

株式会社レアゾン・ホールディングスは、世界最高レベルの高精度日本語音声認識モデル、および世界最大19,000時間の日本語音声コーパス※1「ReazonSpeech(レアゾンスピーチ)」を公開しました。
ReazonSpeechとは
「ReazonSpeech」は、レアゾン・ヒューマンインタラクション研究所が開発した高精度な音声認識モデルを中心とするプロダクト群で、それぞれ以下のような特徴があります。
- ReazonSpeech音声認識モデル:OpenAI Whisper※2に匹敵する高精度な日本語音声認識モデル。商用利用可能
- ReazonSpeechコーパス作成ツール:TV録画データなどから音声コーパスを自動抽出するソフトウェアツール。商用利用可能
- ReazonSpeech音声コーパス:世界最大19,000時間の高品質な日本語音声認識モデル学習用コーパス
いずれも無償で公開
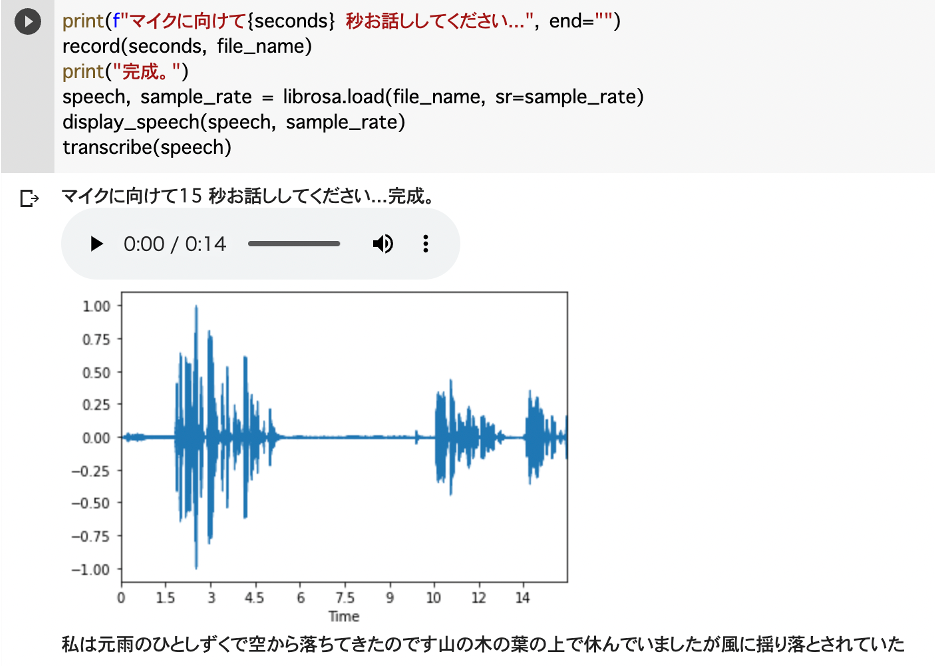
出典:レアゾンホールディングス ReazonSpeech音声認識モデルの実行例
RezonSpeechの開発の背景
近年、深層学習を用いた音声認識技術は飛躍的に精度が向上し、スマートフォンなどを通して多くの人が音声認識技術を利用できるようになりました。今後さらに技術が普及して、あらゆる端末や社会の様々な場面で音声認識技術を使えるようになれば、業務上で必要不可欠なコミュニケーションの質を高めたり、業務効率や生産性の改善に貢献することが期待できます。
また、深層学習を用いた音声認識では、高精度な音声認識モデルを得るために、音声コーパスが大量に揃っていることが必要不可欠です。誰もが自由に使える形で大規模な音声コーパスが公開されれば、音声認識技術の向上に大きな影響を与えることができます。
英語では音声コーパスが多数公開されていますが、日本語では商用利用を含めても利用可能なコーパスの量が少なく、日本語における音声認識技術の発展と普及を妨げる大きな要因となっています。
ReazonSpeechの方式
「ReezonSpeech」では、ワンセグ放送の録画データから音声コーパスを自動抽出しています。録画データから音声コーパスを構築するためには、発話単位で音声と字幕テキストを対応付ける処理(以下、アラインメント処理)が必要になり、大規模なデータに対して手動でアラインメント処理を行うと膨大なコストがかかってしまいます。また、既存の音声認識モデルを利用すれば、アラインメント処理を自動化することができますが、その結果として得られた音声コーパスは、元の音声認識モデルやその学習に用いた音声コーパスの精度の影響を受けてしまいます。
そこで「ReazonSpeech」では、最初に小規模ではあるものの自由なライセンスで利用可能な「Mozilla Common Voice」という音声コーパスから構築した音声認識モデルでアラインメント処理を行い、そこで得られた音声コーパスを元にして再度アラインメント処理を実行する、という過程を何回も重ねることによって少しずつ音声コーパスのサイズを増やしました。現在の音声コーパスサイズは19,000時間ですが、今後さらに規模を拡大する予定です。
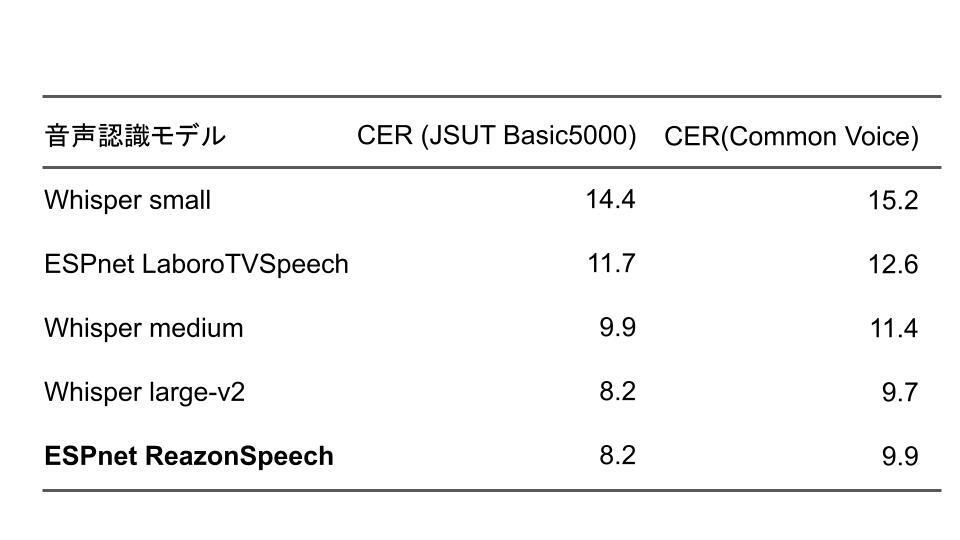
出典:レアゾン・ホールディングス CER音声認識精度の比較(CER Character Error Rate 小さいほど良い)



























