

近年、「教師なし学習」、「クラスタリング」といった言葉をAI関連で耳にされる方も多いのではないでしょうか?
しかし、「教師なし学習って何だ?」、「AIに学習方法の違いなんてあるの?」、「クラスタリングって聞いたことあるけど何?」という方もいらっしゃるでしょう。
そんな方々の声に応えるべく、今回は教師なし学習とクラスタリングについて具体例とプログラムのコードを交えながら解説をしたいと思います!
【この記事でわかること】 ※クリックすると見出しにジャンプします
|
目次
教師なし学習
まずは、「教師なし学習」とは何か、について解説します。
「教師なし学習」とは、AIに対し、人間が正解例を教えず、自身が特定かつ膨大なデータから「データの特徴、分析、定義」を発見する学習方法であり、それに基づいたアプローチを行う際に用いられる手法のことを指します。
「教師あり学習」と「教師なし学習」の違い
次に、「教師あり学習」と「教師なし学習」の違いについて解説します。
機械学習は大きく分けて「教師あり学習」と「教師なし学習」によって行えることが異なります。
「教師あり学習」は特定の課題に対する「問題と正解が一つ」になったデータを学習させ、それに基づいてアプローチする際に用いられる手法のことです。
本番前に学習させる「トレーニングデータ」や、AIが学習に用いるデータ全般を指す「教師データ」などの“正解となる学習データ”を利用し、「正解・不正解」が明確に得られる問題解決に利用されます。
具体的には、統計学の「回帰」、「分類」が該当します。
回帰は主に「売り上げ予測」、「人工予測」、「需要予測」、「不正検知」といった事例に利用され、分類は「故障診断」、「画像分類」、「顧客維持」といった事例に活用されています。
一方で、「教師なし学習」は先述の通りで、統計学の「クラスタリング」がこれに該当し、事前情報なしに、データの特徴を分析し、それらからグルーピングを自動的に行うことが可能です。
