

※この記事は、株式会社ChillStackと三井物産セキュアディレクション株式会社の共同研究組織・セキュアAI研究所による寄稿です。
本連載は「AI*1セキュリティ超入門」と題し、AIセキュリティに関する話題を幅広く・分かり易く取り上げていきます。本連載を読むことで、AIセキュリティの全体像が俯瞰できるようになるでしょう。
本コラムでは、画像分類や音声認識など、通常は人間の知能を必要とする作業を行うことができるコンピュータシステム、とりわけ機械学習を使用して作成されるシステム全般を「AI」と呼称することにします。
目次
連載一覧
「AIセキュリティ超入門」は全8回のコラムで構成されています。
- 第1回:イントロダクション – AIをとりまく環境とセキュリティ –
- 第2回:AIを騙す攻撃 – 敵対的サンプル –
- 第3回:AIを乗っ取る攻撃 – 学習データ汚染 –
- 第4回:AIのプライバシー侵害 – メンバーシップ推論 –
- 第5回:AIの推論ロジックを改ざんする攻撃 – ノード注入 –
- 第6回:AIシステムへの侵入 – 機械学習フレームワークの悪用 –
- 第7回:AIの身辺調査 – AIに対するOSINT –
- 第8回:セキュアなAIを開発するには? – 国内外のガイドライン –
第1回〜第3回は公開済みです。ご興味がございましたら読んでいただけると幸いです。
本コラムの概要
本コラムは第4回「AIのプライバシー侵害 – メンバーシップ推論 –」です。
本コラムでは、攻撃者が攻撃対象のAI(以下、標的AI)に正常な入力データを与え、標的AIから応答された分類結果を観察することで、入力したデータが標的AIの学習データに含まれているか否かを推論する攻撃手法である「メンバーシップ推論攻撃(Membership Inference Attacks)」を取り上げます。
仮に標的AIが顔情報や医療情報、ライフスタイルに関する情報といった機微情報を含むデータを学習していた場合、メンバーシップ推論が行われることで、情報漏えいやプライバシー侵害が発生することになります。
そこで本コラムでは、標的AIの学習データを推論するメンバーシップ推論攻撃のメカニズムと防御手法の現状について纏めていきます。
AIにおけるプライバシー侵害とは
AIが学習したデータが推論された場合、様々なプライバシー侵害が発生しますが、その深刻さは学習データの性質によって異なります。以下に幾つかの例を挙げます。
例1)顔認識を含む物体認識システム
- 人物の「顔画像」を学習している。
- 人物の「全体像・部分像(身体の一部)」を学習している。
顔認識を含む物体認識システムを開発する際は、様々な人物の顔画像や身体全体が写った画像などを学習データとして使用する場合があります。
仮にシステムが何らかの攻撃を受けて学習データが漏えいした場合、個人が特定される可能性があります。
例2)病理診断システム
患者の「病歴・レントゲン写真」を学習している。
患者の「生活習慣に関する情報」を学習している。
