

近年のAI(人工知能)の台頭により、さまざまな機械学習が注目されるようになりました。
その一つにSVM(サポートベクターマシーン)があります。SVMとは高度な数学的理論に基づいた手法であり、ディープラーニング台頭以前に最も人気があった機械学習手法の一つです。
SVMについて理解できればデータ分析や分類予測に役立つので、ぜひ最後までご覧ください。
▼AIについて詳しく知りたい方はこちら

目次
SVM(サポートベクターマシン)とは?
まず、サポートベクターとは何か解説していきます。
サポートベクターとは「データを分割する直線に最も近いデータ」です。「マージン最大化」と呼ばれる考え方を使い、正しい分類基準を見つけます。
2つの特徴量で分類する問題を考えてみます。マージンとは、「境界とデータとの距離」のことです。これが小さいと、少しのデータの違いで誤判定してしまいます。
マージンを最大化する境界線を引くことがSVMの目的となります。境界の近くにあるデータは、分類が難しいデータであることは明らかです。
一方で、境界から離れている(分類が明らかな)データは考慮する必要はありません。なので、境界の近くにあるデータ、すなわちサポートベクトルのみを用いて分類を行います。
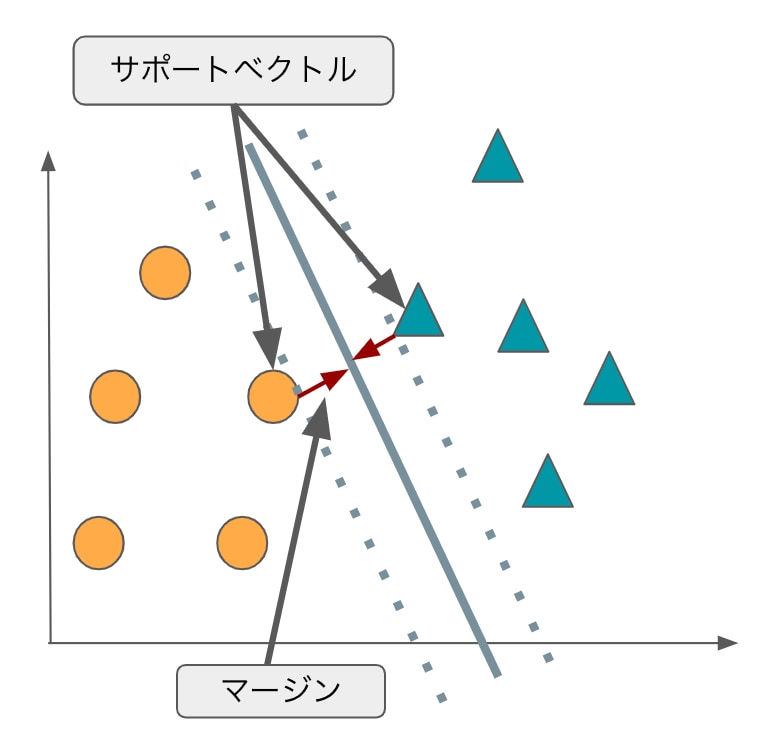
AINOW編集部作成
SVMの仕組み
x, yの2つの特徴量をもとに、データが◯と△のどちらのクラスかを分類するような分類器をつくります。
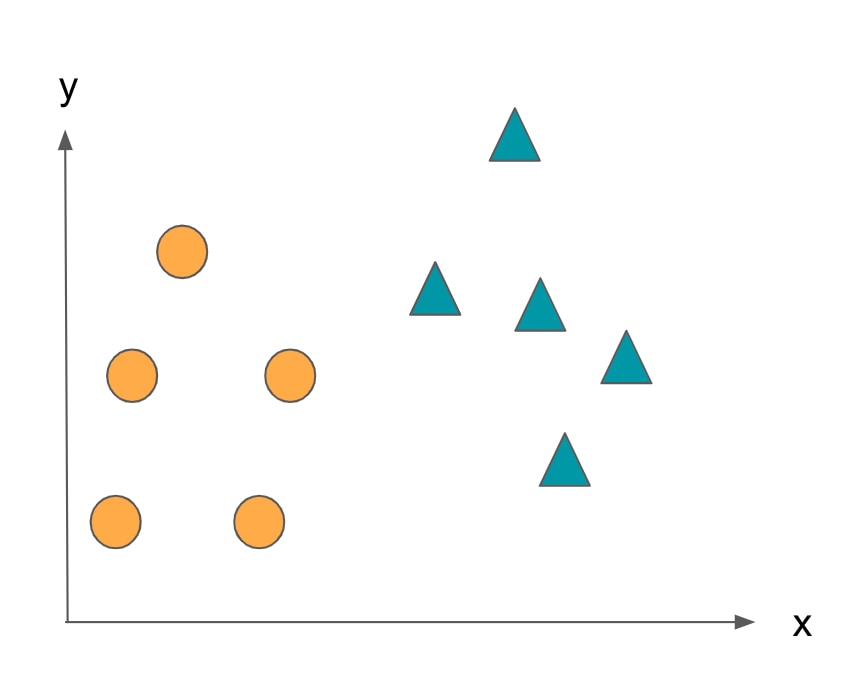