主に「レコメンド」、「顧客セグメンテーション」、「ターゲットマーケティング」といった事例に活用されています。
上記のことから “「教師あり学習」と「教師なし学習」の違い” はその学習に用いるデータが「正解」となるデータであるかないかによるものであり、これにより活用のされ方が変わることが分かったかと思います。
| 学習方法 | 該当する手法 | 特徴 | 活用事例 |
| 教師あり学習 | 回帰 |
|
|
| 分類 |
|
|
|
| 教師なし学習 | クラスタリング |
|
|
クラスタリングについて
では、具体的に「クラスタリング」について解説していきます。
解説
“「教師あり学習」と「教師なし学習」の違い”でお話ししたように、クラスタリングは「事前情報なしに、データの特徴を分析し、それらからグルーピングを自動的に行う」という特性から「レコメンド」、「顧客セグメンテーション」、「ターゲットマーケティング」といった事例に用いられる「教師なし学習」を活用したデータの分析手法です。
「クラスタリング」は主に2種類に分けられ、「階層的クラスタリング」、「非階層的クラスタリング」があります。
「階層的クラスタリング」は「最も似ているデータ同士を順番にグルーピングする手法」のことであり、「非階層的クラスタリング」は「事前に決めたクラスタ数に則ってグルーピングする手法」のことを言います。
「クラスタリング」の種類
クラスタリングの種類は主に以下の2つです。
それぞれ解説します。
階層的クラスタリング
先程お話しした通り、「階層的クラスタリング」は「最も似ているデータ同士を順番にグルーピングする手法」です。
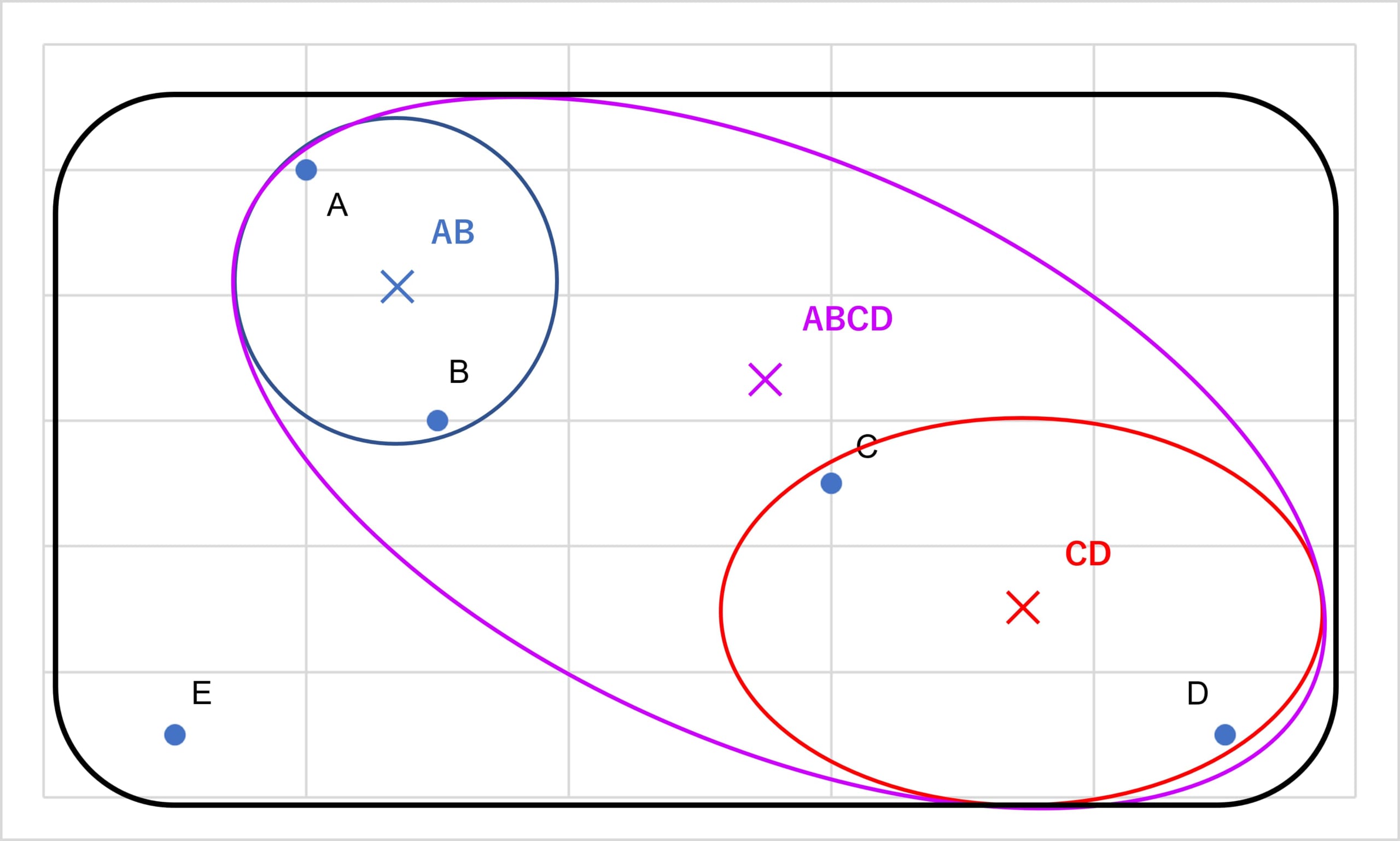
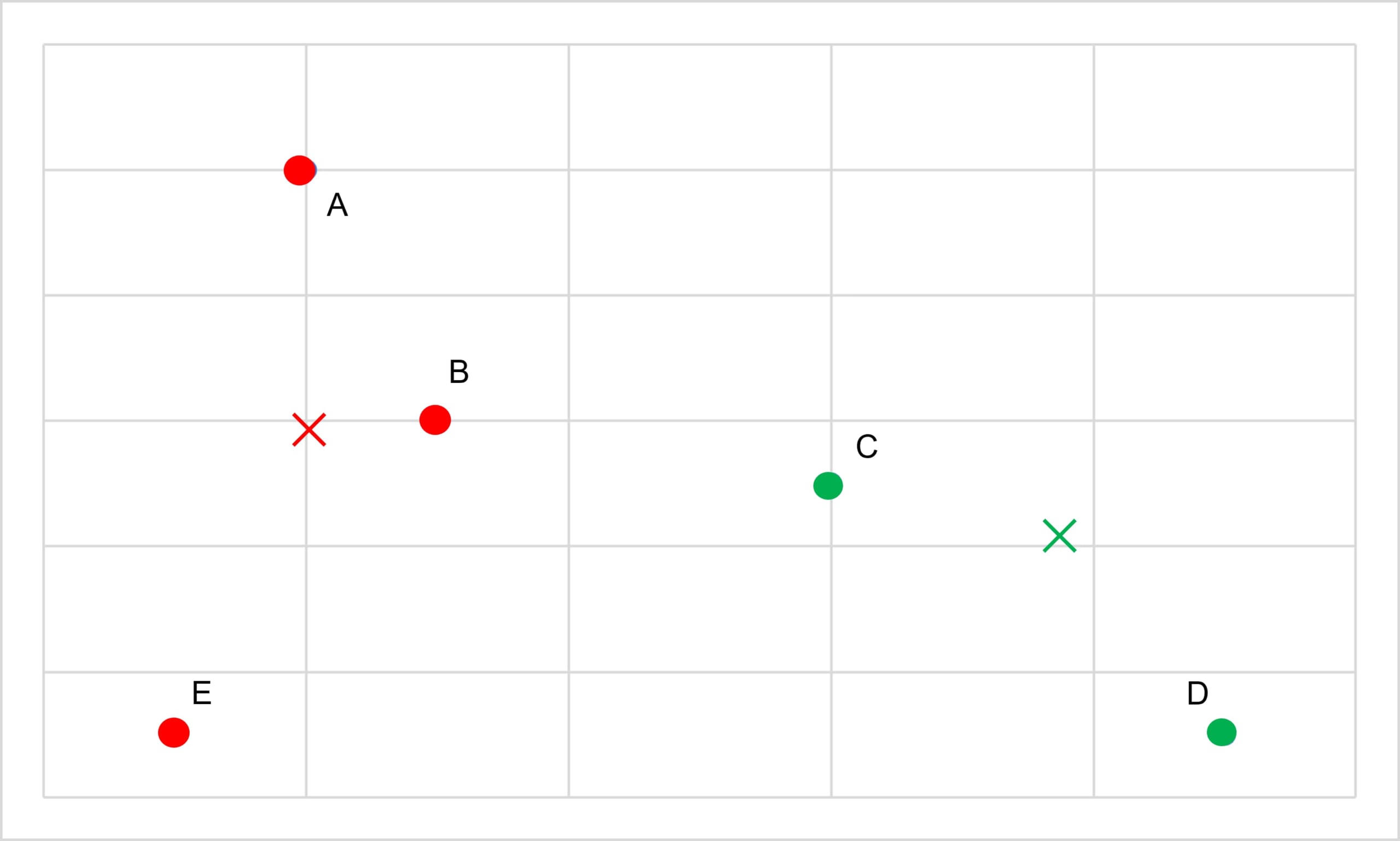
例えば、「A,B,C,D,E」の5つの要素があり、以下の図の様な状況であったとき
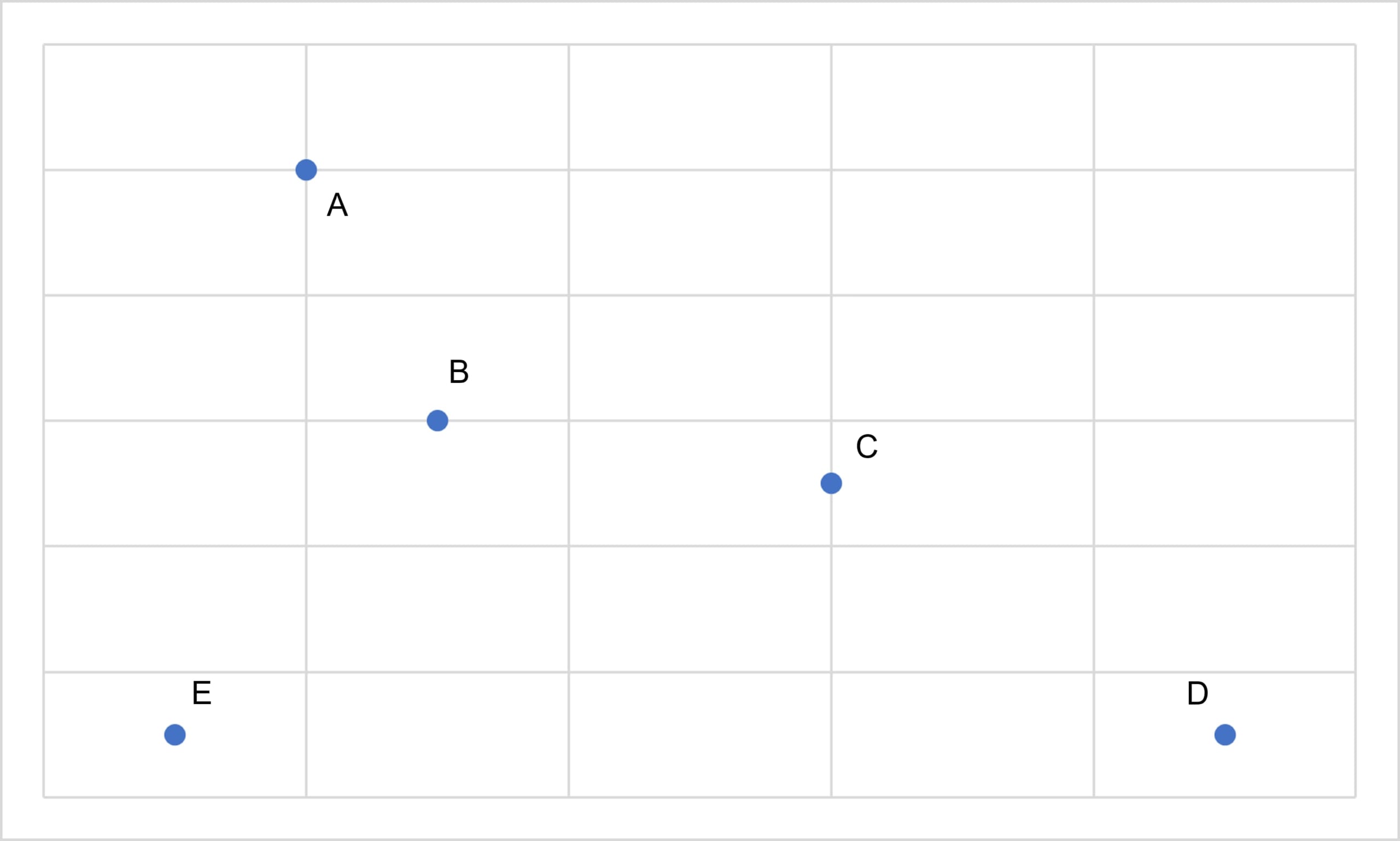