病理診断システムを開発する際は、様々な患者の病歴に関する情報や生活習慣に関するアンケート情報などを学習データとして使用する場合があります。
仮にシステムが何らかの攻撃を受けて学習データが漏えいした場合、患者の病歴や生活習慣に関する情報などを基に、患者の個人情報が特定される可能性があります。
例3)融資における与信システム
- 顧客の「クレジット・ローンの契約内容」を学習している。
- 顧客の「ローンの返済状況」を学習している。
金融機関における与信システムを開発する際は、様々な顧客のクレジットまたはローンの契約内容や、ローンの返済状況などを学習データとして使用する場合があります。
仮にシステムが何らかの攻撃を受けて学習データが漏えいした場合、契約内容やローンの返済状況などから、借入を行っている顧客の個人情報が特定される可能性があります。
このように、AIは利用目的に応じたデータを学習しています。
よって、その学習データが漏えいした場合、様々な問題が生じることになります。
メンバーシップ推論攻撃の仕組み
メンバーシップ推論攻撃は、攻撃者が標的AIに任意の入力データを与え、標的AIから応答された分類結果を観察することで、入力したデータが標的AIの学習データに含まれているか否か(メンバーシップか否か)を推論する攻撃手法です。
メンバーシップ推論攻撃は標的AIへの入出力情報を観察するのみで攻撃を行えるため、ブラックボックス設定の攻撃手法です。よって、攻撃のハードルは高くはなく、現実的な脅威になる可能性があります。
それでは、標的AIの入出力情報からどのようにして学習データを推論するのでしょうか。
学習データを過学習した標的AIは、学習データに含まれる(近しい)データを推論した際、応答する「信頼スコアに偏りが生じる」ことが知られています。
そこで攻撃者は、「学習データに含まれていると思われるデータ」を標的AIに入力した場合と、「学習データに含まれていないと思われるデータ」を標的AIに入力した場合の「信頼スコアの差分」を観察することで、入力したデータが標的AIの学習データか否か、すなわち、メンバーシップであるのか否かを推論します。
以下、メンバーシップ推論攻撃の流れを見ていきましょう。
メンバーシップ推論攻撃の流れ
以下の図は、メンバーシップ推論攻撃の標的となるAI(Target Network)を表しています。
標的AIは任意の画像を入力に取り、画像の予測クラスと「信頼スコア」を応答するものとします。
標的となる画像分類器
攻撃者は標的AIが学習したデータを推論したいと考えているとします。
そこで攻撃者は、あらかじめ標的AIの学習データ分布を予測し、「学習データに含まれていると思われるデータ」と「含まれていないと思われるデータ」を用意しておきます。
以下の図は、学習データに含まれていると思われるデータを「Target-In」、含まれていないと思われるデータを「Target-Out」と記しています。そして、これらのデータをそれぞれ標的AIに入力します。
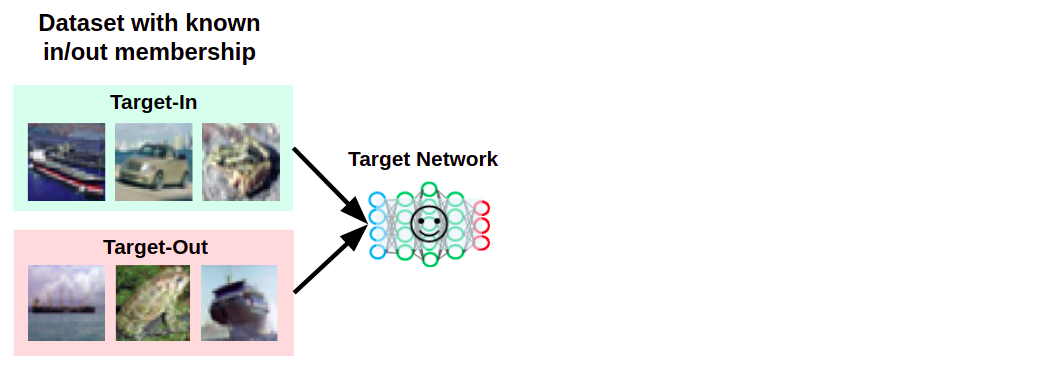
