研究所による寄稿です。
本連載は「AI*セキュリティ超入門」と題し、AIセキュリティに関する話題を幅広く・分かり易く取り上げていきます。本連載を読むことで、AIセキュリティの全体像が俯瞰できるようになるでしょう。
本コラムでは、画像分類や音声認識など、通常は人間の知能を必要とする作業を行うことができるコンピュータシステム、とりわけ機械学習を使用して作成されるシステム全般を「AI」と呼称することにします。
連載一覧
「AIセキュリティ超入門」は全8回のコラムで構成されています。
第1回:イントロダクション – AIをとりまく環境とセキュリティ –
第2回:AIを騙す攻撃 – 敵対的サンプル –
第3回:AIを乗っ取る攻撃 – 学習データ汚染 –
第4回:AIのプライバシー侵害 – メンバーシップ推論 –
第5回:AIの推論ロジックを改ざんする攻撃 – ノード注入 –
第6回:AIシステムへの侵入 – 機械学習フレームワークの悪用 –
第7回:AIの身辺調査 – AIに対するOSINT –
第8回:セキュアなAIを開発するには? – 国内外のガイドライン –
第1回〜第5回は公開済みです。
ご興味がございましたら読んでいただけると幸いです。
本コラムの概要
本コラムは第6回「AIシステムへの侵入 – 機械学習フレームワークの悪用 –」です。事前にAIモデルを細工することによって、AIが稼働するシステム上で「任意のコードを実行」する攻撃手法について取り上げます。
ここで任意のコード実行とは、アプリケーションの脆弱性を突いて攻撃者が設定した任意のプログラムコードを攻撃対象のシステム上で実行できるようにすることを指します。
AIが稼働するシステム(以下、AIシステム)上で任意のコード実行が可能になると、通常のコンピュータウイルスのようにシステム停止や情報流出、サイバー攻撃の踏み台として悪用されるなどの恐れがあり非常に危険です。
本コラムでは攻撃手法の例と対策手法について解説します。
AIシステムへの侵入
AIシステム上での任意のコード実行を可能にする攻撃手法は、他者が作成した事前学習モデルを利用するケースを狙った攻撃手法であり、本コラムでは機械学習フレームワークの仕様を悪用する手法についてご紹介します。
また、機械学習フレームワークの悪用以外にもAIシステム上での任意のコード実行を可能にする攻撃手法として、ニューラルネットワークの重みパラメータを悪用するものがあり、こちらも併せてご紹介します。
機械学習フレームワークの悪用
参考文献:Security Risks in Deep Learning Implementations
現在、scikit-learnやTensorflow, Kerasなど様々な機械学習フレームワークを用いてAIモデルを開発するケースが増えています。
また、ディープラーニングモデルは年々複雑化し、精度の向上を目指すべくデータセットも巨大化する傾向があるため学習コストが増加しています。そのため、BigMLやGradientzooなど既存の事前学習モデルを提供するサービスが注目され始め、機械学習フレームワークを用いて他者の事前学習モデルを読み込んで利用するケースが増加しています。
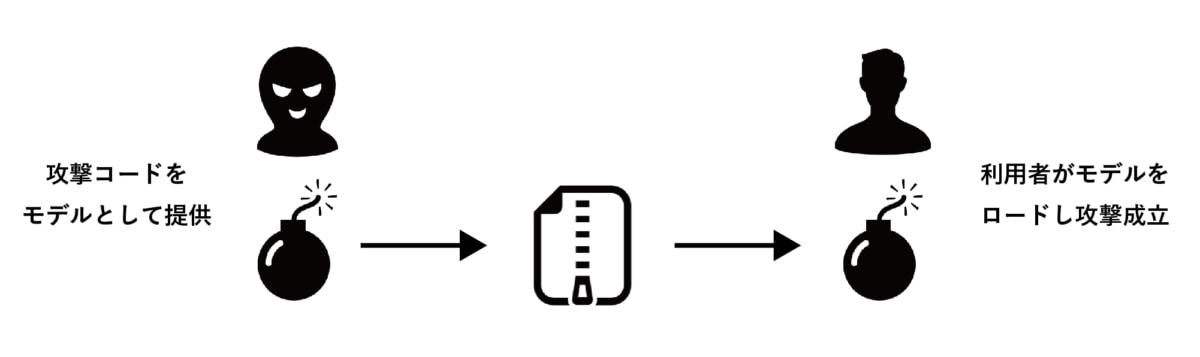
多くの機械学習フレームワークはAIモデルを開発・運用するための様々な機能を兼ね備えていますが、悪意のあるユーザーは機械学習フレームワークの機能を悪用して「悪意のある事前学習モデル」を作成することができます。そして、この悪意のある事前学習モデルを被害者のシステム上で読み込ませることで、被害者のシステム上で任意のコードを実行させることができます。
本コラムでは、代表的な機械学習フレームワークである「sickit-learn」と「Keras」における任意のコード実行の仕組みと対策について解説します。
sickit-learn
参考文献:Model persistence
