

今回は、機械学習の主要な12のアルゴリズムの概要や活用シーンを理解できるように、わかりやすく説明します。
機械学習を知る上で必要不可欠な用語(教師あり学習など)に関しても、この記事を通して、きちんと理解できるようになっています。
また、さらに詳しく機械学習を学びたい方向けに、より専門的な記事や、機械学習ライブラリのチュートリアルも紹介しています。
▼機械学習について詳しく知りたい方はこちら

▼AIについて詳しく知りたい方はこちら

目次
機械学習の代表的なアルゴリズム12選
ここからは、機械学習の代表的なアルゴリズムについて紹介していきます。今回紹介するアルゴリズムは以下のとおりです。
- 線形回帰
- ロジスティック回帰
- 決定木
- ランダムフォレスト
- K近傍法(KNN)
- K平均法(k-means)
- サポートベクターマシン(SVM)
- サポートベクター回帰(SVR)
- ナイーブベイズ
- CNN
- RNN
- GAN
それぞれ解説していきます。
①線形回帰
回帰分析とは、予測したい「目的変数」を、他の「説明変数」に基づいて予測する手法のことです。
説明変数が1つの場合、単回帰分析と言います。目的変数yを従属変数、説明変数xを独立変数としたとき、単回帰分析はaとbをパラメータとして持つ「y=ax+b」という形の一次関数で表現できます。
また、説明変数が複数の場合は重回帰分析と言います。
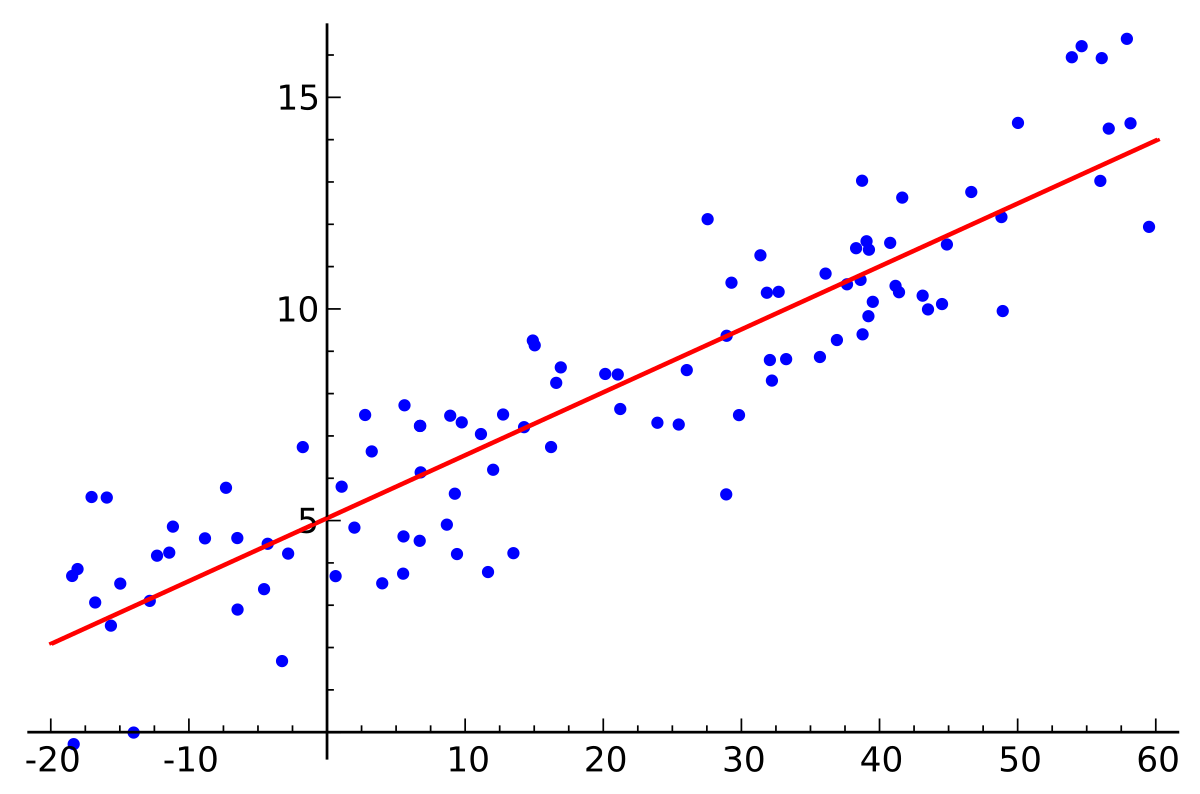
回帰分析には「線形回帰」と「非線形回帰」の2種類があります。
やや厳密さを欠く直感的な説明ですが、上記の図のような関係、言い換えればデータ間の関係を直線的に表現できるような回帰分析を「線形回帰」と言います。
| ▼活用シーン / メリット
「売り上げ」や「気温」の予測 |
②ロジスティック回帰
ロジスティック回帰は、医学の分野で開発された分析手法です。
線形回帰という手法を応用したもので、名前に回帰とついているのですが、実際は分類問題に使用される手法です。
