

※この記事は、株式会社ChillStackと三井物産セキュアディレクション株式会社の共同研究組織・AIディフェンス研究所による寄稿です。
本連載は「AI*1セキュリティ超入門」と題し、AIセキュリティに関する話題を幅広く・分かり易く取り上げていきます。本連載を読むことで、AIセキュリティの全体像が俯瞰できるようになるでしょう。
本コラムでは、画像分類や音声認識など、通常は人間の知能を必要とする作業を行うことができるコンピュータシステム、とりわけ機械学習を使用して作成されるシステム全般を「AI」と呼称することにします。
目次
連載一覧
「AIセキュリティ超入門」は全8回のコラムで構成されています。
第1回:イントロダクション – AIをとりまく環境とセキュリティ –
第2回:AIを騙す攻撃 – 敵対的サンプル –
第3回:AIを乗っ取る攻撃 – 学習データ汚染 –
第4回:AIのプライバシー侵害 – メンバーシップ推論 –
第5回:AIの推論ロジックを改ざんする攻撃 – ノード注入 –
第6回:AIシステムへの侵入 – 機械学習フレームワークの悪用 –
第7回:AIの身辺調査 – AIに対するOSINT –
第8回:セキュアなAIを開発するには? – 国内外のガイドライン –
第1回〜第7回は公開済みです。
ご興味がございましたら読んでいただけると幸いです。
本コラムの概要
本コラムは第8回「セキュアなAIを開発するには? – 国内外のガイドライン –」です。
第1回から第7回までは、AIを取り巻くセキュリティの環境や、AIに対する具体的な攻撃手法を紹介してきました。AIを攻撃から守るためには、セキュアなAI開発が必要です。そこで、本コラムでは、筆者らがAIの安全確保に役立つと考えるガイドラインやテストツールなどを紹介していきます。
セキュアなAI開発を実現するには?
セキュアなAI開発を実現するために、何から着手すれば良いのでしょうか?その答えは会社や組織など、開発の現場によって異なりますが、本コラムでは大きく以下の3つに分けて考えていきます。
- 品質保証マネジメントを開発に組み込む
- AIに携わる全ての方々が攻撃手法と対策を理解する
- セキュリティテストを開発工程に組み込む
それでは、一つずつ見ていきましょう。
品質保証マネジメントを開発に組み込む
AIの開発に品質保証マネジメントを組み込むことで、AIの防御力向上が期待できます。
例えば、AIが過学習した場合や学習データのバリエーションが不足している場合はAIの頑健性が低下し、AIの推論精度が低下することが知られています。また、本連載コラムの「第2回:AIを騙す攻撃 – 敵対的サンプル –」や「第4回:AIのプライバシー侵害 – メンバーシップ推論 –」などで説明したように、頑健性の低いAIは敵対的サンプルやメンバーシップ推論など対して脆弱になります。
さらに、「第3回:AIを乗っ取る攻撃 – 学習データ汚染 –」で説明したように、データの偏りや汚染といった学習データ品質が低い場合、AIにバックドアが設置され、AIが思わぬ挙動を示す可能性があります。