Target-InとTarget-Outを標的AIに入力している様子
すると、標的AIは以下の図のように、各入力に対して予測クラスと信頼スコアを応答します(この図では「予測クラス」は省略)。
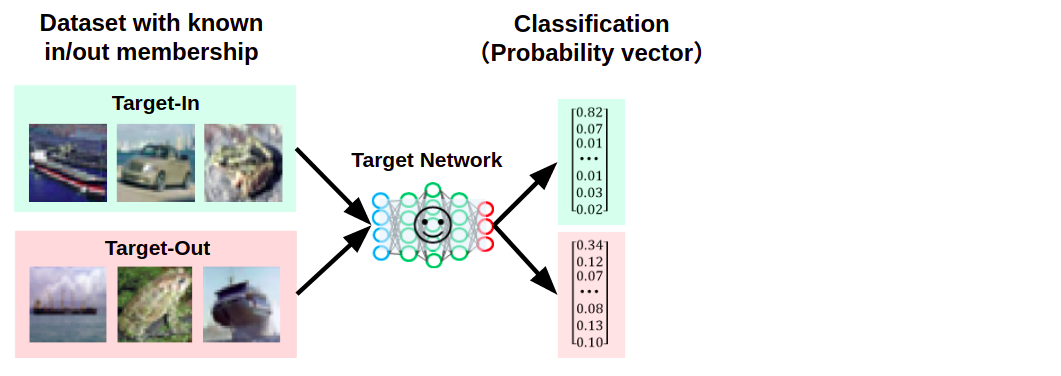
Target-InとTarget-Outに対して、異なる特徴が表れた信頼スコアを応答している様子
緑色で示した信頼スコアは「Target-In、すなわち標的AIが学習したデータに対する応答」を示していますが、ある一つのクラスに対する信頼値が「0.82」と突出し、それ以外は「0.1」以下の小さな値になっていることが分かります。
つまり、特定のクラスに過剰に反応した結果が応答されます。
一方、赤色で示した信頼スコアは「Target-Out、すなわち標的AIが学習していないデータに対する応答」を示していますが、Target-Inと比較すると信頼スコアが平準化されていることが分かります。
このように、Target-InとTarget-Outに対する信頼スコアに「異なる特徴」が表れることになります。これは、学習データを過学習したAIほど顕著に表れます。
次に、攻撃者はこれらの信頼スコアを、事前に用意した攻撃ネットワーク(Attack Network)と呼ばれる分類器に入力します。
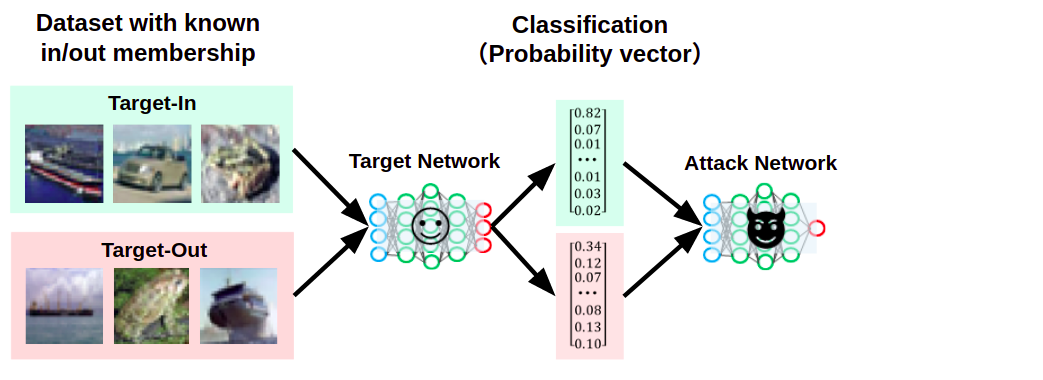
標的AIが応答した信頼スコアを攻撃ネットワークに入力している様子
攻撃ネットワークは信頼スコアを入力に取り、メンバーシップか否かを「2値分類」するように学習して作成されています。
よって、標的AIが応答したTarget-InとTarget-Outに対応する信頼スコアを攻撃ネットワークに入力することで、これをメンバーシップ(図中では「1」)またはメンバーシップではない(図中では「0」)に分類することができます。
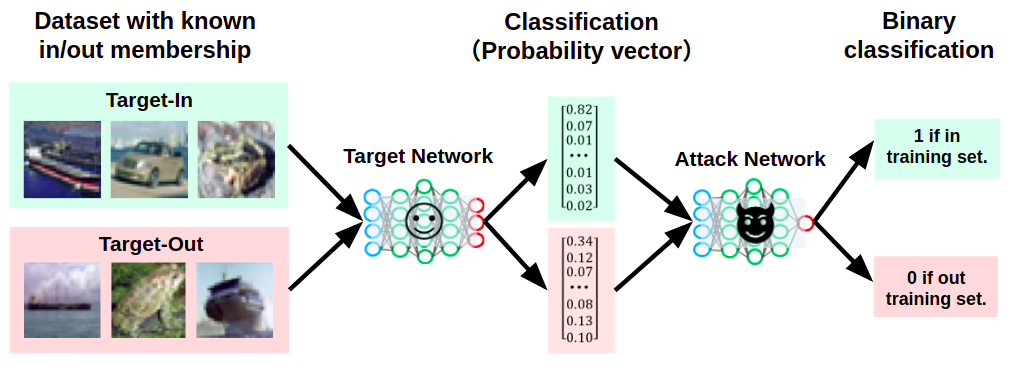
信頼スコアを基にメンバーシップを推論している様子
このように、標的AIの入出力情報のみで(ブラックボックスで)、標的AIの学習データを推論することができます。
なお、メンバーシップ推論攻撃は標的AIに対する正常アクセスと、その応答を観察するのみ実行することができるため、入力値の検証機構などで攻撃検知することは困難です。
また、攻撃者がメンバーシップ推論攻撃を過度に行わない限りは、アクセス頻度を基にした異常検知機構で攻撃を検知することも困難です。
このような特性から、メンバーシップ推論攻撃は非常に厄介な攻撃手法であると言えます。
攻撃ネットワークの作成
メンバーシップ推論攻撃は、標的AIが応答する信頼スコアを攻撃ネットワークで2値分類(メンバーシップか否か)することで実行されるため、「攻撃ネットワーク」は攻撃の要であると言えます。
ところで、攻撃者はどのようにして攻撃ネットワークを作成するのでしょうか。
攻撃ネットワークは単純な2値分類器ですが、この分類器を作成するためには、以下のような学習データを用意する必要があります。