つまり基本的には目的変数が「Yes(= 1)」か「No(= 0)」のどちらかに分類できるような問題を扱うということです。
この手法では量的変数(数字で表せるもの)から質的変数(“好き・嫌い”など数字では表しにくいもの)を推測するのですが、この時に変数の値を予測するのではなく、目的変数が”1”になる確率を予測します。
そのため重回帰分析などで1以上の数値や、マイナスの値が出てわかりにくかった場合でも、ロジスティック回帰分析では必ず0から1の範囲で確率がわかるので、分析結果を見たときに理解しやすいことが特徴です。
| ▼活用シーン / メリット
「特定の病気にかかっている確率」の予測や「マーケティングの効果測定」などに使えます。 |
③決定木
決定木には分類木と回帰木の2種類があり、閾値を設定して学習するアルゴリズムです。
樹木形をした以下のグラフのようなものです。リスクマネジメントをはじめ、何かしらの決定をする際に利用されます。
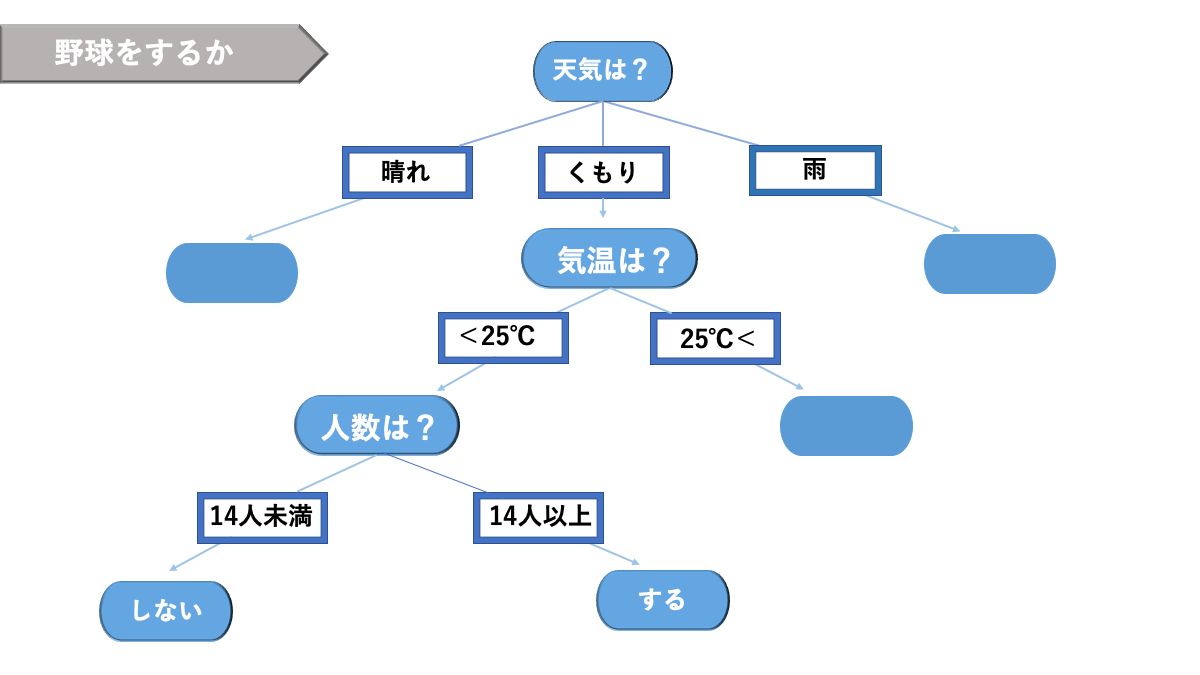
AINOW編集部作成
| ▼活用シーン / メリット
データの特徴や、説明変数ごとの影響度をわかりやすい形でみることができる、予測モデルを作れます。 決定木を応用した「ランダムフォレスト」など、その他のアルゴリズムのほうがより良い精度が出ることが多いです。 |
④ランダムフォレスト
ランダムフォレストは、複数の決定木で出た結果を用いて、多数決や平均をとって最終的な結果を出力する仕組みをとっています。
この手法を使うことで、精度の悪い決定木があったとしても他の決定木で結果を補えるため、全体としての精度を向上させることができます。
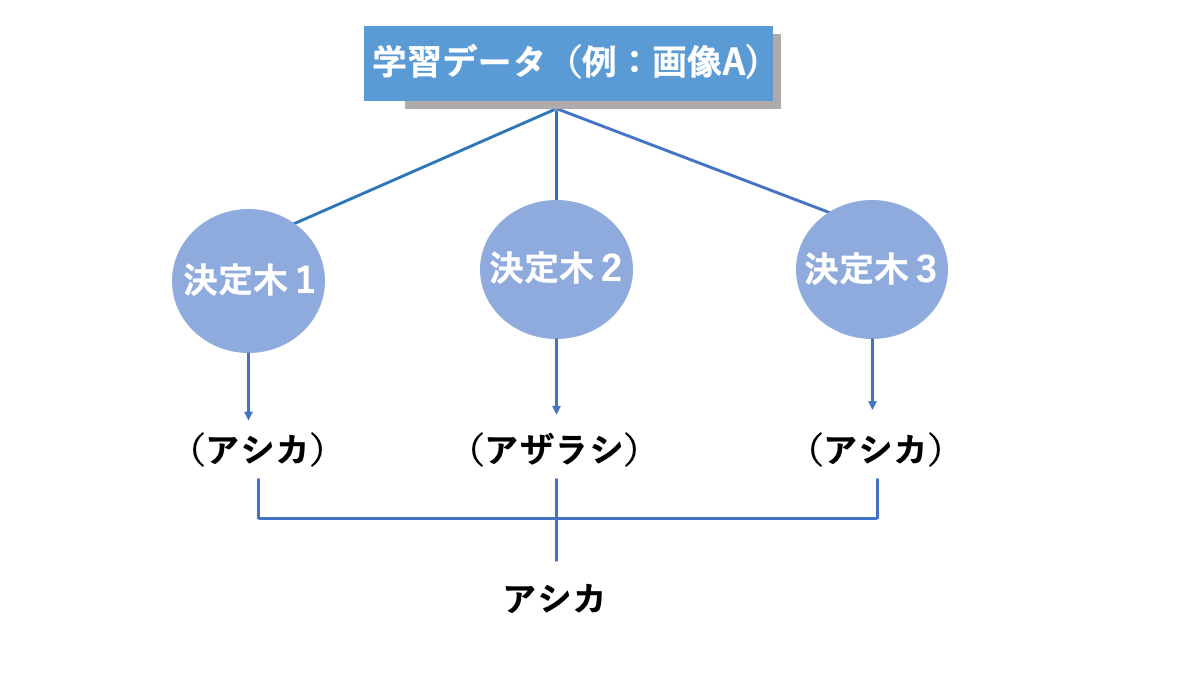
AINOW編集部作成
| ▼活用シーン / メリット
「手軽に試せて、精度の良い説明可能なモデル」が作れる、機械学習初心者にも扱いやすいアルゴリズムです。決定木と同じで、分類と回帰の両方の問題に対応できます。 |
⑤K近傍法(KNN)
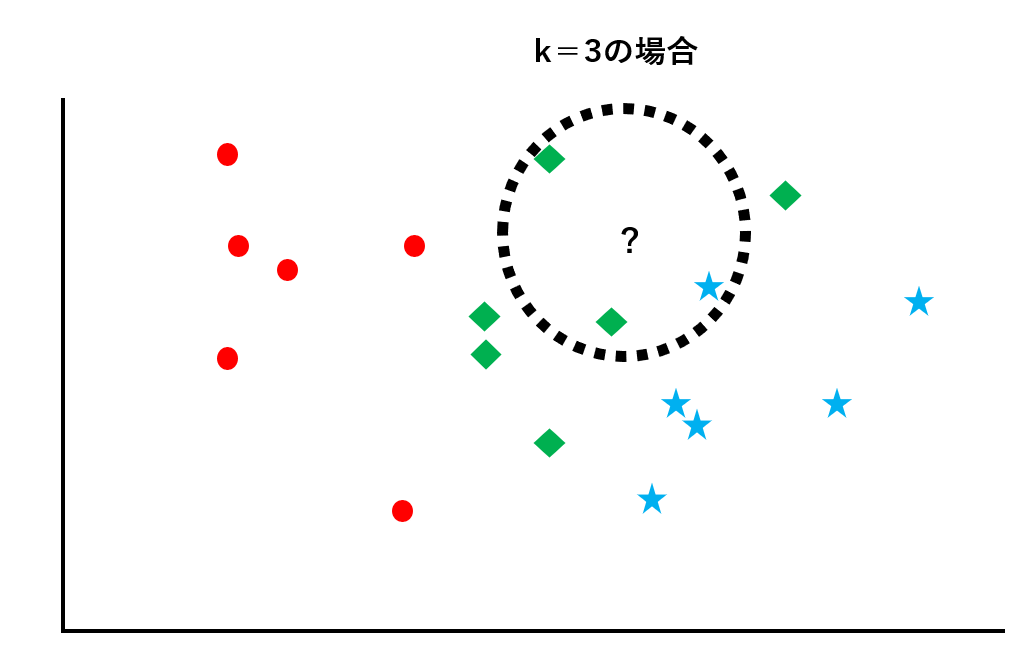