出典:AINOW編集部
まず、各要素の点で最も距離の近い組み合わせはAとBであるから、AとBを一つのクラスターとして纏めます。そして、この2点の代表点(重心 等)を求め、点ABを×として書き記します。
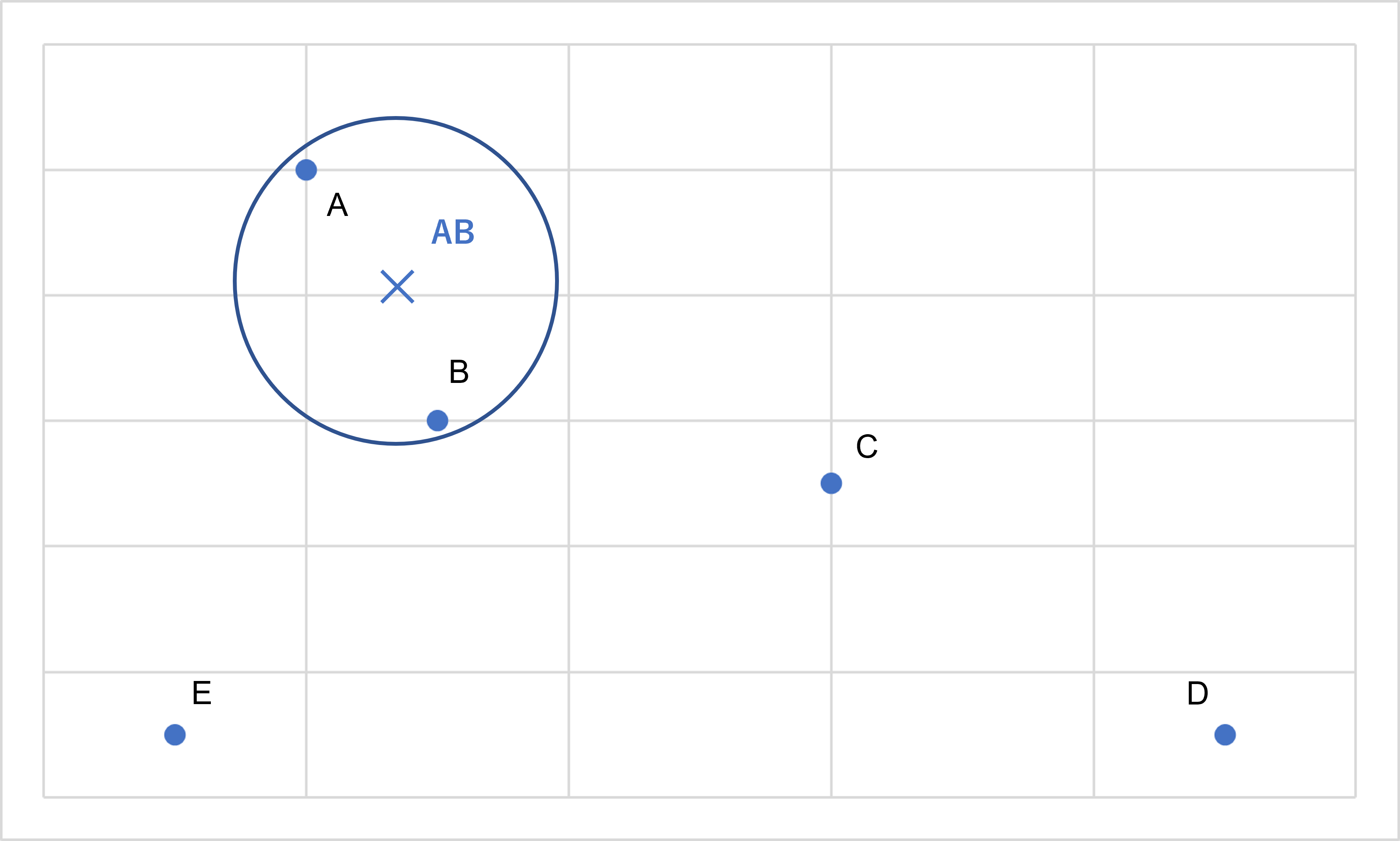
出典:AINOW編集部
次に、AB、C、D、Eの4点で、最も距離の近い組み合わせを見つけます。CとDが適しているためCとDをくくります。この代表点を点CDとします。
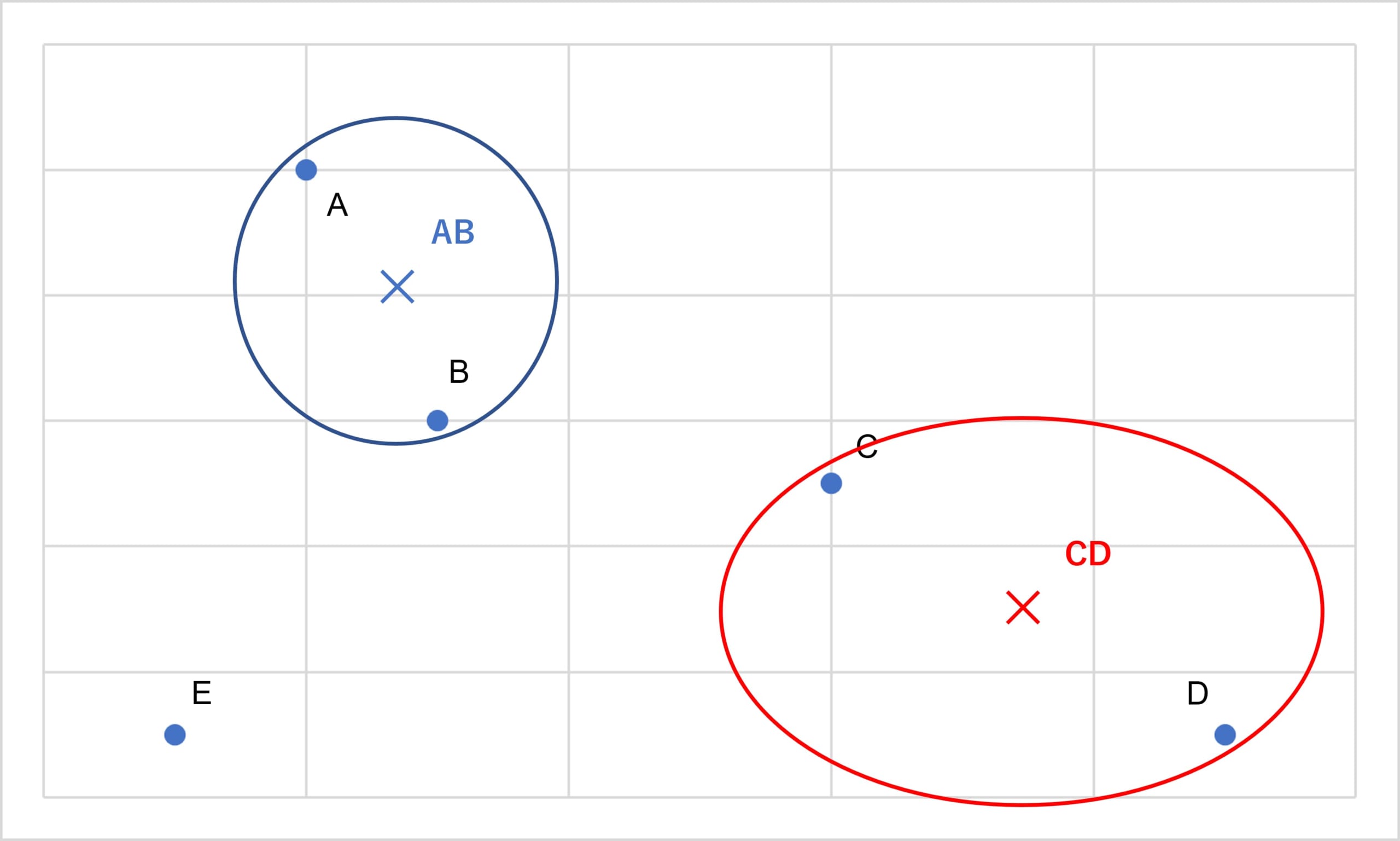
出典:AINOW編集部
そして、AB、CD、Eの3点で最も距離の近い組み合わせを見つけます。ここでは(AB)と(CD)をくくります。そして、この代表点を点ABCDとします。
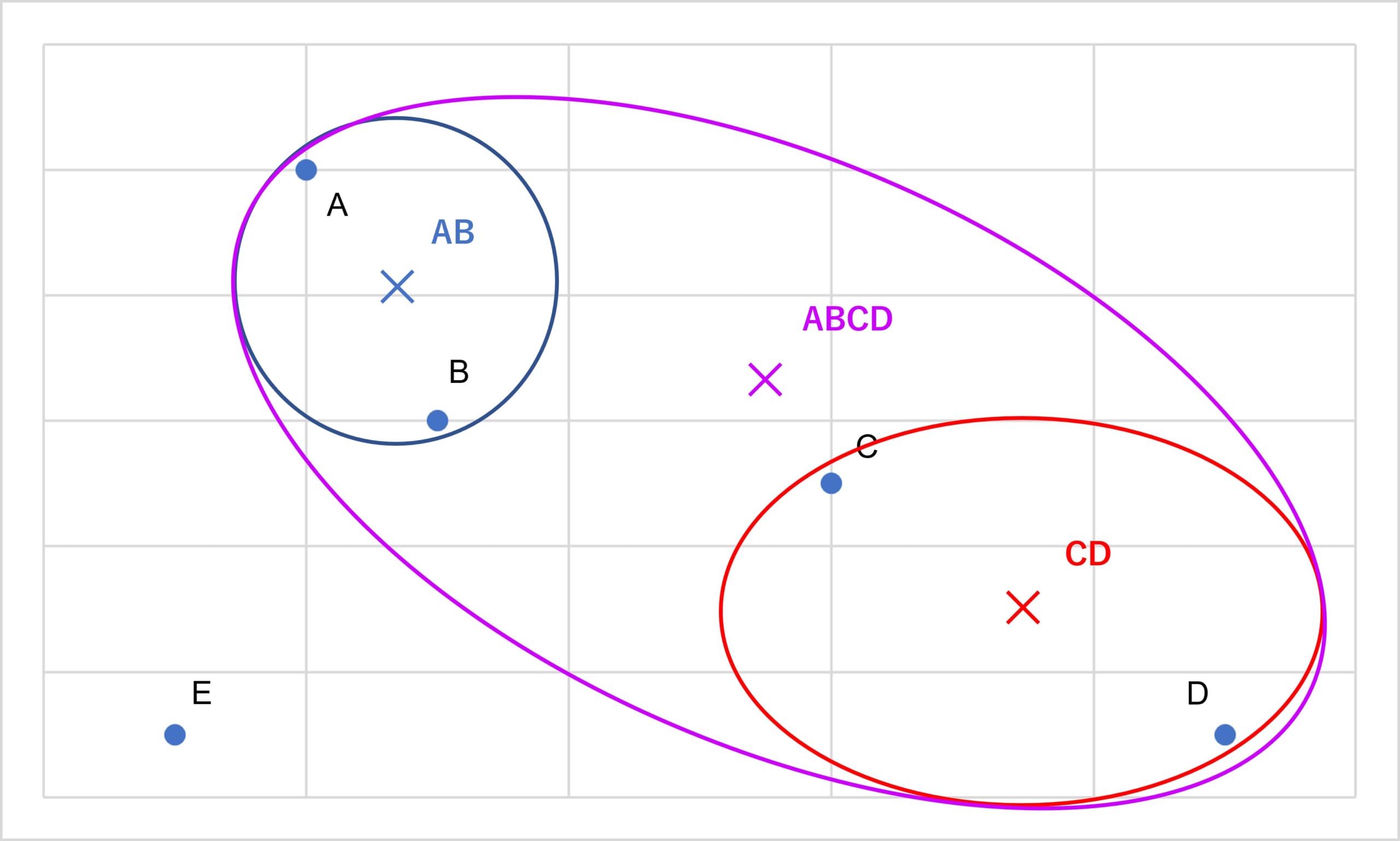
出典:AINOW編集部
最後に、Eを全体でくくり樹形図にすると以下のようになります。
出典:AINOW編集部
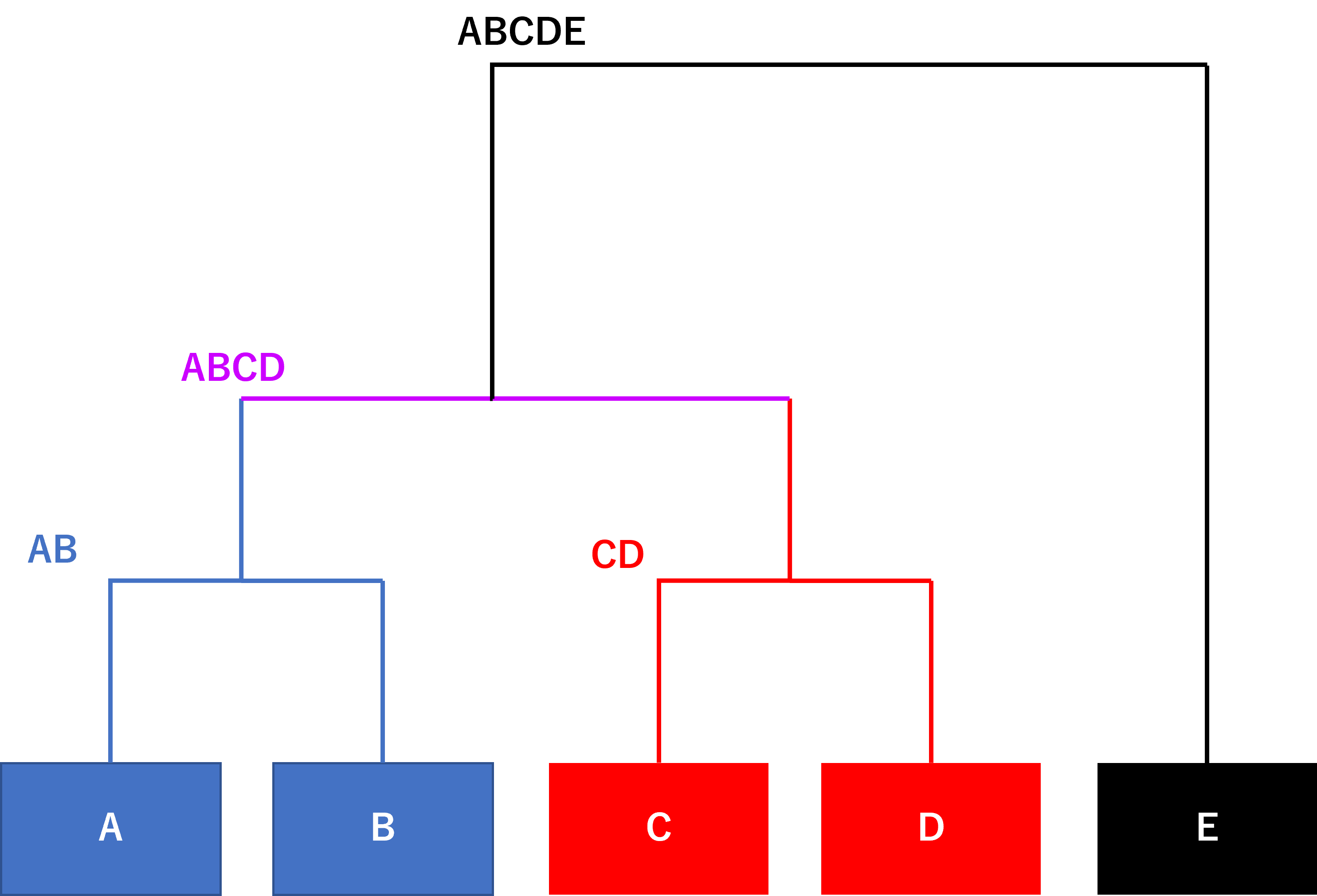
出典:AINOW編集部
このように、階層的クラスタリングは途中過程をが階層のように表示させ、最終的に樹形図で表すことができます。
階層的クラスタリングでは、主に以下、2種類の方法があります。
1.群平均法
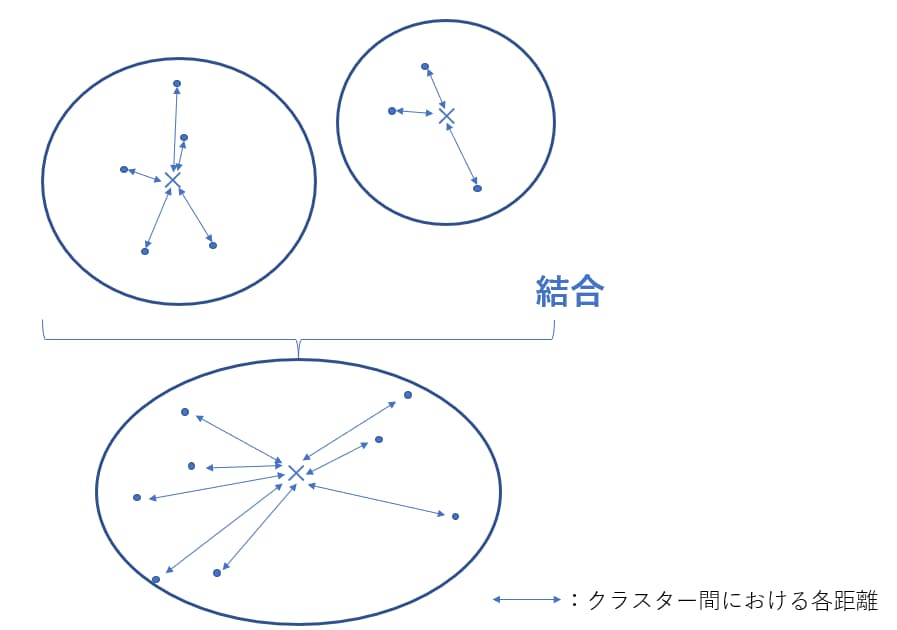
群平均法とは、データを2つの要素毎にクラスターとして構成し、それらのすべての組み合わせからなるクラスター同士の距離を求め、その平均をクラスター間の距離とする手法です。
群平均法は、クラスターが帯状となり、正しくクラスタリングが行えない「鎖効果」が、クラスター内に外れ値がある場合でも影響を受けにくいため、起こりづらく、クラスターが結合できない「拡散現象」が起きないというメリットがあります。