AINOW編集部作成
このトレーニングデータを、各データのクラスも考慮して1番適切に分ける境界線を求めます。
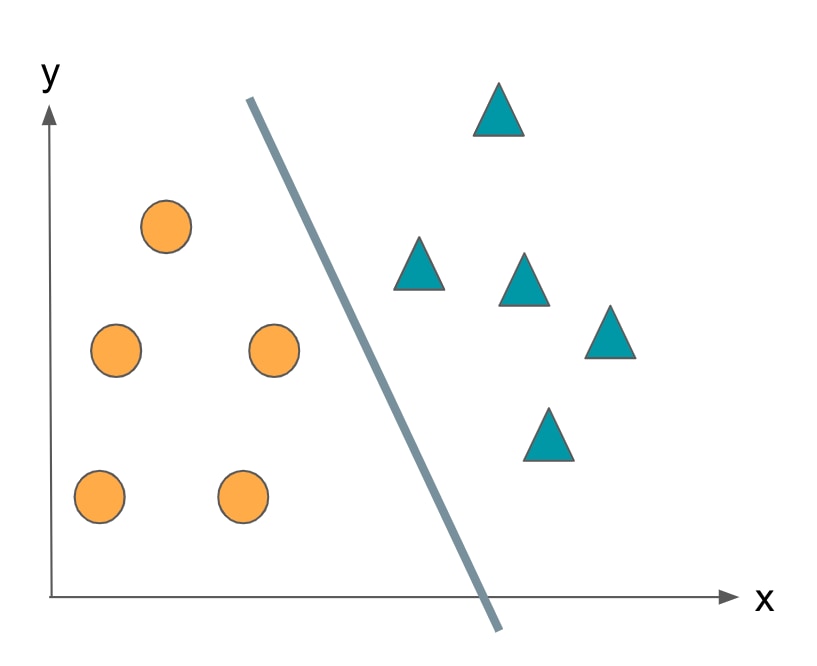
AINOW編集部作成
この境界で一方のサイドに位置するデータを全て◯、もう一方のサイドに位置するデータを全て△と分類します。
AINOW編集部作成
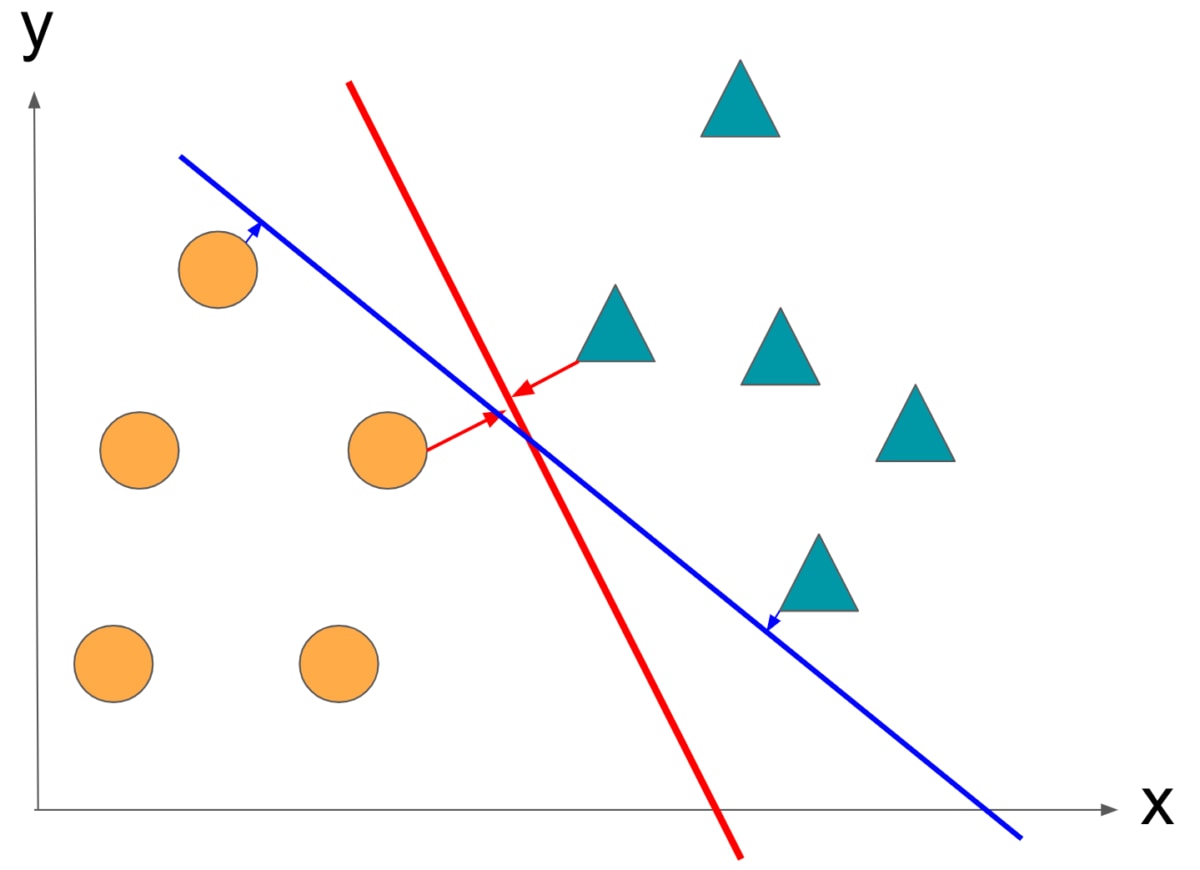
ここで、赤と青の境界線どちらの方がよい境界線でしょうか。
答えは赤です。青の境界線はマージンが小さいことがわかります。以上がSVMの境界の決め方になります。
過学習の問題
これまでは、境界線によってデータ群を明確に2つに分けられる例を説明してきました。このように、2つを明確に分けられることを前提にしたマージンをハードマージンといいます。
一方で、2つに明確に分けることが難しく、どうしても誤判別してしまうデータに対しては、誤判別を許容する前提としたマージンをソフトマージンといいます。
「正確な判別」を求めすぎると貴重な判別特徴を見失ってしまい、予測の精度が下がってしまうことがあります。そしてこの問題を過学習といいます。
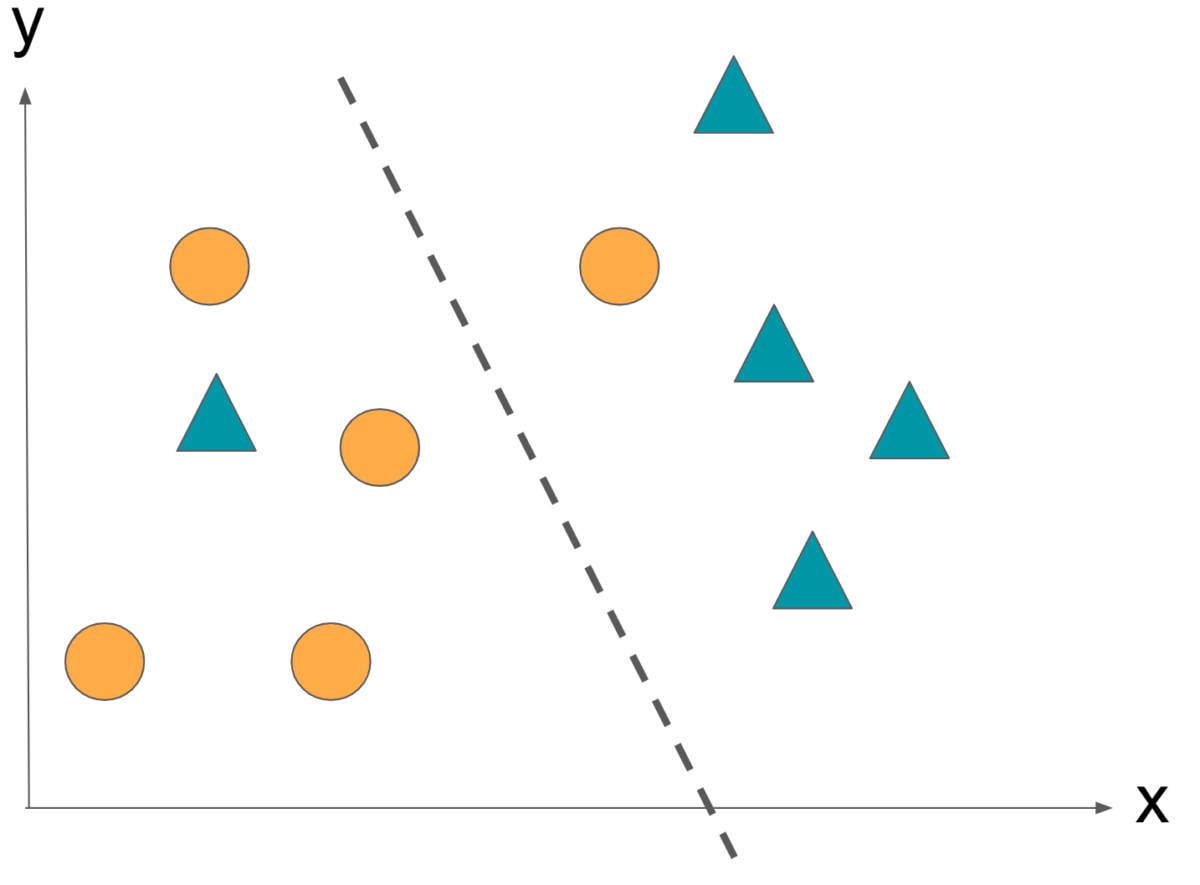
AINOW編集部作成
過学習せずに予測ができることを汎化性といいます。この汎化性を高める為に、あえて誤分類を許容します。
ソフトマージンは「境界線とデータはなるべく最小・誤判別は少なく」を満たします。
