

スマートフォンや家電、車にもAIが活用されています。日々のニュースでAIという単語を聞かないことは少なくなってきました。
その中で、AIがどのように発展してきたのか、AIの歴史を知りたい人も多いのではないでしょうか。
この記事はAIの歴史を時系列に沿って簡単に紹介していきます。
▼AI(人工知能)について詳しく知りたい方はこちら

目次
AI研究の歴史の全体像と年表
AIは第一次AIブームから第二次AIブームとなり、今は第三次AIブームと言われています。
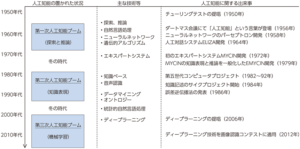
(出典)総務省「ICTの進化が雇用と働き方に及ぼす影響に関する調査研究」(平成28年)
1950年代:AIの出現
1950年代はAIが出現した時期とされています。AI(人工知能)の概念はイギリスの数学者アラン・チューリングの著書、「計算する機械と人間」(1950)で提唱されました。
この中でアラン・チューリングは「機械は考えることができるのか?」という問いを唱えました。
この時に機械が思考したかを判定する有名なテストがチューリングテストです。
チューリングテストは、AI(人工知能)が人間が行う知的活動と同等、もしくは区別がつかないほどであるか、「人との会話」によって判定するテストです。
1956年:『ダートマス会議』
AIの歴史の中で初めて「人工知能」という単語が使われたのが「ダートマス会議」です。
ダートマス会議は、当時ダートマス大学の助教授であったジョン・マッカーシー、マービン・ミンスキー、クロード・シャノン、ナザニエル・ロチェスターが発起し、1956年アメリカ合衆国ニューハンプシャー州のダートマス大学で開催された会議のことで、「人間のように考える機械」がAI(人工知能)と名付けられました。
AI(人工知能)の研究の始まりとなった会議です。
1956~1974年:第1次AIブーム~探索と推論の研究~
1956〜1974年は第一次AIブームとされています。第一次AIブームで主に研究されたのは「推論」と「探索」です。特定の問題に対して解を提示できるようになったことが第一次AIブームの要因とされています。また、自然言語処理による機械翻訳などにも注力されました。
しかし、当時のAIでは迷路の解き方や定理の照明のような単純な仮説の問題を扱うことはできず、現実社会の課題を解くことはできないことが明らかになり、冬の時代が到来しました。
主な技術
第一次AIブームで主に研究された技術は以下の5つです。
- 探索と推論
「探索」と「推論」はデータよりもアルゴリズムを重視するものです。これによってロボットが場合分けをできるようになりました。
「探索」とは、最初に与えられた状態から目的の状態に至るまでの状態の変化を場合分けを行いながら探し出すことです。
「推論」とは人間の思考の過程を、記号を使って表現してみようとする試みです。
自然言語処理の「自然言語」とは、人間が日常で使っている言語のことです。自然言語処理では、人間の言語をコンピューターに処理させます。
- ニューラルネットワーク(Neural Network)
ニューラルネットワークとは、人間の脳の仕組み(人間の脳神経系のニューロン)を模倣した数理モデル、またはパーセプトロンを複数組み合わせたものの総称です。
▶ギリア、ニューラルネットワークを自動設計しサイズを90%以上縮小可能な「Ghelia Spectre」を開発>>
- 遺伝的アルゴリズム
遺伝的アルゴリズムとは、生物の進化を模倣したもので近似解を探索するアルゴリズムです。優秀な個体を次世代へと受け継ぎ、優秀でない個体を排除するという考えに基づいています。
エキスパートシステムとは、特定の専門分野の知識をもち、専門家のように事象の推論や判断ができるようにしたコンピュータシステムのことです。専門知識のない人がエキスパートシステムを使って、専門家と同じような問題解決能力を手にできるようにする目的で開発されました。
1958:ニューラルネットワークのパーセプトロン開発
1958年にはニューラルネットワークのパーセプトロンが開発されました。
パーセプトロンとは、複数の入力値に重み付けした後、合算して一つの出力を得るという基礎的なアルゴリズムです。
入力層と出力層の二層で構成されるものを単純パーセプトロン、隠れ層を含む三層以上に多層化されているものが多層パーセプトロン(MLP)とそれぞれ呼ばれています。
このパーセプトロンは、重みを調節することで、機械学習の基本命題である「回帰」と「分類」を行うことができます。
▶機械学習の回帰とは?分類との違い・メリット・学習方法など解説!>>
1964:人工対話システムELIZA開発
1964年には人口対話システムELIZAが開発されました。
ELIZAは文章を用いて自然言語を処理し、人間と対話することができるプログラムで、SiriやアレクサなどのAIアシスタントの期限とも言われています。この技術によって、コンピュータと人間のコミュニケーションが可能になりました。