典型的な分類問題のアルゴリズムです。座標上に散らばっているクラス分けされたデータ群に対して、未知のデータがどのクラスに属するのかを判別します。
未知のデータから距離が近い順にk個データを取り出し、そのk個のデータのなかで最も数が多いクラスに未知のデータを振り分けます。
既にラベルが貼られたデータ群に対して、未知のデータがどのクラスに属するのかを判別します。この例では、赤丸のクラス、青星のクラス、緑ダイヤのクラスの3種類があります。
k=3として未知のデータから距離の近い順に3つのデータを取り出します。この例では青星が1つ、緑ダイヤが2つなので、多数決をとってこの未知のデータは緑ダイヤのクラスに属するものと判断します。
| ▼活用シーン / メリット
計算量が多くなりますが、悪くない精度のモデルが作れます。また、仕組みも直感的で、説明可能なのも魅力です。 データの次元が大きくなると精度が出にくくなるのがネックです。この後紹介するSVMは、データの次元が大きくなっても精度が高いです。 |
⑥K平均法(k-means)
k-means法は、最もよく用いられるクラスタリングのアルゴリズムです。
まず、散らばったデータ群に対してランダムにk個の重心点を定め、これを核とします。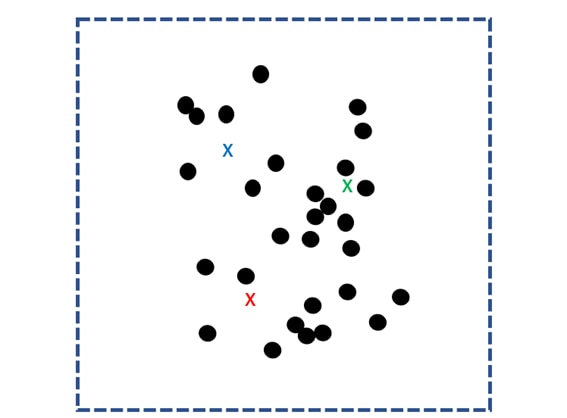
そして、k個の核との距離をすべてのデータに関して計算し、最も近い核のグループにわけます。このグループのことを「クラスタ」と言います。
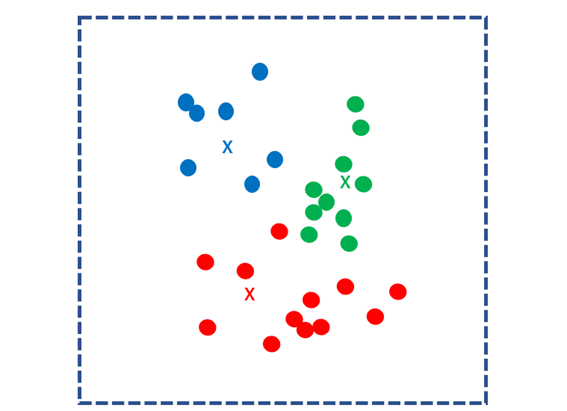
次に、クラスタごとの重心点を求め、それを新たなk個の核とします。同様のプロセスを繰り返し、各データを最も近い重心点のクラスタにわけます。
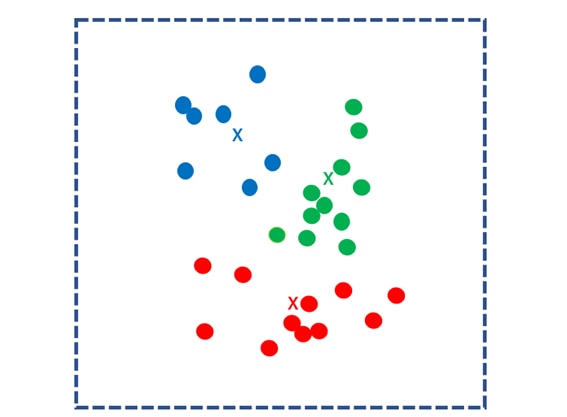
このプロセスを重心点が移動しなくなるまで繰り返します。重心点が更新されなくなったとき、計算は終了です。
| ▼活用シーン / メリット
例えば、顧客データを分析することで、属性の似た顧客の集団を分析できます。その集団ごとに戦略を立てて商品や情報をアピールすることで、より効率的なマーケティングが可能です。 |