- 群平均法のイメージ図

出典:AINOW編集部
2.ウォード法
ウォード法とは、複数あるクラスターを結合し、それの平方和が最小となるクラスターを形成する手法です。
ウォード法は方は、分散が最小になるようにクラスタリングするため、外れ値に強く、クラスターを新たに形成するときに失われる情報量を最小に留めることが可能です。
つまり、群平均法より正確なクラスタリングが可能になります。
一方で、計算量が多く、負荷が大きいため実装できる場合が限られることも考えられます。
- ウォード法のイメージ図
出典:AINOW編集部
「階層的クラスタリング」の実践~コードを書いてみよう!~
今回は、Googleの提供している「Google Colaboratory」上で、Python言語にて実装してみます。
Pythonには、scikit-learn(サイキット・ラーン)という無料で商用利用も可能な機械学習ライブラリがあります。こちらで提供されているデータセットを利用して「クラスタリング」を行っていきましょう。
以下のステップで進めていきます。
| 目次 |
1.環境の準備
まず、「クラスタリング」を行うには環境の準備が必要です。事前準備として、以下のようにコードを書きましょう。

出典:AINOW編集部
こうすることで、機械学習を行うための環境を「Google Colaboratory」内につくることができます。
2.データの読み込み
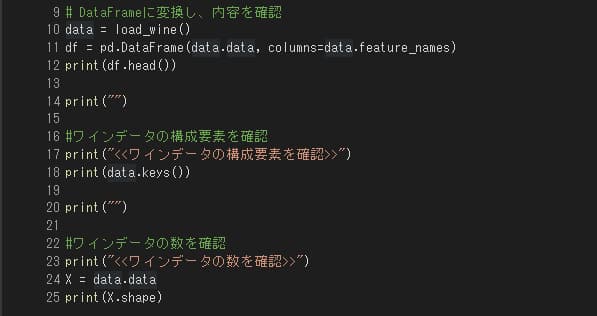
次に、「クラスタリング」に使用するデータを取り込み、内容を確認します。今回は、scikit-learnで提供されている“ワイン”のデータセットを活用します。
出典:AINOW編集部
ここで一回、ここまで書いたプログラムを実行してみましょう。
すると、以下のように結果が表示されると思います。
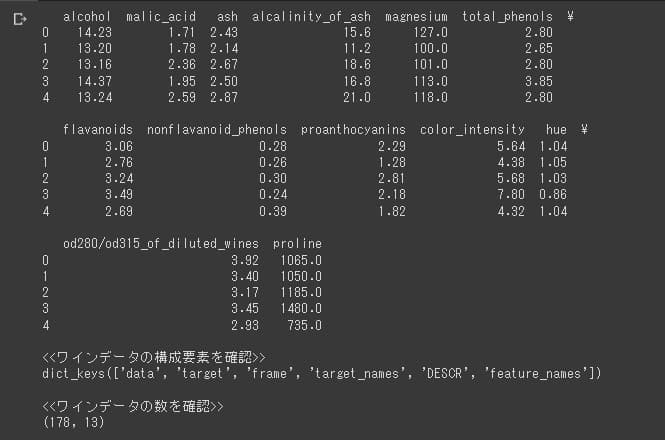