このことから、AIの頑健性や学習データ品質の向上などの、いわばAI開発においての「当たり前」を確実に実践することで、AIに対する攻撃への耐性をある程度高めることができます。
この実践に役立つのが「品質保証ガイドライン」です。
本節では以下の3つを紹介します。
AIプロダクト品質保証ガイドライン
AIプロダクト品質保証ガイドラインは、QA4AIが発行しているAIの品質保証ガイドラインであり、AIの品質保証を以下に示す5つの軸でチェックすることを推奨しています。
- Data Integrity
- Model Robustness
- System Quality
- Process Agility
- Customer Expectation
「Data Integrity」では「データの質という点では、サンプルに対する統計的な性質を満たしているかを考慮する必要がある。求める⺟集団に属するサンプルなのかどうか、実際のデータなのか人為的に作成されたデータなのか、不必要なデータやノイズ、異なる⺟集団のデータが含まれていないか、などを考慮する必要がある。また偏りやバイアス、汚染は無いか、自分たちが考えている偏りの源だけでよいのか、などを考慮する必要もある。」と述べられており、これは前述した「学習データ汚染」への対策に通じます。
また、「Model Robustness」では「モデルの精度と頑健性、デグレードなどについて考慮する。」と述べられており、これは前述した「敵対的サンプル」や「メンバーシップ推論」への対策に通じます。
本ガイドラインには、Data IntegrityやModel Robustnessなどのセキュリティにも寄与する品質を向上させるための詳細なチェックリストが掲載されています。「脆弱性」はバグの1種(セキュリティ・バグ)とも言えるため、AIの品質を向上させて「バグを潰す」ことは脆弱性の削減にも繋がります。
AI・データの利用に関する契約ガイドライン
AI・データの利用に関する契約ガイドラインは、経済産業省が発行しているAI・データ利活用における契約ガイドラインです。
本ガイドラインには、AIを利用したプロダクトの開発・調達・利用に関する契約の基本的な考え方が解説されています。現在、AI開発を外部業者に委託することは珍しくありませんので、業者から納品されたAIが予期せぬ動作や誤動作した場合の責任の所在や、(AI開発のために)業者に渡した価値あるデータの流出や不正利用時の対応など、契約の面で注意すべき事柄がケーススタディを交えながら解説されています。
ディープラーニング開発標準契約書
https://www.jdla.org/news/20190906001/
ディープラーニング開発標準契約書は、日本ディープラーニング協会(JDLA)が発行している開発契約書の雛形です。