▶【2021年版】AI関連資格をまとめて解説!最新スケジュールと取得メリットも紹介>>
⑦サポートベクターマシン(SVM)
サポートベクトルマシンは、データ群に対して「マージン最大化」という計算をするアルゴリズムです。図を参考にしながらそのプロセスを追っていきましょう。
赤丸と青星が散らばっているデータに対して、両者を「境界線」でわける問題を考えます。しかし、この図の通り、線の引き方はたくさんあります。
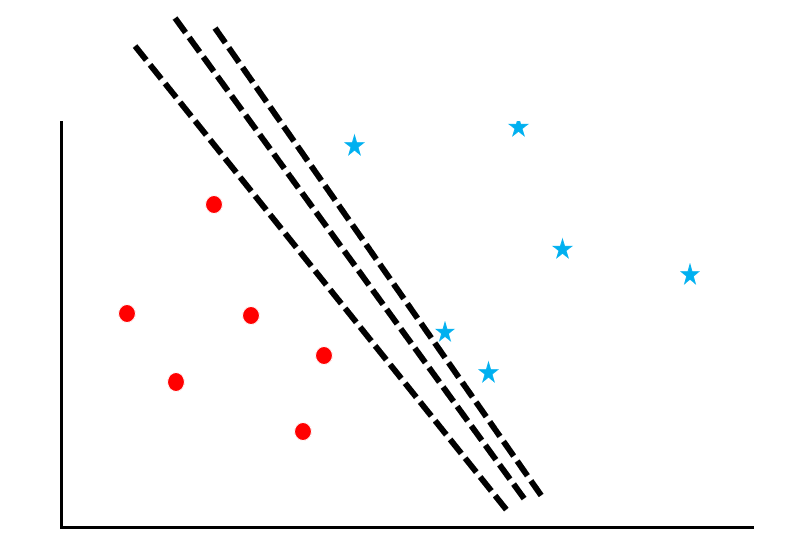
ここで「サポートベクトルのマージンを最大化すること」を考えます。
サポートベクトルとは境界線の近くのデータのことを指し、マージンとは境界線とデータとの距離を意味します。図の緑の線がマージンです。
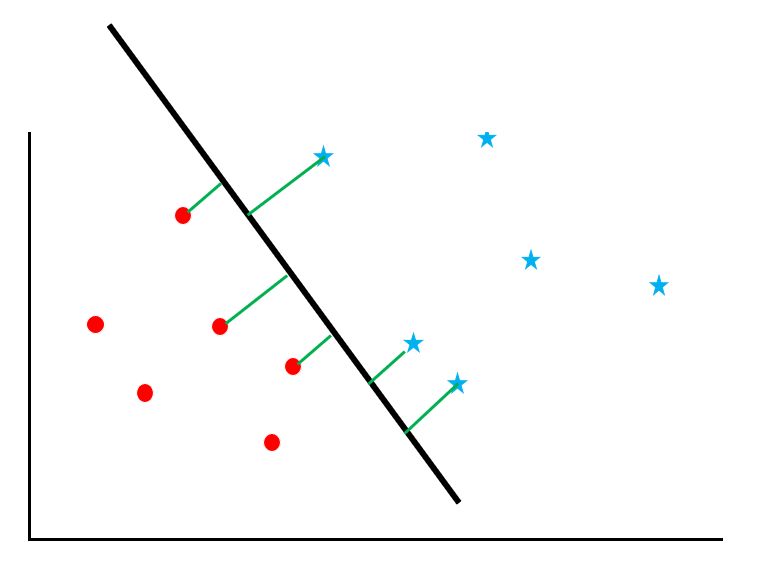
| ▼活用シーン / メリット
ランダムフォレストと並んで、昔から人気の手法です。データの次元が大きくなっても精度が高く、過学習のリスクが低いのが特徴です。 しかし、ランダムフォレストのように、手軽に精度が出せるアルゴリズムではないので、根気よく取り組む必要があります。詳しい記事を執筆予定です。 |
⑧サポートベクター回帰(SVR)
サポートベクター回帰(Support Vector Regression)はサポートベクターマシンの回帰版で、多くの変数を含んだ非線形な問題を解決することができる手法です。
SVMがマージンの最大化と誤推計サンプルを減らすやり方で学習するように、SVRでは重みの最小化と誤差の最小化で学習します。
⑨ナイーブベイズ
この手法はベイズの定理という、統計学では基礎として用いられている有名な定理を使って、それぞれのクラスに分類される確率を計算し最も確率の高いクラスを結果として出力する、分類問題を解くためのモデルです。
| ▼活用シーン / メリット