| データ(標的AIの信頼スコア) | ラベル(メンバーシップ:1, 非メンバーシップ:0) |
| 0.76, 0.03, 0.04, …snip… , 0.02, 0.05, 0.01 | 1 |
| 0.01, 0.07, 0.01, …snip… , 0.82, 0.03, 0.02 | 1 |
| 0.01, 0.01, 0.90, …snip… , 0.01, 0.01, 0.01 | 1 |
| 0.12, 0.34, 0.07, …snip… , 0.08, 0.13, 0.10 | 0 |
| 0.10, 0.18, 0.02, …snip… , 0.03, 0.10, 0.54 | 0 |
| 0.23, 0.09, 0.11, …snip… , 0.01, 0.46, 0.03 | 0 |
「データ」が標的AIが応答する信頼スコア、「ラベル」がメンバーシップか否かを表す値です。
なお、上表では、ラベル「1」の場合は「メンバーシップ」、ラベル「0」の場合は「非メンバーシップ」としています。
この学習データを作成するためには、標的AIが「学習したデータ」と「学習していないデータ」を知る必要があります。
しかし、攻撃者はそれらを知ることはできませんし、そもそも、それを知っていたらメンバーシップ推論攻撃を行う必要もありません。
そこで、攻撃者は、標的AIを模倣した分類器を手元に作成し、これを使用して攻撃ネットワークの学習データを作成します。
この、標的AIを模倣した分類器のことをシャドウモデルと呼びます(第2回、第3回に登場したシャドウモデルと考え方は同じです)。
以下、シャドウモデルを使用して攻撃ネットワークを学習する流れを見ていきましょう。

標的AIの学習データ分布に近しいデータセットを用意している様子
あらかじめ、攻撃者は標的AIの学習データ分布をある程度予測し、近しいデータセットを用意しておきます。
そして、用意したデータをシャドウモデルの学習に使用するデータ「Shadow-In」と、学習に使用しないデータ「Shadow-Out」に分割します。
その上で、Shadow-Inのみを用いてシャドウモデルを学習します。

Shadow-Inを使用してシャドウモデルを作成(学習)した様子
次に、シャドウモデルの学習に使用したShadow-Inと、シャドウモデルの学習に使用していないShadow-Outをシャドウモデルに入力し、それぞれの信頼スコアを取得します。
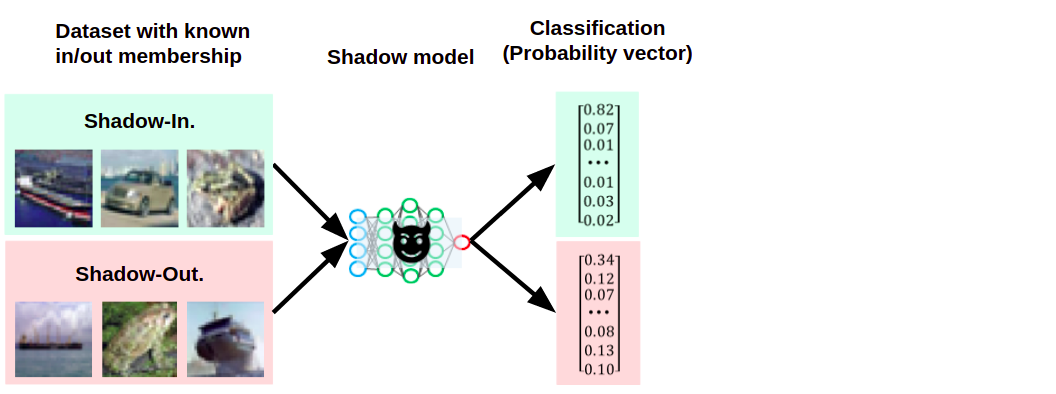
Shadow-InとShadow-Outに対するシャドウモデルの信頼スコアを取得している様子
この時、Shadow-Inに対応する信頼スコアには「1:メンバーシップである」、Shadow-Outに対応する信頼スコアには「0:メンバーシップではない」とラベリングし、攻撃ネットワークの学習データを作成します。
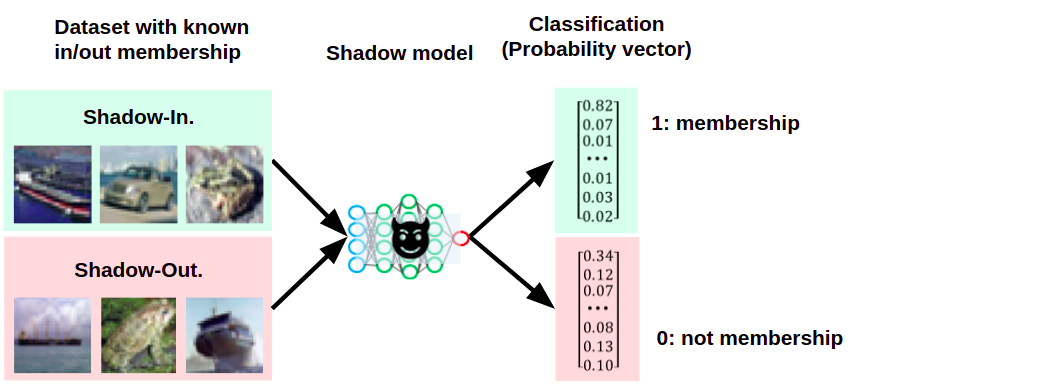