▶生活水準を向上させる!「AIアシスタント」の種類や機能、その未来とは?>>
1974~1980年:冬の時代~AIの限界~
第一次AIブームのAIは迷路の解き方や定理の証明のような単純な仮説の問題を扱うことができました。しかし、様々な要因が絡み合っているような現実社会の問題を解くことができないことが明らかとなり、AIは冬の時代を迎えました。
おもちゃの問題(トイ・プロブレム)
AIは現実的な問題を解くことができず、研究者の間でもAIに対する失望が生まれました。このとき、AIが解くことができた単純な問題は「おもちゃの問題」と呼ばれ、役に立たないものとされていました。
1980~1987年:第2次AIブーム~知識表現~
1980〜1987年は第二次AIブームとされています。1970年代に「おもちゃの問題」しか解けないことが明らかになったAIですが、1980年代なるとまた勢いを取り戻しました。
第二次AIブームでは、主に「エキスパートシステム」が注目されました。
エキスパートシステムとは、専門分野の「知識」をコンピュータに取り込み推論を行うことで、コンピュータが専門家のように振る舞うシステムのことです。
エキスパートシステムは、「おもちゃの問題」だけでなく、現実的な問題も解決できるということで脚光を浴びました。
主な技術
この時期に発展した技術は主に以下の4つです。
- 知識ベース
知識ベース(knowledge base)とは、エキスパートシステムに取り込まれた対象領域に関する知識の集合のことで、事実や常識、経験などの知識をコンピュータが解読できる形にした特殊なデータベースです。
ナレッジベースとも呼ばれています。
音声認識とは、コンピュータにより人間の話した声(音声データ)を解析し、テキストに変換する技術のことです。
▶AI音声認識ってなに?仕組みからおすすめサービスまで分かりやすく解説>>
データマイニングとは、大量のデータを統計学やパターン認識、人工知能などの分析手法を利用して、有益な知識を取り出す技術のことです。文字通り、情報(データ)から有益なものを採掘(マイニング)します。
- オントロジー
オントロジーとは、共有されている概念化の形式・明示的使用のことを指します。
1984:知識記述のサイクプロジェクト
1984年には知識記述のサイクプロジェクトが始まりました。サイクプロジェクトとは、一般常識をデータベース化し(知識ベース)、人間と同等の推論システムを構築することを目的とするプロジェクトのことです。
1986:誤差逆伝播法の発表
1986年には、誤差逆電播法が発表されました。誤差逆電播法はバックプロパゲーションとも呼ばれ、ニューラルネットワークの学習アルゴリズムの一つです。バックプロパゲーションは数理モデルであるニューラルネットワークの重みを層の数に関わらず、更新できるアルゴリズムで、ディープラーニングの主な学習手法として利用されています。
1987~1993年:冬の時代~AIの限界~
第二次AIブームは主にエキスパートシステムが研究されました、しかし、当時のコンピュータは必要な情報を自ら収集して、蓄積することはできなかったため、エキスパートシステムに必要な情報はすべて、人がコンピュータが理解できるように内容を記述する必要がありました。
世にある膨大な情報をコンピュータが理解できるように記述して用意することは困難を極めます。
このような限界から、AIは再び冬の時代を迎えました。
1993年~現在:第3次AIブーム~機械学習~
1990年代からコンピュータの性能が向上し、扱える情報量が増加しました。また、インターネットの普及によって、従来は困難だった膨大なデータの収集や管理が可能になり、ビッグデータの時代が到来したのです。
これによって知識を人間が記述する必要がなくなり、AI研究は再び盛り上がりをみせ、第三次AIブームとなります。
第三次AIブームでは膨大なデータから有益な情報を抽出し学習する機械学習のほかに、深層学習(Deep Learning)も注目されるようになりました。
▼機械学習について詳しく知りたい方はこちら

主な技術
この時期に発展した技術は主に以下の2つです。
- 統計的自然言語処理
従来型の自然言語処理では解釈の可能性の組み合わせが指数関数的に増大していき、処理が困難でした。統計的自然言語処理では、確率論的あるいは統計学的手法を使ってこの問題を解決できます。
2006:ディープラーニングの提唱
2006年にディープラーニングが提唱されました。ディープラーニングとは、知識を定義する要素をAIが自ら習得する技術のことで、これにより機械学習がより実用的なものとなりました。
▶ディープラーニングとは【初心者必読】-基礎知識からAIとの違い、導入プロセスまで細かく解説>>
▼ディープラーニングについて詳しく知りたい方はこちら

