人工知能には数千~数万件のデータが必要と思われがち。。
しかし、「KIBIT」なら数十件のデータでも始められる!
FRONTEOの人工知能「KIBIT」を使った場合、解析にどのような特徴があるかの、その仕組みやプロセスを見ながら、人工知能活用の方向性を考えてみましょう。
目次
文書の山から「少なく、軽く、精度高く」情報を発見
KIBITは、機械学習の一種で、FRONTEOが独自に開発した「Landscaping(ランドスケイピング)」というアルゴリズムでテキストの解析を行っています。KIBITの開発時に目指したのは「少なく、軽く、精度高く」です。
「少なく」は学習するデータの量です。いくら優秀でも、データの収集や学習に1年もかかっていたら、実践的、実用的な人工知能とは言えません。また、解析に高性能のプロセッサが必要で、利用コストが大きくなったり、環境の構築に手間がかかってしまうと、これもまた実践的、実用的とは言えません。
「見つけるべきか否か」の学習が速さと精度を出す
次に「精度」を出すためには、人工知能にデータを与え、学習させることが必要です。KIBITでは解析の初期の段階の学習フェーズにおいて、価値を持っていると思う情報は「見つけたい」、持っていない情報は「見つけなくてよい」と振り分けて学習させます。この振り分けがKIBITの特徴であり、少ない学習で速さと精度を出すことができるのです。
特徴的なのは「キーワードを選ぶ」のではなく、文書ごと、例えばA4の紙1枚やメール1通の単位で振り分けを行います。何故なら、KIBITは単語だけでなく、文章で使われている文字の構成、つまり文脈全体を見ているからです。
意味ではなく、語句や言葉の連なりから、類似性を見つけ出す
では、実際にKIBITが解析を行うプロセスを見てみましょう。
以下は、企業の不正行為を発見する調査で、企業同士が「談合」しようとする証拠を探す時の例です〈図1〉。
談合の前には、しばしば「密談」が行われます。その密談の予兆を見つけるには、以下のようなメールの文章を「見つけたい」か「見つけなくてよい」に振り分けて、KIBITに教えます。

図1:談合の証拠を探す時のメール例
赤い縦の線は、文章を最小単位で区切る形態素解析という、自然言語処理を行う際に行われる、最初のプロセスです。この「見つけたい」と「見つけなくてよい」を比べると、一見、両方のメール文に大きな違いは無さそうですが、KIBITは瞬時に違いを見つけます。例えば、「居酒屋」や「飲み」は両方の文章にありますが、「個室」や「前回から」、「時間も経って」は、前者にしかありません。
KIBITは「見つけたい」にある言葉や文章を重視して高い点数をつけ、「見つけなくてよい」にある言葉や両方にあるものには低い点数をつけます。Landscapingの計算式に基づいた点数の高低による重みの例は、下記のようになります〈図2〉。
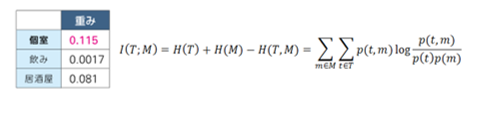
図2:個室、飲み、居酒屋で比較した重みの違いと計算式(一部)
KIBITは、文章の中にある「見つけたい」「見つけなくてよい」の多次元の組み合わせを学習した後、与えられた大量のデータを判別する解析を行います〈図3〉。
例えば、A4サイズの紙を1万枚積み上げると、約1メートルの高さになります。これを人の目で1枚ずつ探していくと膨大な時間がかかり、また、大勢の人で手分けすると漏れや間違いが起こるでしょう。