本雛形が公表された背景として、社会課題の解決や新たな付加価値の創出などが期待されているディープラーニング技術に注目が集まる一方で、ディープラーニング技術を活用して開発を行うスタートアップと、その業務の委託者である大企業との間で、契約実務に関する経験・スキル、ディープラーニングに関する認識・理解のギャップなどにより、契約の締結が円滑に進まないという課題があります。
そこで、JDLAはスタートアップと大企業間での契約締結の円滑化を目指し、本雛形を策定・公表しています。本雛形が活用され、スタートアップと大企業の連携が進むことで、さらなるディープラーニング技術の社会実装が促進されることが期待できます。
ここで紹介したガイドラインはセキュリティに特化したものではありませんが、AIの頑健性やデータ品質の向上は、AIに対するサイバー攻撃への耐性を高める効果があります。また、契約トラブルや不測の事態を防ぐ・備えるためには契約などの法的観点も欠かせません。
よって、これらのガイドラインをAI開発に組み込むことは、安全なAIを開発する「最初の一歩」になると言えるでしょう。
AIに携わる全ての方々が攻撃手法と対策を理解する
前述したガイドラインを有効活用するには、開発者やプロダクトマネジャーといったAIに携わる全ての方々がAIへの攻撃手法と対策を理解していることが望ましいと言えます。
例えば、開発チームの中に「学習データの収集・作成工程を狙った攻撃手法(=学習データ汚染)」への理解が醸成されていれば、学習データの収集方法や入手元に細心の注意を払うことで、学習データ汚染を防ぐことができるかもしれません。また、「AIに入力されるデータを細工することでAIの推論を誤らせる攻撃手法(=敵対的サンプル)」への理解が醸成されていれば、入力データの検証機構の必要性を認識・実装することで、敵対的サンプルによる誤分類を防ぐことができるかもしれません。
本節では、このような攻撃手法や対策の理解に役立つ情報源を5つ紹介します。
arXiv – Cryptography and Security
ご存知の方も多いかと思いますが、arXivは世界中から投稿された論文が保存・公開されているアーカイブサイトです。
このarXivの中で、筆者らがAIへの攻撃手法と対策の情報源として活用しているページが「Cryptography and Security」です。このページには、サイバーセキュリティに関する論文がほぼ毎日十数本掲載されており、攻撃検知やマルウェア検知などのセキュリティ・タスクにAIを活用した研究や、AIに対する攻撃手法と対策に関する研究論文も数多く投稿されています。
arXivは誰でも投稿できるという性質上、中には”怪しい”論文が存在することは否めませんが、世界トップクラスの大学や研究組織の論文も数多く投稿されるため、情報源としては十分に有益であると言えます。実際に、筆者らはarXivに投稿された論文を基にAIへの攻撃手法と対策を検証し、その有効性を何度も確認しています。
論文は一次情報としての性質が強いため、arXivに日々投稿される論文をチェックすることで、AIに対する最新の攻撃手法と対策を知ることができます。