計算量が少なく処理が高速であるため、大規模データにも対応できますが、やや精度が低いといった問題があります。 スパムフィルターなどの、テキスト分類のタスクで使われることが多いです。 |
⑩CNN
CNNは、画像関連のタスクにおいて非常に効果的なモデルです。
2012年にGoogleが開発した猫を認識するAIに使われているモデルもCNNです。
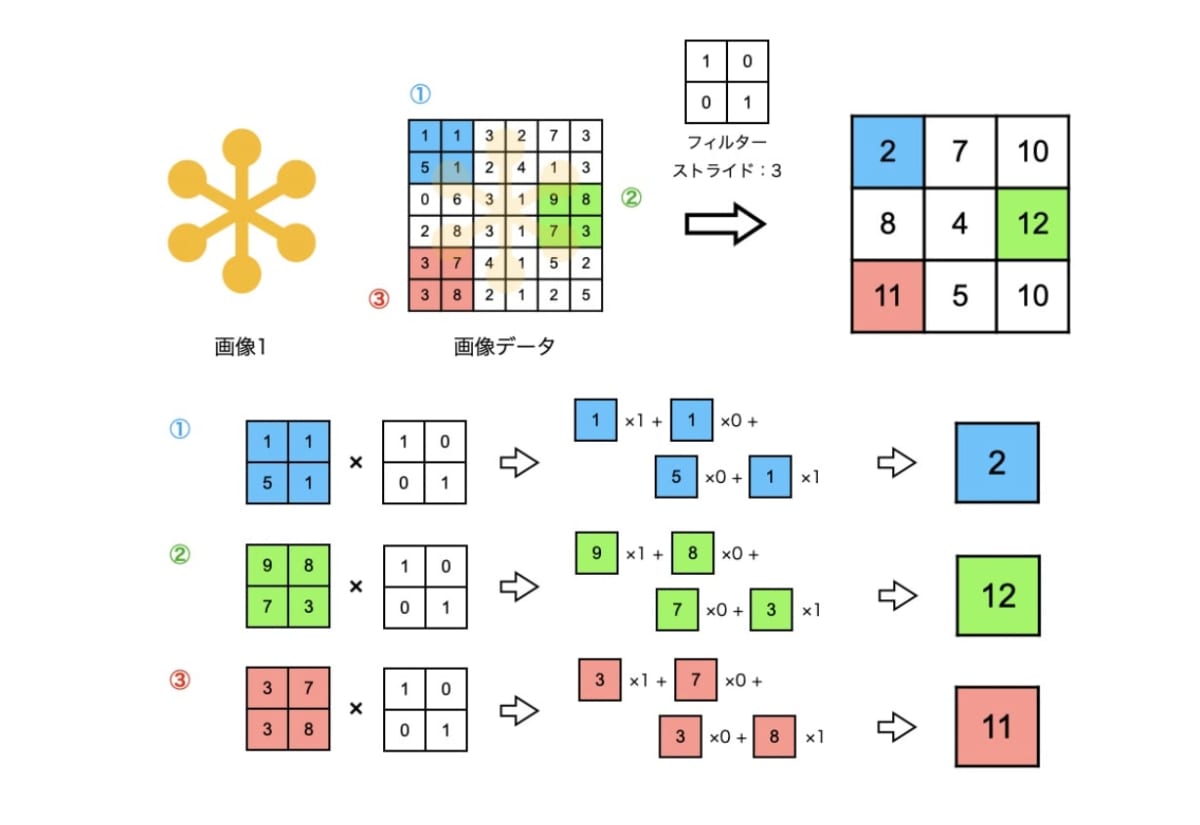
CNNの大きな特徴は、畳み込み層とプーリング層です。
これらの層がどういった操作を行なっているかということについては割愛します(興味がある人はオライリーの「ゼロから作るDeep Learning」を読んでみてください)が、これらの層を何層にも重ねていくことで、入力画像からより抽象的な情報を抽出することができるようになります。
そうして抽出された情報をもとに、複雑なタスクに対しても高いパフォーマンスを出しています。
▶CNN(畳み込みネットワーク)とは?図や事例を用いながら分かりやすく解説!>>
⑪RNN
RNNは、時系列データの解析や自然言語処理などのタスクにおいて効果的なモデルです。
時系列データとは、例えば株価のように、時間の経過とともに値が変化するようなデータのことを指します。
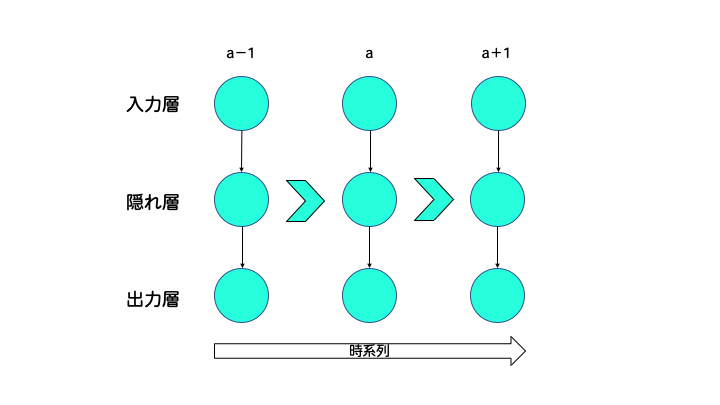
一方で自然言語処理とは、人間の曖昧性を伴った言語の意味の理解や、ある言語から違う言語への翻訳を目的にします。
ここで時系列データにとって、ある時刻の情報とそれ以前の時刻の情報の関係が重要であるように、自然言語にとっても、文章中のある言葉とその前の言葉の関係(例えば主語の後には動詞が来るとか)が重要になります。
RNNはそのような過去の情報も考慮した計算ができるので、上で述べたようなタスクに対して有効となっています。
▼自然言語処理について詳しく知りたい方はこちら>>

⑫GAN
最後に紹介するのはGANです。敵対的生成ネットワーク(Generative Adversarial Network)は現在、主に画像分野において好成績を残している手法です。