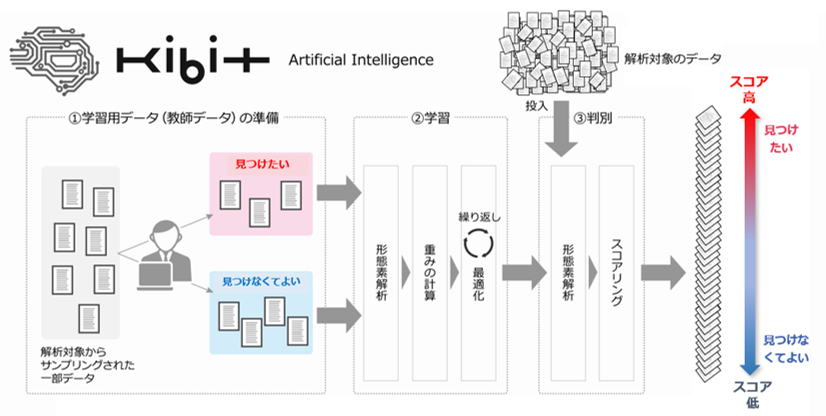
図3:KIBITの解析の流れ
KIBITに「見つけたい」「見つけなくてよい」文書データを学習させてテキストデータ解析を行った場合、1万枚の解析が約3分半で完了します。解析結果は「見つけたい」と学習した文章に似ている順番にスコアをつけて並べ替えられ、これまでバラバラだった大量の文書が「見つけたい」優先度の高い順に並べ替えられるようになります。
「見つけたい」教師データは、人の経験や感覚、または過去に起こった事実
解析の精度を出す際に最も重要なのは、「見つけたい」とKIBITに学習させる教師データです。KIBITの活用例では、様々な分野の専門家や経験者が「このメールがあやしい」、「こういう回答はセールスのチャンス」などの経験や感覚、いわゆる暗黙知を元にメールや日報、お客様の声などの文書を選ぶだけで、「見つけたい」教師データとなります。
また、専門家のような知見がなくても、過去に「見つけたい」事実が起きた時の文書があれば、それも立派な教師データです。この場合もキーワードではなく、文書をまるごと教えることで、KIBITが言葉の連なりを分析し、特徴を捉えてくれます。そして、人が気づかなかった「見つけたい」事柄をKIBITが浮かび上がらせることができます。
人工知能の学習は目的や観点が明確な方が効果的です。与える教師データは「多ければ多いほど精度が高くなる」と思う人もいると思いますが、実は、データの量が多すぎたり、余計な情報が入っていると、却って精度は下がってしまいます。「見つけたい」観点に基づいた記録や過去に起こった事実に絞って学習させることが、精度を高めるポイントとなります。

図4:KIBITの活用領域
このような仕組みを使って、KIBITは〈図4〉の例で活用されています。
人間では難しい、網羅的なデータのチェックと、言葉の意味と行動のギャップを埋める
あなたの会社で「人の目や耳で大量の記録をチェック」している業務はありませんか?
KIBITを用いることで、これまで一部しかチェックできなかった記録を網羅的にチェックすることができます。
また、人間は同じことを伝える場合でも、その言葉の使い方や表現は様々で、「キーワード」をいくつか入れるだけでは「見つけたいもの」を抽出できないことがあります。
一見、何の変哲もない言葉の連なりでも、KIBITに、観点や事実を教師データとして与えることで、人の行動を発見する”センサー”として使うことができます。
例えば、離職を悩んでいる人に上司が「大丈夫ですか?」と尋ねても、多くの人はすぐに「辞めたい」とは言わず、「大丈夫です」と答えるでしょう。KIBITなら、過去に離職してしまった人の面接時の記録から特徴を掴み、言葉の意味とは異なる人の行動を見つけ出すことができます。このようにKIBITは、大量のデータ解析と見つけ出す精度の「量と質」の両方を提供することができます。
人工知能を活用するイメージが少し湧いてきたでしょうか?
身近にあるテキストデータだからこそ、すぐに手をつけられる人工知能「KIBIT」。さらに解析の言語は、日本語だけでなく、英語、中国語、韓国語にも対応し、ビジネスソリューションでの活用は国内だけでなく、海外にも広がっています。
あなたの持っているテキストデータと「見つけたい」観点をKIBITに入れてみてください。