AIディフェンス研究所
とは言え、arXivに投稿される論文はほぼ英語論文であり、ページ数も多いため、学術論文に慣れていない方がカジュアルに読めるものではありません。そこで、(手前味噌ではありますが…)筆者らが運営する「AIディフェンス研究所」というWebサイトでは、筆者らが「これぞ!」と思ったAIセキュリティに関する論文を噛み砕いてブログ公開しています。

AIディフェンス研究所
AIディフェンス研究所では、海外の興味深い論文・技術ブログ・ガイドラインなどを収集し、不定期でブログ公開しています。ご興味のある方は一読いただけると幸いです。
Adversarial Threat Matrix
「第7回:AIの身辺調査 – AIに対するOSINT –」でも紹介した「Adversarial Threat Matrix」は、AIへの攻撃手法を体系化したフレームワークであり、サイバーセキュリティ専門家がAIセキュリティに参加することを促す目的で作成されています。
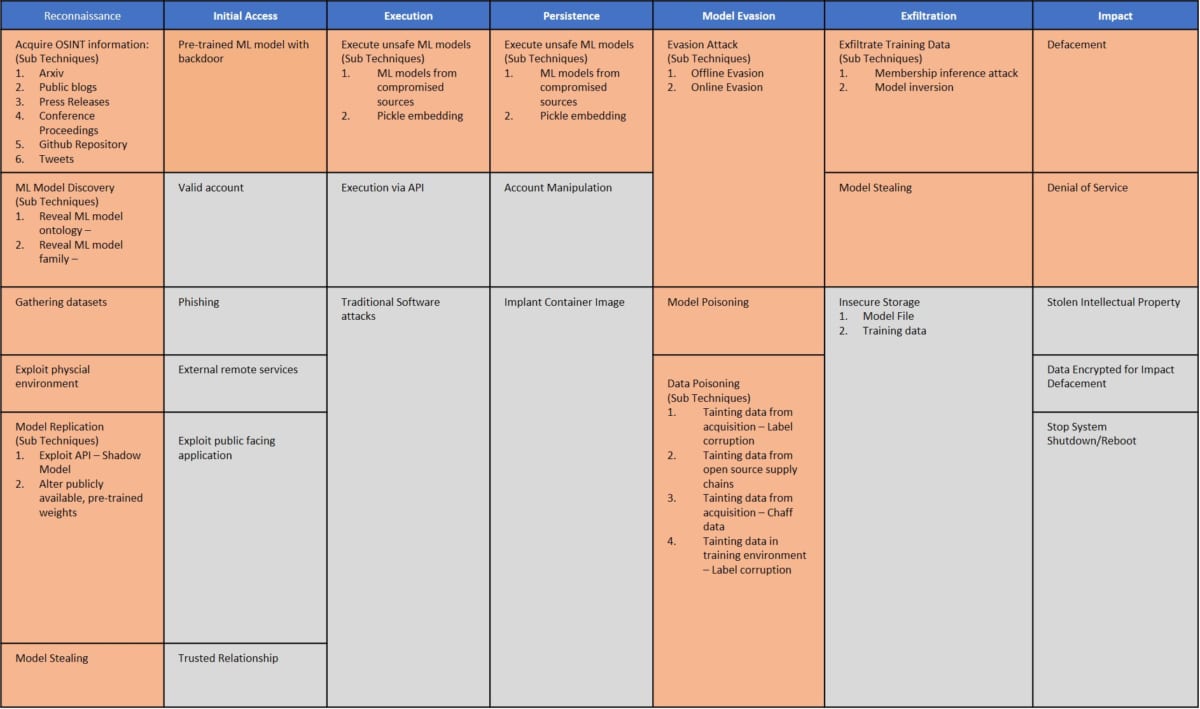
このフレームワークは、AIに対する脅威をReconnaissance(偵察)、Initial Access(初期アクセス)、Execution(攻撃の実行)、Exfiltration(データの持ち出し)、Impact(攻撃の影響)などにカテゴライズしており、カテゴリ毎に具体的な手法/技術を網羅しています。
また、実際の製品やサービスに対する攻撃検証事例が「ケーススタディ」として公開されており、どのような手順で攻撃に至ったのか、その経緯が分かりやすく纏められています。
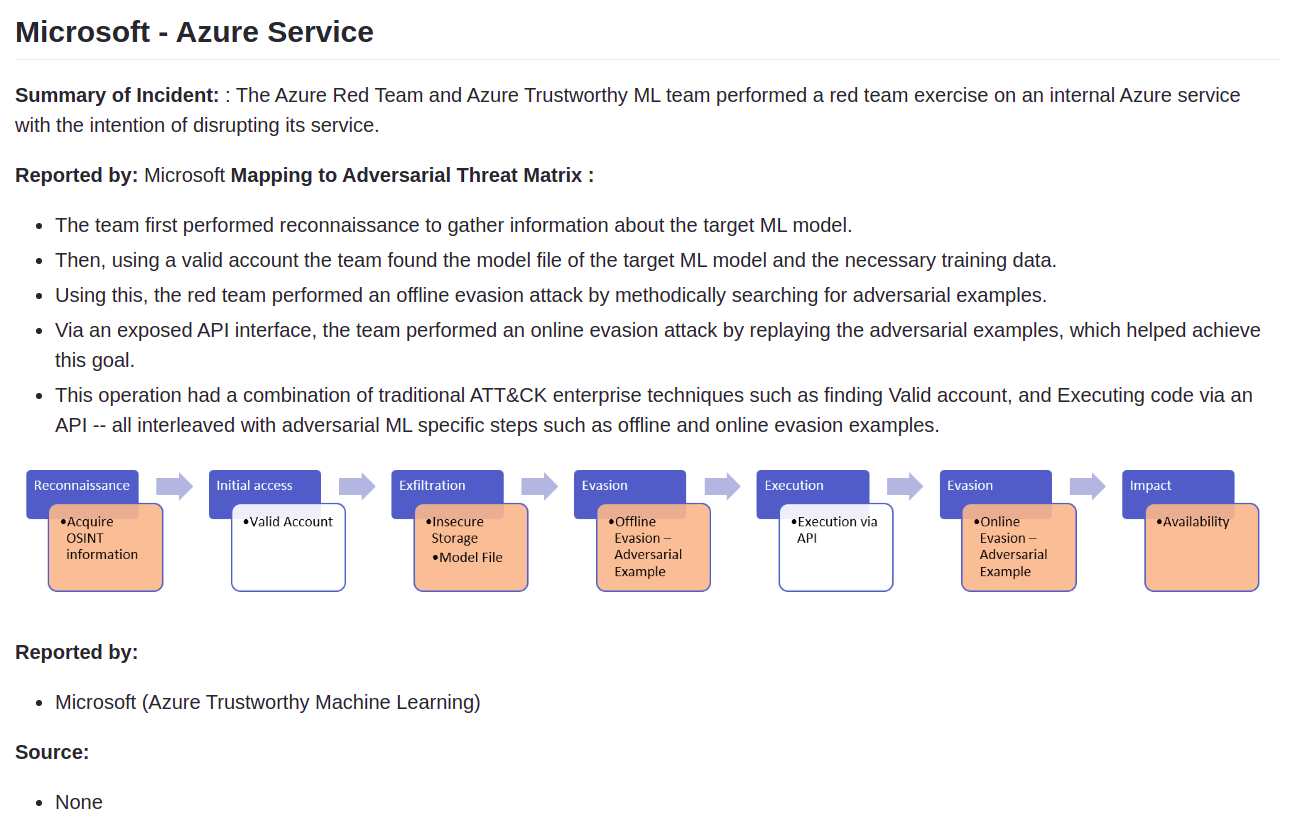
ケーススタディの一例(出典:Adversarial Threat Matrix – Case Studies Page –)
Adversarial Threat Matrixを参照することで、攻撃者目線でAIに対する攻撃手法を理解することができます。
Draft NISTIR 8269: A Taxonomy and Terminology of Adversarial Machine Learning
「Draft NISTIR 8269: A Taxonomy and Terminology of Adversarial Machine Learning」は、米国のNIST(National Institute of Standards and Technology)が策定を進めているAIセキュリティに関するベストプラクティスのドラフトです。AIの安全確保を目的として、AIにまつわるセキュリティを「攻撃」「防御」「影響」の3つの視点で分類し、また用語の定義などを行っています。
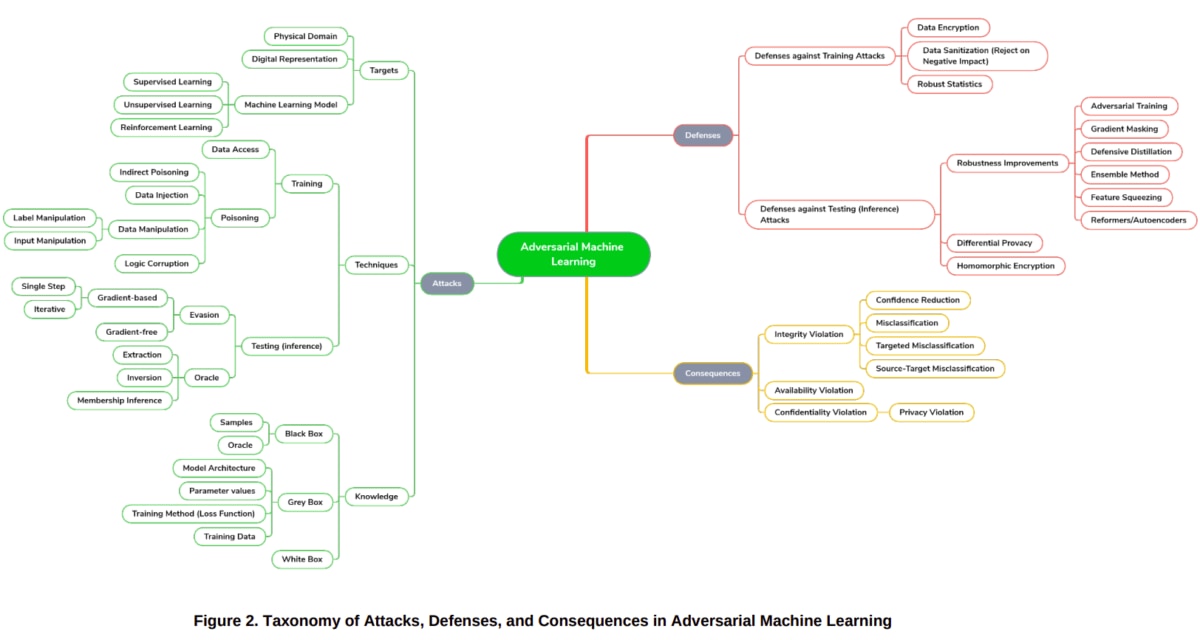