GANは2つのネットワークで構成されており、1つは生成器(ジェネレータ)でもう一つは識別器(ディスクリミネータ)と言います。
| ジェネレータ:ある値を入力値として受け取り、画像データを出力する。 ディスクリミネータ:ジェネレータが出力した画像データを受け取り、本物か偽物かを予測して出力する。 |
ジェネレータはディスクリミネータが間違えるようにアウトプットと学習を繰り返し、ディスクリミネータは偽物をきちんと見抜けるように学習していきます。
この2つがイタチごっこをすることで、お互いの精度をどんどん上げていきます。
モデルが自動的に精度を上げていくGANは、これまで他の手法ではなかなか達成できていなかった、驚くような成果をもたらしています。
機械学習における4(+1)つの学習手法
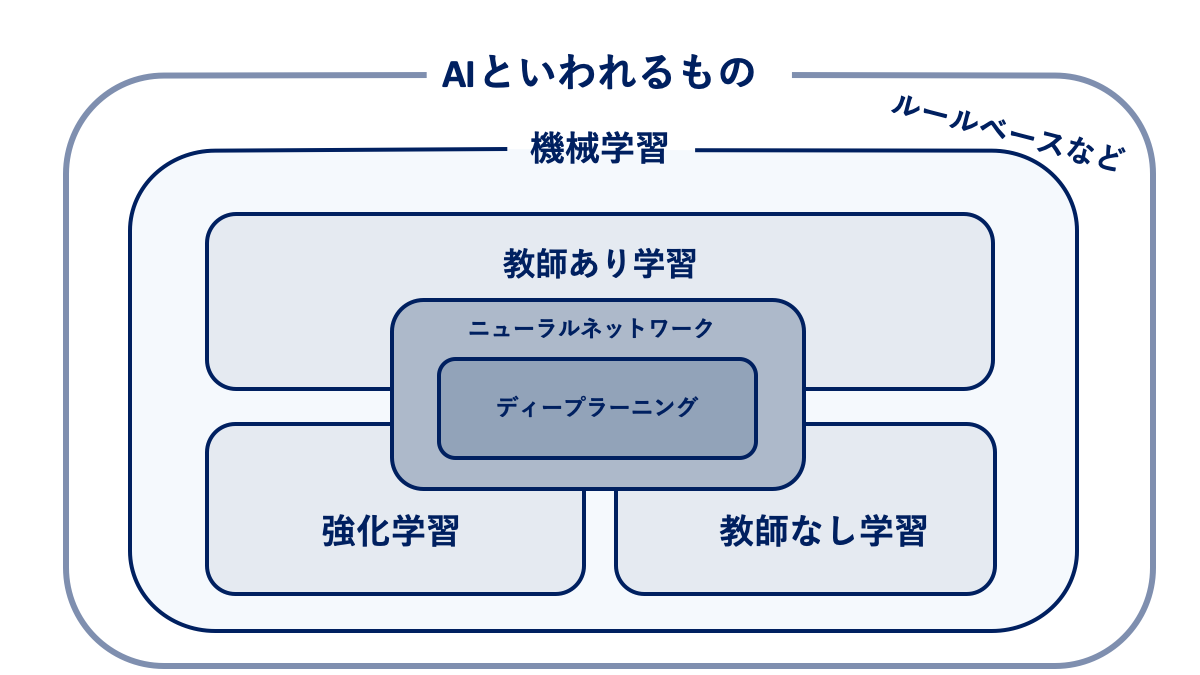
①教師あり学習
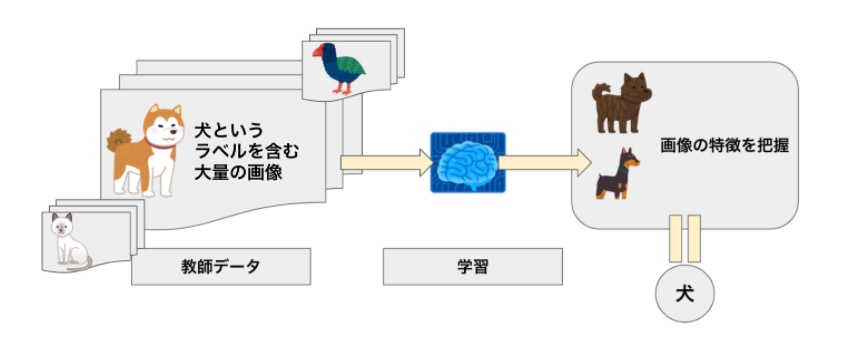
教師あり学習は、学習データに正解ラベルを与えた状態で学習させる手法です。
教師あり学習では、教師データを既知の情報として学習に利用し、未知の情報に対応することができる回帰モデルや分類モデルを構築します。
事前に「犬」や「猫」というラベル(教師データ)が付けられた大量の写真をコンピュータに学習させて、モデルを構築します。
ラベルのない写真が与えられた場合、モデルはその画像に一番近い特徴を持つ学習済みの画像に貼ってあるラベルを出力します。つまり、このモデルは与えられた画像が「犬」か「猫」かどうかを検出できるようになります。
②教師なし学習
教師なし学習は、学習データに正解ラベルを与えない状態で学習させる手法です。
主に、データのグループ分け(クラスタリング)に活用されます。
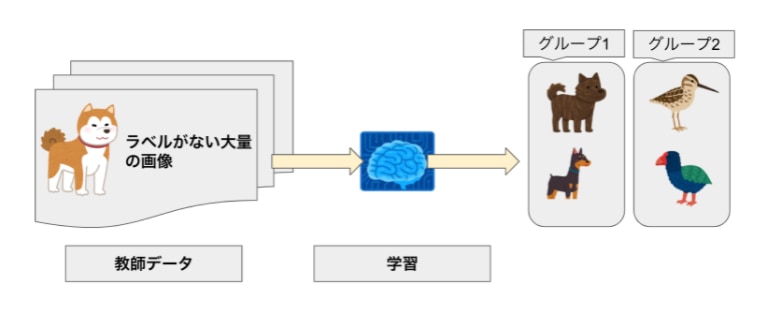
教師データにラベルがない場合でも、大量の画像をコンピュータに学習させれば、画像の特徴 (例:大きさ、色、形状)からグループ分けや情報の要約が可能です。
③強化学習
強化学習とは、与えられたデータから学習していくのではなく、自ら行動を起こし、試行錯誤を通じて、報酬(評価)が得られる行動や選択を学習します。