ここまではなした手法では、直線で分類することができるデータしか対応できません。ここで、「カーネル法」という手法を用いることで、直線で分類できないデータに対しても分類可能になります。
実空間のデータを超平面で分離できる空間に写像してから、線形 SVM と同じ仕組みでデータを分離します。下の例では2次元で分類できないものを3次元に写像して分類しています。
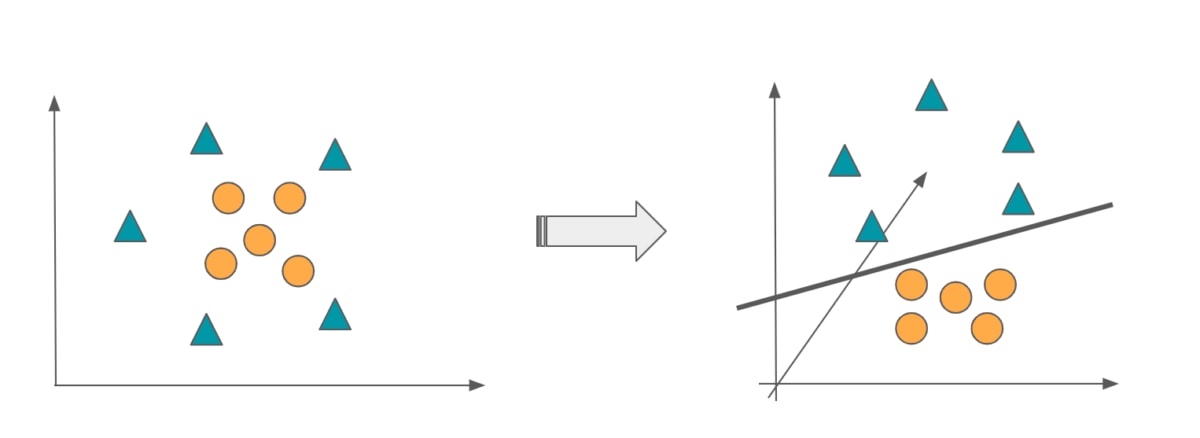
AINOW編集部作成
SVMのメリットとデメリット
ここでSVMのメリットとデメリットを確認します。メリット、デメリットを押さえておくことで、アルゴリズムの選択をスムーズにします。
メリット
|
デメリット
|
以上の代表的なメリットデメリットを考慮して使用するアルゴリズムを決定する必要があります。
▶AIのアルゴリズムとは?|図を用いてわかりやすく解説!>>
SVMでできること【応用例3選】
次に、SVMの主な応用例を3つ紹介します。
1. 株価予測
SVM(サポートベクターマシーン)は、2分類の線形識別を得意としています。SVMでは株価が上がるor下がるの二者択一の予測ができます。
過去の株価の変動データを学習して、前日よりも株価が上昇する場合と下落する場合をパターン認識すると、つぎの日の株価の動きを予測する機械学習モデルを構築できます。
2. 数字認識
手書きの数字の画像を0~9などの数字カテゴリに分類することもできます。