scikit-learnという機械学習フレームワークでは、誰もが簡単に自身のタスクに合わせたAIモデルを作成することができます。Pythonで記述されている本ライブラリでは、「pickle」と呼ばれるライブラリと同じ仕組みを用いて、Pythonオブジェクトが含まれる中間ファイルを生成し、事前学習モデルのデータなどを共有することができます。
このPythonの任意のオブジェクトを保存できる性質には危険性が含まれています。悪意のあるユーザーは事前学習モデルのデータと偽ってPickleファイル内に攻撃コードを潜ませることができます。このファイルを読み込んだユーザーのシステムは、この攻撃コードによって被害を受ける危険性があります。
Keras
参考文献:
Keras Lambda Layer
Using TensorFlow Securely
ディープラーニングのフレームワークとして有名なKerasでは、Lambda Layerと呼ばれる独自に定義した関数をモデルに組み込むことができる機能があります。このLambda Layerを用いて悪意のある攻撃コードをモデル内に組み込むことが可能になります。
またKerasでは、モデルをHDF5というフォーマットで保存・ロードすることができ、上述したPickleファイルと同様に、HDF5ファイルの読み込み時に任意のコード実行をしてしまう可能性があります。
対策手法
AIモデルというのはプログラムであり、通常のプログラムを実行する時と同様の注意を払わなければならないという認識を持つことが大切です。攻撃からシステムを守るためには、他のソフトウェアを扱うときと同じように利用側が注意する必要があります。
第三者によって公開されている事前学習モデルをダウンロードする際、信頼できる提供元かどうかを確かめましょう。
また、提供元の信頼性が確認できないことを承知の上で事前学習モデルを読み込む際には、サンドボックス環境を用いることで、万が一攻撃コードが実行されてしまった場合でも被害を抑えることができます。
なお、TensorFlowの公式ページでは、フレームワークを安全に使うためにユーザーへの注意喚起が行われています。上記の対策手法に加えて、依存ライブラリによって引き起こされる不具合や分散処理を行うためのTensorFlow Server周りのネットワークに関する注意点が言及されています。
https://github.com/tensorflow/tensorflow/blob/master/SECURITY.md
脆弱性情報
機械学習フレームワークに起因する攻撃に関しては、脆弱性として正式に報告されているケースも多々あります。
Common Vulnrabilities and Exposures (CVE) は、脆弱性情報を収集・公開している世界的に有名な脆弱性情報データベースであり、本コラムで紹介した機械学習フレームワークに起因する脆弱性も報告されています。
ニューラルネットワークの重みパラメータの悪用
参考文献:SIN2: Stealth infection on neural network — A low-cost agile neural Trojan attack methodology
続いて、悪意のある攻撃コードをニューラルネットワークモデルの重みに埋め込む攻撃手法をご紹介します。本攻撃手法も連載第5回に紹介した「AIの推論ロジックを改ざんする攻撃 – ノード注入 –」と同じように、第三者が作成した事前学習モデルを利用するケースを狙った攻撃手法です。
本攻撃手法は、攻撃コードをニューラルネットワークに組み込むことで完全に隠蔽し、攻撃の検知を回避できるのが最大の特徴です。

マルウェア検知器を用いて、マルウェアサンプルと同等の挙動をする攻撃コードを埋め込んだニューラルネットワークモデルをそれぞれ識別した結果 引用:SIN2: Stealth infection on neural network — A low-cost agile neural Trojan attack methodology