2012:ディープラーニングを画像認識に適用
2012年にはディープラーニングが画像認識に適用され、画像認識の技術が向上しました。
画像認識はディープラーニングが適用されたことで、顔認証システムや欠陥の検査など、生活の身近な場面で利用される重要な技術となりました。
▶画像認識とは|機能・事例・仕組み・導入方法など徹底解説>>
第3次AIブームは終わるのか?~現在のAIの課題~
過去の2回のブームでは、AIが実現できる技術的な限界よりも社会がAIに対して期待する水準が上回っており、その乖離が明らかになることでブームが終了したと考えられています。
AIのブラックボックス問題
AIはコンピュータが膨大なデータを学習し、自律的に答えを出すという特性上その判断に至るプロセスが人間には分かりません。これをAIのブラックボックス問題と呼んでいます。
例えば、自動運転車が事故を起こした場合に、なぜAIがそのような事故を起こしたのか、AIがその判断に至るまでのプロセスが分からないため、原因が不明のままでプログラムを修正することができないのです。
AIのブラックボックス問題がAIの普及、発展の障壁になることは間違いなく、説明可能なAIが求められています。
▶AIの問題点まとめ|雇用の減少・過失責任の在処・軍事利用など解説>>
現在のAIにできること
AIは特化型人工知能と汎用人工知能に分けられています。現在のAIはすべて特化型人工知能です。
そして汎用人工知能とは、ドラえもんのように様々なことが出来てしまう人工知能を指します。特化型人工知能が特定の課題のみに対応できるのに対し、汎用人工知能は自ら学習を行い、その経験と能力の応用から様々な課題に対応することができます。
しかし、汎用人工知能の開発は非常に難しく未だ実現できていません。
現在のAIである特化型人工知能は人間としての感性や思考回路は持っておらず、「弱いAI」とも呼ばれます。
この限定された課題を解決する上で利用されているのが、音声認識、画像認識、自然言語処理といった技術です。現在、AIはこれらの技術を利用してさまざまな分野で活用されています。
| 音声認識 | 画像認識 | 自然言語処理 |
| 文字お越し 文字入力 翻訳・通訳 |
顔認証技術 不良品判別 医療診断支援 |
翻訳 音声対話 テキストマイニング |
▶AI(人工知能)にできること一覧|AIの未来や仕事・活用事例を徹底解説>>
▶《AI事例25選》産業別にAIの活用事例をまとめました>>
最新のAIの動向
2021年9月にはデジタル庁が発足し、国全体のデジタル化が進められるようになったことで、企業だけでなく行政でもDXが急激に推進されるようになっています。
AIは農業や製造業、小売や医療などの様々な業界でも導入されており、少子高齢化や東京一極集中からなる労働不足の解消のためAIを導入する業界が増えています。
また、AIを導入することでコストの削減や生産性の向上が見込まれ、他製品、他サービスとの差別化を図ることも積極的に行われています。今やAIを導入し、活用することは国や企業として、デジタル化や競争優位性を高める上で重要なことでしょう。
中でも、注目されている分野を紹介します。
コンテンツ生成
最新AI分野で注目を集めているのが「AIによるコンテンツの生成」です。
AIが人間が描いたようなイラストを生成したり、小説を描いたりなど、さまざまな部分でAIによるコンテンツ生成が進んでいます。
イラスト生成AI 「NovelAI」

(出典)NovelAI
コピーライティングサービス「JasperAI」

(出典)Jasper
需要予測
AIによる需要予測の活用事例は、これまでも多数ありました。
しかし、近年では複雑化・多様化が進む現代のビジネス環境において、経験や勘を頼りにするのは困難になりつつあります。パンデミックなどの影響もあり、不確実性が増す今、合わせて需要予測のニーズが高まりつつあります。
▼DX(デジタルトランスフォーメーション)について詳しく知りたい方はこちら

まとめ
この記事ではAIの歴史について紹介してきました。AIの誕生や時代ごとにAIがどのような道をたどってきたのか分かったのではないかと思います。
AIはまだまだ誕生したばかりですが、非常に奥深いものです。AIの歴史について知り、少しでもAIに興味を持ってもらえたら幸いです。



