具体的には、数字は0~9の10文字で、これをSVMを多クラスの識別が可能なように拡張して識別します。これを応用することで、郵便番号の認識などに利用できます。
3. 異常値検出
このケースでは、SVMを教師なしの1クラス分類に応用します。
正常データとして1つのクラス分を学習させ、識別境界を決定することで、その境界を基準に外れ値を検出します。
クレジットカードの不正取引を検出したり、工場で熱やサイズの異常を検知したりすることができます。
SVMを実装してみよう!
ここではscikit-learnを用いて実装していきます。
scikit-learnはPythonの機械学習用モジュールで、SVMの実装でよく用いられます。ここでは、実際にscikit-learnの公式のコードを参照します。

このコードで識別器の学習ができます。Xは説明変数で、yが目的変数です。
こちらのコードにおいては、(0,0),(1,1)の2つの2次元データとなっています。(0,0)のラベルは0で、座標が(1,1)のラベルが1であることを示しています。
そして、fit()によって学習を指示します。
例えば花の分類をしたい場合は、花の色、大きさ、形などの特徴をXに、花の種類をyに入れます。

こちらのコードでテストデータに対して推定を行います。(2,2)がどちらのラベルになるか推定します。
つまり、ここではarray([1])と、1のラベルがつけば成功です。
SVMを学ぶ -おすすめと注意点-
ここではSVMのおすすめ勉強法と注意点を紹介します。
おすすめ勉強法
おすすめの勉強法は、スクールやオンライン講座を利用することです。