NISTIR8269は本ラコムの執筆時点(2021年2月)でドラフト版ですが、「NIST SP800-30:Guide for Conducting Risk Assessments(日本語版:リスクアセスメントの実施の手引き)」への反映を計画しているとのことです。もしかすると、今後NISTIR8269の内容がAIセキュリティのベストプラクティスになるかもしれません。
なお、AIディフェンス研究所では、本ドラフトの日本語解説ブログを公開していますので、ご興味のある方はご一読ください。
AI VILLAGE
AI VILLAGEは、AIの利活用や攻撃・防御を研究するハッカー・コミュニティです。
世界最大級のサイバーセキュリティに関するハッカー・カンファレンスである「DEFCON」のワークショップとして誕生して以来、AIセキュリティに関する様々なイベントを企画・運営しており、企業や大学の研究者(学生含む)、エンジニア、セールス、経営者など、様々な職種のメンバーが多く参加しています。
普段はDiscord上で意見交換を行っており、AIに対する攻撃手法や対策のみならず、(AIに関連する)論文や数学的な話題、AIの倫理や仕事の紹介など、幅広い話題で盛り上がっています。こちらのリンクからAI VILLAGEのDiscordにジョインできますので、ご興味のある方は是非ジョインし、他メンバーと交流してみてください。
ここで紹介した5つの情報源は、AIに対する攻撃手法と対策の理解に大いに役立ちます。
AIの開発・利用に携わる方々のセキュリティ意識の芽生えは、セキュアな設計・プログラミング・調達など、AIの安全確保に大きく貢献すると考えていますので、これらの情報源を一読することを推奨いたします。
セキュリティテストを開発工程に組み込む
ガイドラインの実践やセキュア設計・プログラミング・調達などを心がけても、脆弱性の作り込みを100%防ぐことは難しいかもしれません。そこで、AIを製品またはサービスとしてリリースする前にセキュリティテストを実施し、未然に脆弱性を検知、そして、修正することが望ましいと言えます。
セキュリティテストを経てAIをリリースすることで、AIがサイバー攻撃を受けて被害が発生する確率を低くすることが期待できます。
本節では、AIに対するセキュリティテストを支援するツールを2つ紹介します。
Adversarial Robustness Toolbox
Adversarial Robustness Toolbox(ART)は、AIセキュリティのためのPythonライブラリです。
AIの開発者はARTを使用することで、これまで本連載コラムで解説してきた攻撃手法(敵対的サンプル、データ汚染、メンバーシップ推論など)とそれらに対する防御手法を検証することができます。
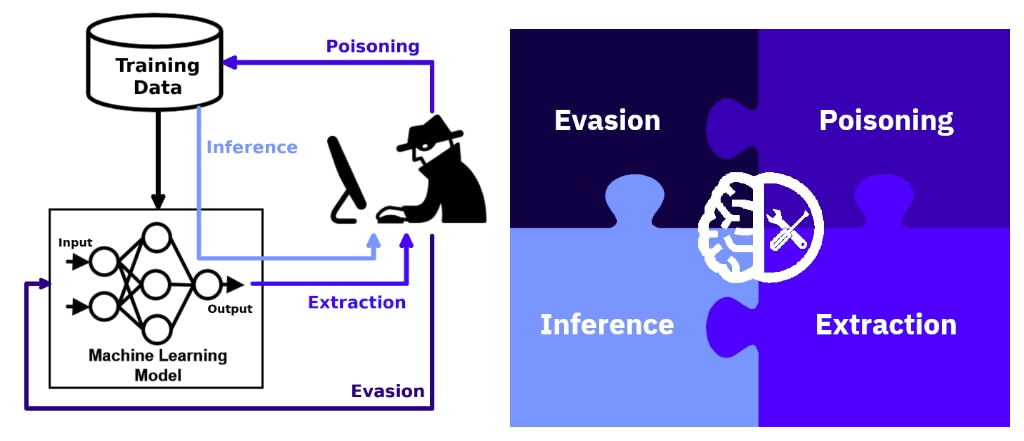