Shadow-InとShadow-Outに対する信頼スコアにラベル付けを行っている様子
そして、この学習データを用いて攻撃ネットワークを学習します。
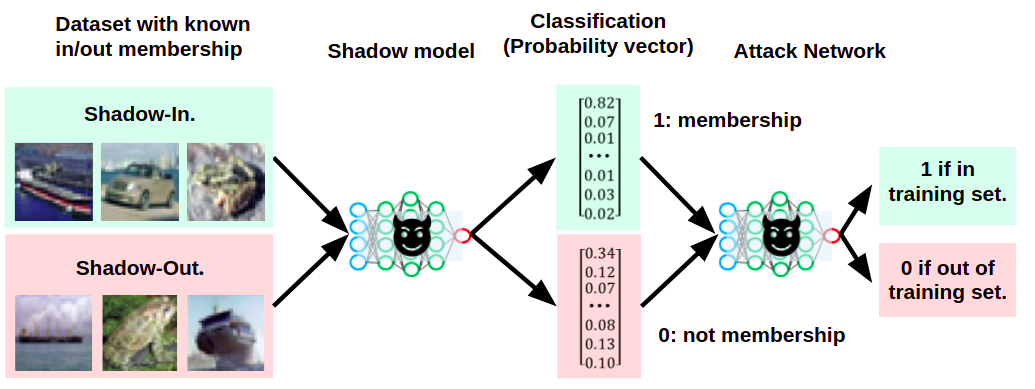
シャドウモデルを使用して攻撃ネットワークを学習している様子
このように、シャドウモデルを利用することで、標的とする画像分類器が手元にない状態でも攻撃ネットワークを作成することができ、メンバーシップ推論攻撃が可能となります。
なお、筆者らの検証では、シャドウモデルと標的AIのアーキテクチャや学習データが完全に一致していない場合でも、攻撃ネットワークを作成するための学習データを作成できることを確認しています。
本コラムでは割愛しますが、詳細を知りたい方はこちらのブログを参照いただければと思います。
メンバーシップ推論攻撃の対策
メンバーシップ推論攻撃からAIを守るための防御手法を幾つか例示します。
ここで注意が必要なのは、これから例示する防御手法を破る攻撃手法は盛んに研究されているため、単一の防御手法を用いるのではなく、複数の防御手法を組み合わせる多層防御の観点が重要になります。
本コラムでは、「応答する情報を制御」するアプローチと「分類器の頑健性を向上」させるアプローチを取り上げます。
応答する情報の制御
「応答する情報を制御」するアプローチとして考えられるのが、信頼スコアを応答しないことです。
繰り返しになりますが、メンバーシップ推論攻撃は「分類器が応答する信頼スコアを攻撃ネットワークに入力し、メンバーシップか否かを判定」する手法でした。よって、判定の拠り所となる信頼スコアを応答せずに分類結果すなわちラベルのみ応答することで、メンバーシップ推論を不能にすることができると考えられます。
しかし、分類器の要件上、信頼スコアを応答せざるを得ないケースも考えられます。
このような場合は、信頼スコアの桁数を減らして丸めることで、攻撃ネットワークの分類精度すなわちメンバーシップ推論の精度を低下させる効果が期待できます。ただし、精度が低下するものの、完全にメンバーシップ推論を防ぐことができないことに注意が必要です。
分類器の頑健性向上
「標的分類器の頑健性向上」させるアプローチとして考えられるのが、過学習の抑制です。
メンバーシップ推論は、メンバーシップか否かによって信頼スコアに偏りが生じることを拠り所としています。
それゆえに、学習データを過学習したモデルほど信頼スコアの偏りが大きくなり、メンバーシップ推論攻撃に対して脆弱になります。
そこで、分類器にDropoutを加えることや、増強した学習データを使用して学習を行うなどして分類器の頑健性を高めることで、メンバーシップ推論の影響を緩和することができます。
その他に、正則化や差分プライバシーと呼ばれる信頼スコアの偏りを軽減させる学習方法も有効であるとされています。
まとめ
本コラムではメンバーシップ推論攻撃のメカニズムと対策を紹介しました。
メンバーシップ推論攻撃は検知が難しく、仮に学習データが推論された場合、情報漏えいやプライバシー侵害を引き起こすという非常に厄介な攻撃手法です。