強化学習の例として、犬のしつけを例に挙げます。犬がお手をすればおやつを与えます。「お手」という試行を犬が繰り返すと、犬は「お手をする⇒餌がもらえる」ということを学習します。
ロボットの歩行を例にとると、「歩けた距離」を報酬とすると、“手の動かし方、足の動かし方を試行錯誤して歩行距離を伸ばす”ということが、強化学習に相当します。
▶《保存版》強化学習とは|関係用語・機械学習での位置付けなど解説!>>
④半教師あり学習
半教師あり学習では、アノテーションを一部自動で行います。
例えば、人間の画像に対して、性別の判定を半教師あり学習で行うとします。まずは、人間がアノテーションを行います。
続いて、アノテーション済みのデータから、「この特徴をもっていると男性、これだと女性に分類」と学習させます。
そして残りの画像データのラベルを予測して、確信度の高いものをデータに加えます(ブートストラップ法)。
これがうまくいけば、教師データの作成において、コストの削減が可能です。
機械学習の活用事例3選
機械学習の活用事例を3つ紹介します。
これから詳しく解説します。
①タクシーの配車の自動化
タクシーの配車の自動化には機械学習が活用されています。
いつ、どのような場所でタクシーの需要があるかを予測してタクシーを配車することでタクシーの乗車率を向上させることで、売り上げ増加が見込めます。
実際にこの仕組みを利用した実証実験では、1日あたり1人平均で1400円の売り上げ上昇が報告されています。
参考:AIタクシー─交通運行の最適化をめざしたタクシーの乗車需要予測技術― >>
②チャットボットによる問い合わせ対応
ユーザーからの問い合わせに自動で対応してくれるチャットボットにも機械学習が活用されています。機械学習を利用した自然言語処理技術を利用してユーザーからの問い合わせ内容を分析し、適切な回答を提供します。
チャットボットを利用することで、問い合わせ対応する人件費の削減、対応時間短縮によるユーザの満足度の向上などの効果が見込めます。
③顔認証