出典:AINOW編集部
上記のことから、ワインデータは「Alcohol」、「Malic acid」、「Ash」、「Alcalinity of ash」、 「Magnesium」、「Total phenols」、「Flavanoids」、「Nonflavanoid phenols」、「Proanthocyanins」、「Color intensity」、「Hue」、「OD280/OD315 of diluted wines」、「Proline」からなる「アルコール度数/色の濃さ」などの13個の特徴量を178個のワイン分集めたデータ構造をしていることが分かるかと思います。
3.データの表示・状態確認
データ構造が分かったところで、次はデータの表示を散布図にて行ってみましょう。
出典:AINOW編集部
今回は、ワインデータの「Alcohol」と「Color intensity」の観点から散布図で表示させてみます。上記の内容を実行すると以下のように散布図が表示されるかと思います。
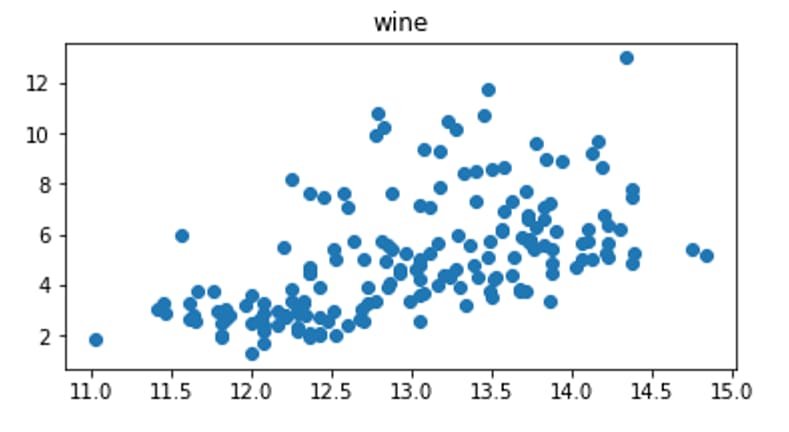
出典:AINOW編集部
4.「群平均法」と「ウォード法」のクラスタリング
最後に、階層的クラスタリングの実行コードを書きます。今回は、「SciPy」というライブラリを使って実行します。
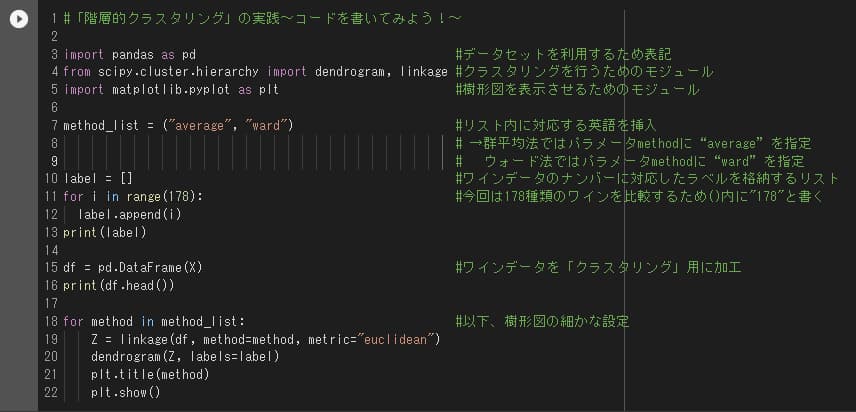
出典:AINOW編集部
では、本題の2種類のクラスタリングを実行してみましょう。
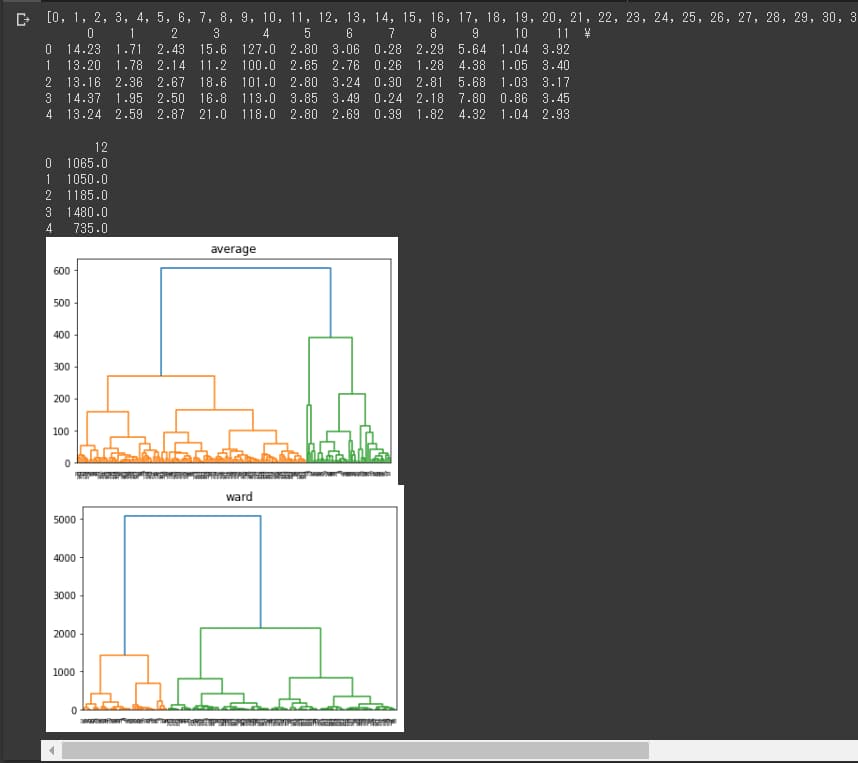
出典:AINOW編集部
“average”が群平均法、”ward”がウォード法の結果です。
各タイトルの樹形図が出力されたら終了です。
非階層的クラスタリング
“クラスタリングについて”にて解説した通り、「非階層的クラスタリング」は「事前に決めたクラスタ数に則ってグルーピングする手法」です。