論文内で報告されている上記の表では、ニューラルネットワーク内に組み込まれた攻撃コードと、同様の挙動のマルウェアの検知率の比較を行っています。
ニューラルネットワーク内に組み込むことによって、本論文で用いられているマルウェア検知モデルは一切攻撃コードを検知することができなくなっていることが分かります。
攻撃概要
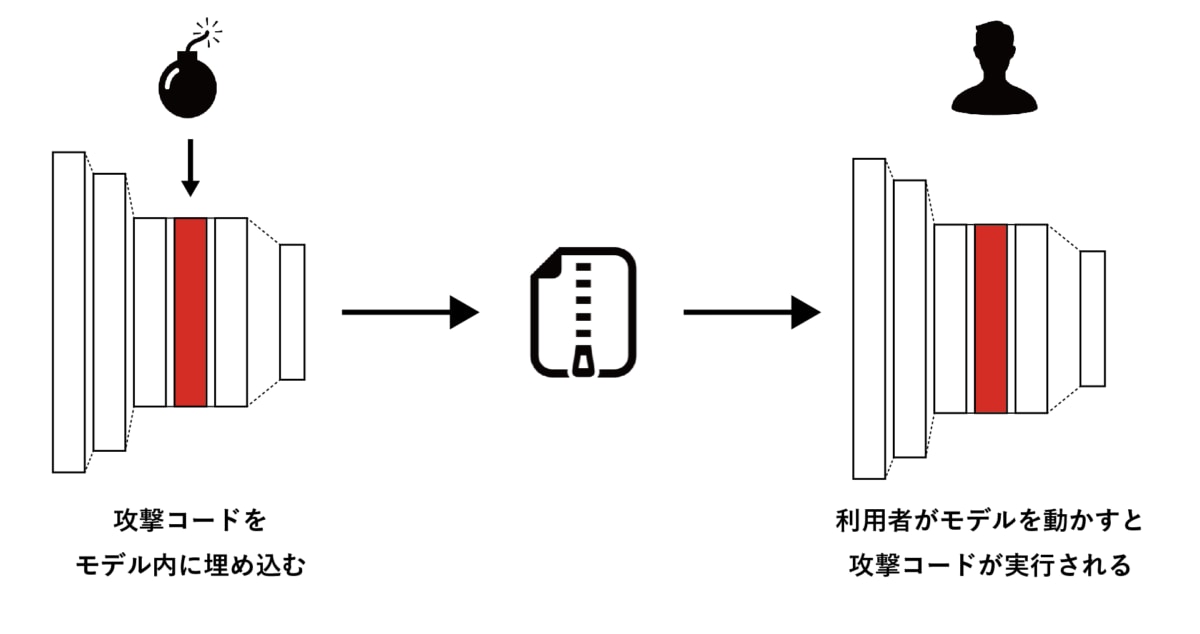
本攻撃手法では、まずニューラルネットワーク内の重みパラメータのうち、精度に影響しない程度の数ビットに攻撃コードを埋め込みます。
そして、特定のトリガー画像を入力することによって重みに埋め込んだ攻撃コードが実行される仕組みになっています。


実験環境の詳細を記した表 引用:SIN2: Stealth infection on neural network — A low-cost agile neural Trojan attack methodology
上の表は、本論文の著者らが行った実験の環境設定の詳細になります。著者らが行った実験では、48個の重みパラメータに変更を加え、Fork爆弾と呼ばれる軽量なDenial of Service攻撃 (DoS攻撃; サービスを利用不能にする攻撃手法)の実行コードを分割し、ニューラルネットワークに埋め込んでいます。
なお、上表のPayload Binaryを実行すると自身の環境が壊れてしまう可能性があるため、実行しないようご注意ください。
まとめ
本コラムでは、事前学習モデルを細工することで、AIが稼働するシステム上で任意のコードを実行する攻撃手法を紹介しました。
事前学習モデルは自身でAIモデルを学習させるコストが抑えられ、転移学習など様々な利用方法もあり便利ですが、その反面多くの危険性も孕んでいます。よって、第三者が作成した事前学習モデルを利用する際は、危険性を理解した上で利用するようにしましょう。また、万が一の被害を最小限に抑えるために、AIモデルはサンドボックス環境で実行するようにしましょう。
繰り返しになりますが、AIモデルというのはプログラムであり、通常のプログラムを実行する時と同様の注意を払わなければなりません。
本コラムは以上となります。
最後に、株式会社ChillStackと三井物産セキュアディレクション株式会社は、AIの開発・提供・利用を安全に行うための「セキュアAI開発トレーニング」を提供しています。
本トレーニングでは、本コラムで解説した攻撃手法の他、AIに対する様々な攻撃手法(データ汚染、敵対的サンプル、メンバーシップ推論など)と対策を、座学とハンズオンを通じて理解することができます。
本トレーニングの詳細やお問い合わせにつきましては、セキュアAI開発トレーニングをご覧ください。
※本コラムの執筆者は以下の通りです。
| 伊東 道明(株式会社ChillStack) 法政大学大学院卒。大学院在学中にChillStackを起業。経営やチームビルディング、ブランディングに加えエンジニアとしても活躍。異常検知を専門とし、AIセキュリティ分野の研究に従事。受賞歴にIEEE CSPA 2018にてBest paper award(深層学習技術を用いたWeb Application Firewallシステムの構築に関する論文)、セキュリティキャンプフォーラム2018最優秀賞、公益財団法人クマ財団認定クリエイター選出等。また、セキュリティ・ネクストキャンプ2019の講師やSECCON 2019のワークショップの講師を務める等、教育事業にも貢献している。 |
駒澤大学仏教学部に所属。YouTubeとK-POPにハマっています。
AIがこれから宗教とどのように関わり、仏教徒の生活に影響するのかについて興味があります。



