このため、AIの入出力情報は悪用される可能性があることを念頭に置き、「AIの頑健性向上」や「余計な情報は応答しない」という基本的な対策を徹底することが必要です。
なお、今現在もメンバーシップ推論攻撃の新たな手法は登場しています。
この数ヶ月の間に、標的AIの信頼スコアに依存せず、応答されるラベルのみで学習データを推論する手法参考文献1,2や、転移学習で作成されたAIの学習データを推論する手法参考文献3など、メンバーシップ推論攻撃は進化を続けています。
よって、常に最新の攻撃手法を知り、適切に対処し続けることが重要となります。
筆者らは今後もメンバーシップ推論攻撃の最新動向をウォッチし、可能な限りコラムやブログなどの形で分かりやすく伝えていきたいと考えています。
1:Label-Only Membership Inference Attacks
2:Sampling Attacks: Amplification of Membership Inference Attacks by Repeated Queries
3:Privacy Analysis of Deep Learning in the Wild: Membership Inference Attacks against Transfer Learning
以上で、第4回「AIのプライバシー侵害 – メンバーシップ推論 –」は終了です。
次回は、第5回「AIの推論ロジックを改ざんする攻撃 – ノード注入 -」について投稿いたします。
最後に、株式会社ChillStackと三井物産セキュアディレクション株式会社は、AIの開発・提供・利用を安全に行うための「セキュアAI開発トレーニング」を提供しています。
本トレーニングでは、本コラムで解説した攻撃手法の他、AIに対する様々な攻撃手法と対策を、座学とハンズオンを通じて理解することができます。
本トレーニングの詳細やお問い合わせにつきましては、セキュアAI開発トレーニングをご覧ください。
※本コラムの執筆者は以下の通りです。
| 高江洲 勲(三井物産セキュアディレクション株式会社) 情報処理安全確保支援士。CISSP。Webシステムに対する脆弱性診断に10年以上従事。また、AIセキュリティに着目し、機械学習アルゴリズムの脆弱性に関する研究や、機械学習を用いたセキュリティタスク自動化の研究を行っている。研究成果は、世界的に著名なハッカーカンファレンスであるBlack Hat ArsenalやDEFCON、CODE BLUE等で発表している。近年はセキュリティ・ネクストキャンプやSECCONワークショップの講師、国際的なハッカーカンファレンスであるHack In The BoxのAIセキュリティ・コンペティションで審査員を務める等、教育事業にも貢献している。 |
駒澤大学仏教学部に所属。YouTubeとK-POPにハマっています。
AIがこれから宗教とどのように関わり、仏教徒の生活に影響するのかについて興味があります。



