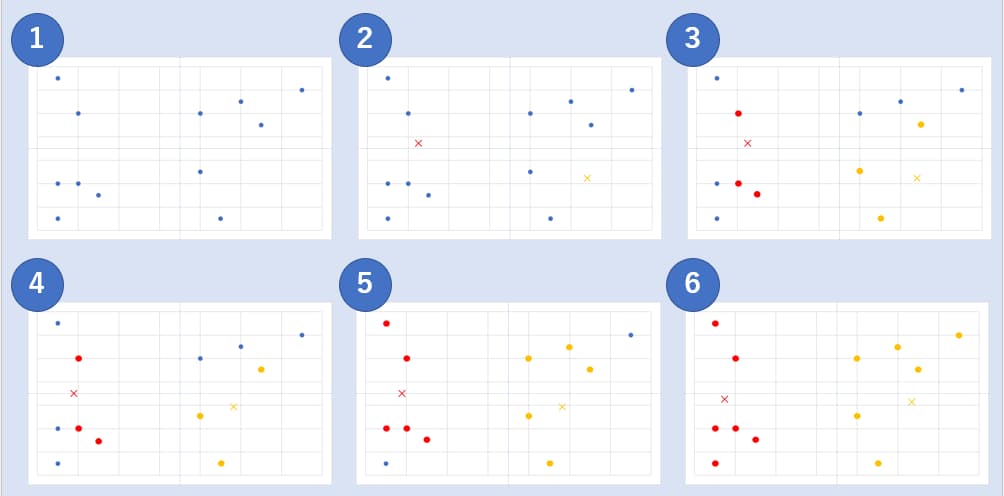
例えば、以下の図の様な状況であったときは以下のようになります。
出典:AINOW編集部
事前に決めたクラスター数とそれに基づいた重心から階層のないクラスタリングが出力されます。
出典:AINOW編集部
非階層的クラスタリングでは、主に以下の方法があります。
k-means法
まず、上記の「階層的クラスタリング」とは異なり、「非階層的クラスタリング」であるk-means法はクラスター数を決める必要があります。クラスター数の決定により、得られる結果が全く違うため、適切な値を見つけることを求められます。
このクラスター数を元に各クラスターの重心が設定され、その重心から一番近い距離に応じてデータをクラスタリングします。これを繰り返すことで類似性の高いモノ同士をまとめることができます。
その結果、従来の分類などからでは得られなかった、属性や分け方を可視化できるようになります。
- k-means法のイメージ図
出典:AINOW編集部
|
「非階層的クラスタリング」の実践~コードを書いてみよう!~
今回は、「階層的クラスタリング」と同様に「Google Colaboratory」上で、Python言語にて実装します。
こちらでも、scikit-learnにて提供されているデータセットを活用して「クラスタリング」を行っていきましょう。
| 目次 |
1.環境の準備
まず、「クラスタリング」を行うには環境の準備が必要です。事前準備として、以下のようにコードを書きましょう。

出典:AINOW編集部
こうすることで、機械学習を行うための環境を「Google Colaboratory」内につくることができます。
2.データの読み込み

出典:AINOW編集部
次に、「クラスタリング」に使用するデータを取り込みます。今回は、scikit-learnで提供されている“ワイン”のデータセットを活用します。