顔認証には機械学習が得意とする画像認識の分野の技術が利用されています。
目や鼻、口など特徴点の位置、輪郭などを元に個人を識別します。
JRのうめきた新駅ではICカードではなく、顔認証システムを利用した改札機が実験的に設置されており、いわゆる「顔パス」で乗車できる日も近いかもしれません。
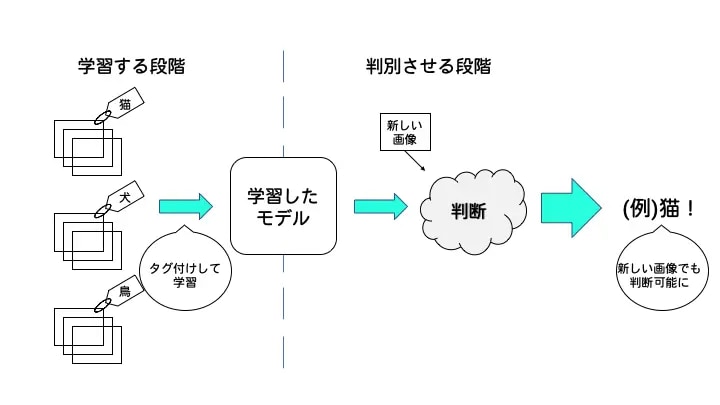
深層学習(ディープラーニング)と機械学習のアルゴリズムの関係とは?
深層学習とは、ディープラーニングとも呼ばれ、従来の機械学習と違い、特徴量を機械が学習する点にあります。教師あり学習、教師なし学習の両方が存在します。
例えば、犬と猫を判別するAIをつくるとします。従来は、どこに注目するかを人間が指定していました。例えば、耳の形やひげがあるかなどです。
一方でディープラーニングは、何が重要であるかを機械が自動的に学習します。その結果、人間が指摘した特徴を用いるより、高精度になる場合があります。
▶AIのアルゴリズムとは?|図を用いてわかりやすく解説!>>
▼ディープラーニング(深層学習)について詳しく知りたい方はこちら

機械学習のアルゴリズムをPythonで書くには?
Google Coalb
Colab(正式名称「Colaboratory」)は、ブラウザ上で Python を記述・実行できるサービスです。Colabには、以下のようなメリットがあります。
- 環境構築が不要
- GPU への無料アクセス
- 簡単に共有
Colab は、学生からデータ サイエンティスト、AI リサーチャーまで、皆さんの作業を効率化します。
まとめ
今回は、機械学習のアルゴリズムについて解説しました。アルゴリズムごとの違いについても説明をしましたが、機械学習について理解を深めるためには、実際に自分で機械学習を実行してみるのが1番です。
Google Colabを使えば、PCブラウザから誰でもPythonで書かれた機械学習のコードを実行できるので、実演記事を参考にしつつ、是非チャレンジしてみてください。



