なお、AIセキュリティのためのPythonライブラリとしては、CleverhansやFoolbox、AdvBoxなどが知られていますが、これらのライブラリは「(敵対的サンプルなどの)一部の攻撃手法にしか対応していない」、「対策をサポートしていない」、「開発が停滞している」、「ドキュメントが整備されていない」などの理由から、セキュリティテストに利用するには難がありました。
一方、ARTは2018年に世界最大のハッカーカンファレンスである「black Hat」で発表されて以来、多くのContributorにより頻繁に機能追加が行われています。また、ドキュメントやチュートリアルも充実しているため、Pythonを扱える開発者の方であれば容易に利用することができます。
なお、AIディフェンス研究所では、「Adversarial Robustness Toolbox(ART)超入門」と題して、ARTの基本的な使い方をハンズオンを交えて解説していますので、ご興味のある方はご一読ください。
Adversarial Threat Detector
ARTは非常に有用なAIセキュリティのPythonライブラリですが、利用するにはプログラミングを行う必要があります。そこで筆者らは、「AIの脆弱性を全自動で検出する」を目指して「Adversarial Threat Detector」(ATD)と呼ぶ脆弱性スキャナーを開発しています。
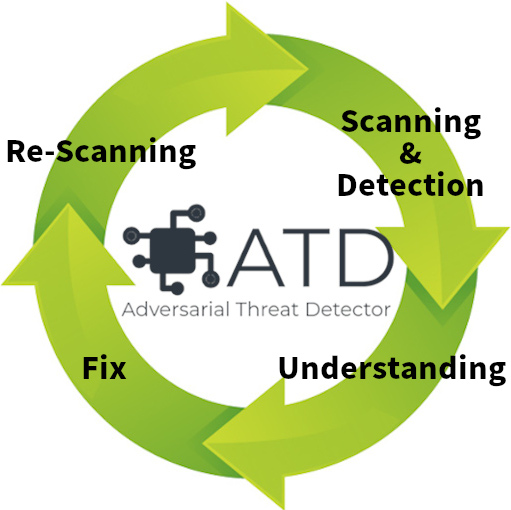
ATDは以下4つのサイクルを回すことで、単にAIの脆弱性を検知するだけでなく、開発者の方々の脆弱性と対策の理解を深めることを目的としています。
- 脆弱性の発見(Scanning & Detection)
- 開発者の脆弱性の理解(Understand)
- 脆弱性の修正(Fix)
- 修正確認(Re-Scanning)
なお、ATDは前述した「Adversarial Threat Matrix」に沿って開発を進めています。また、現在のところ脆弱性の検出や防御には「Adversarial Robustness Toolbox (ART)」を活用しています。
現在のATDは、MVP(Minimum Viable Product)ともいえる非常に限られた機能しか実装されていませんが、今後は月1回程度のペースで機能追加を行っていきますので、ご興味のある方は定期的にリリース情報をご確認いただけると幸いです。
まとめ
本コラムでは、筆者らがAIの安全確保に役立つと考えるガイドラインやテストツールなどを紹介しました。
アルゴリズムやフレームワークなどのAI関連技術は日進月歩であり、それに伴いAIに対する攻撃手法も進化(深化)しています。今日の安全が明日も確保される保証はありません。それゆえに、常に最新情報をキャッチアップし、知識をアップデートし続ける必要があります。
現在のところAIに対するサイバー攻撃は活発化していませんが、Gartnerのレポート「A Gartner Special Report: Top 10 Strategic Technology Trends for 2020」によると、「サイバー攻撃に関して、学習データ汚染や敵対的サンプルなどのAIを対象とする攻撃は、2022年までに全体の30%に達するだろう」とも言われています。