3.「k-means法」のクラスタリング
最後に、階層的クラスタリングの実行コードを書きます。
今回は、scikit-learnの「KMeansクラス」を使って実行します。

出典:AINOW編集部
コードを書き終えたら、クラスタリングを実行してみましょう。
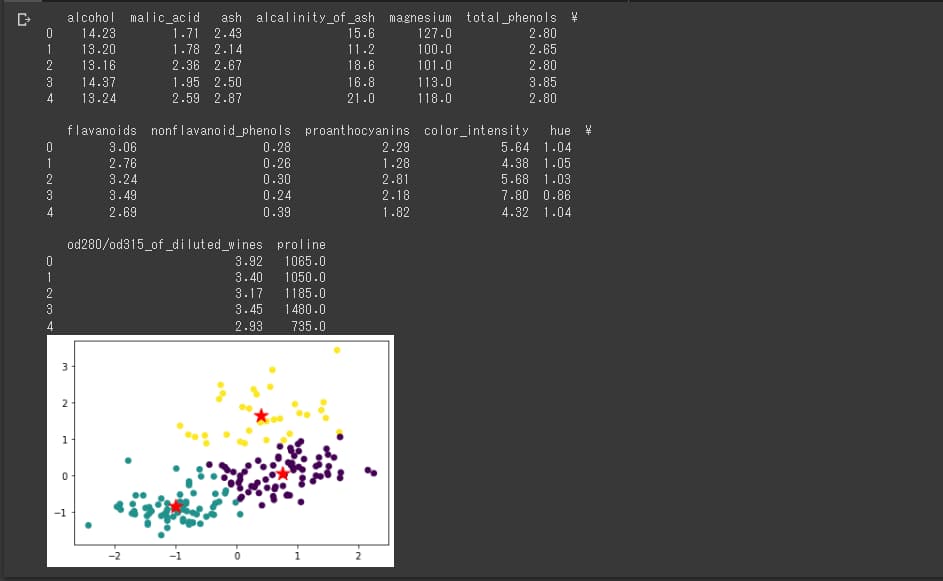
出典:AINOW編集部
上記の星印が最終的な各クラスターの重心の位置を表しており、黄色、緑色、紫色の3クラスに分かれた結果が出力されています。
これが出力されれば終了です。
「クラスタリング」の活用例
最後に、「クラスタリング」の活用例についてお話しします。
それぞれ解説します。
1.テキストマイニングツール
こちらは、「クラスタリング」技術を用いたテキストマイニングツールを活用した例です。テキストマイニングツールでは、文字データから筆者の感情や声などを収集し分析することができます。
- SNS分析
SNSや口コミサイトなどの投稿から、サイトの利用者、商品購入者のコメント、意見を集め、ユーザーに応じた効果的なアプローチに役立てることが可能です。
- アンケート分析
テキストマイニングにより、解答の自由回答欄の内容もデータ分析をすることが可能になます。これにより、より詳細に情報を分析できます。
2.テキストデータの管理・仕分け

出典:https://annotator.ousia.jp/
こちらでは、テキストマイニングにより、テキストデータの仕分けを自動化するツール「SMART ANNOTATOR(スマートアノテーター)」を紹介します。
デスクの面倒なデータ整理、チャットボットの運営、ユーザーサポート管理における質問内容の分類、アンケートや口コミの可視化・仕分けが可能です。
3.CT画像のAIによる解析手法開発

出典:https://www.juntendo.ac.jp/news/20200928-01.html