今回、SVMの仕組みの基本的な部分のみ説明してきました。しかしより詳しく理解するのはハードルが高いでしょう。
そのため、質問やサポート体制が整った、スクールやオンライン講座で学ぶのが最も早く正しく習得できるかと思います。
あくまでもアルゴリズムの一つとして基本的な理解だけでいいという方は、Qiitaなどの情報共有サービスで十分です。しかし、下記で述べる注意点には留意して勉強を進めることをおすすめします。
▶未経験からAIを学べる講座23選|無料からオンラインまで徹底比較>>
▶AIを学べるスクールおすすめ5選|メリット・デメリット、選び方まで紹介>>
学ぶ上での注意点
SVMは分類問題に長けた非常に強力なアルゴリズムです。しかし、どんなに優秀なアルゴリズムでも万能ではありません。
うまく利用するためには、解決したい問題を正しく理解し、SVMが一番適したアルゴリズムか判断する必要があります。
そのため、メリット・デメリットはしっかり学んでおきましょう。メリット・デメリットをしっかり押さえておけば、アルゴリズム選択に役に立つので、より建設的な学習ができるでしょう。
まとめ
今回はSVMの基本から実装方法、勉強法まで説明しました。
SVM(サポートベクターマシーン)について少しでも理解を深められると幸いです。最後までご覧いただきありがとうございました。
◇AINOWインターン生
◇Twitterでも発信しています。
◇AINOWでインターンをしながら、自分のブログも書いてライティングの勉強をしています。



