また、著名なサイバーセキュリティの専門家である、F-Secureのヒッポネン氏は2019年のインタビュー記事の中で、「今のところ、機械学習に関する十分な知識や経験がある人は、犯罪行為に手を染める必要はなく、十分な給料の仕事を簡単に見つけることができる」と述べています。
その一方で、2〜3年後(記事掲載から計算すると2022年ごろ)には「機械学習は扱いがより簡単になり、あらゆる人が機械学習を用いてサイバー攻撃を行うことができるようになる」とも述べています。本コメントは、「攻撃者が機械学習を使用してサイバー攻撃を行う時代が来るのか?」という問いへの答えであり、本コラムのテーマである「AIへの攻撃(と対策)」の文脈とはニュアンスが異なりますが、AIへの攻撃についても同じことが言えると考えます。
よって、AIへの攻撃が横行する時代が到来する前に、AI開発・運用の中にセキュリティの仕組みを取り入れ、攻撃者の後手に回らないように準備しておくことが重要であると、筆者らは考えます。
本コラムを持ちまして、これまで8回に分けて連載してきた「AIセキュリティ超入門」は終了となりますが、筆者らのAIセキュリティの取り組みはまだまだ続きます。何らかの形でお会いする機会がありましたら、何なりとAIセキュリティについてお尋ねください。皆さまのAIの安全確保に微力ながら協力させていただければと思います。
最後に、株式会社ChillStackと三井物産セキュアディレクション株式会社は、AIの開発・提供・利用を安全に行うためのトレーニングを提供しています。
本トレーニングでは、本コラムで解説した攻撃手法の他、AIに対する様々な攻撃手法と対策を、座学とハンズオンを通じて理解することができます。
本トレーニングの詳細やお問い合わせにつきましては、AIディフェンス研究所をご覧ください。
※本コラムの執筆者は以下の通りです。
| 高江洲 勲(三井物産セキュアディレクション株式会社) 情報処理安全確保支援士。CISSP。Webシステムに対する脆弱性診断に10年以上従事。また、AIセキュリティに着目し、機械学習アルゴリズムの脆弱性に関する研究や、機械学習を用いたセキュリティタスク自動化の研究を行っている。研究成果は、世界的に著名なハッカーカンファレンスであるBlack Hat ArsenalやDEFCON、CODE BLUE等で発表している。近年はセキュリティ・キャンプやSECCONワークショップの講師、国際的なハッカーカンファレンスであるHack In The BoxのAIセキュリティ・コンペティションで審査員を務める等、教育事業にも貢献している。 |
駒澤大学仏教学部に所属。YouTubeとK-POPにハマっています。
AIがこれから宗教とどのように関わり、仏教徒の生活に影響するのかについて興味があります。



