こちらは、順天堂大学が日本医学放射線学会所属施設の研究代表機関として、国立大学法人東海国立大学機構 名古屋大学、国立情報学研究所などと共同で、新型コロナウイルス(COVID-19)肺炎のCT画像をAIを用いた「クラスタリング」により解析する手法を開発した事例です。胸部CT画像を専用のAIでスキャンし、肺の状態を判断することができます。これにより、症例の識別が、令和2年8月時点で83.3%可能になりました。
4.音楽の分析
近年では、ビッグデータの活用として音声の分析にクラスタリングを用いるケースがあります。膨大な音声データをクラスタリングし類似性の高い音声、音楽などを抽出することが可能です。目的に応じ、効率的に仕分けることが期待されます。
また、ニューラルネットワークを使用した生成モデルと組み合わせることで、AIによる音楽の自動生成に役立っている一面もあります。
- SOUNDRAW
出典:https://soundraw.io/ja
- MuseNet
出典:https://openai.com/blog/musenet/
5.画像処理
画像のグルーピングだけでなく、画像処理にも一役買っています。画像の減色処理を類似色同士で1つのグループにまとめ、1色で表すことにより、ファイルサイズの削減を実現します。
これにより、画像分類における次元削減に利用することがあります。
まとめ
いかがだったでしょうか?
今回は「教師なし学習」と「クラスタリング」について、その活用事例とプログラムのコードを含めて解説いたしました。
「クラスタリング」は「教師なし学習」に分類される機械学習の手法であり、「階層的クラスタリング」と「非階層的クラスタリング」の2種類あることが分かったかと思います。そして、これらは活用する目的によって向き・不向きがあり、適した手法を選ぶ必要がありました。
今回の記事が皆様のお役に立てれば幸いです!
最後までお付き合い頂きありがとうございました。



























