

近年、ディープラーニングが注目されており、様々な分野で活用されています。そのなかでも画像認識は実生活の中でも広く実用化されています。
そこで、今回はディープラーニングを活用した画像認識について、できること、仕組み、実用例からモデルを作成する方法まで紹介していきます。
▼画像認識について詳しくはこちら

目次
ディープラーニングの概要
ディープラーニングとは、人工知能技術の中の機械学習技術の1つで、深層学習とも呼ばれています。機械学習を発展させ、「ニューラルネットワーク」と呼ばれる人間の神経細胞をモデルとしたコンピュータを利用し学習するという仕組みであり、コンピュータが自動で集めた大量のデータをもとに、自動で学習する技術です。
ディープラーニングは、インターネットの普及によって学習に必要なデータが大量に必要とされるようになったことや、コンピュータの処理性能向上によって短時間で処理をおこなえるようになったことで、実用化が加速しました。
▼ディープラーニング に関して詳しくはこちら

ディープラーニングと機械学習の学習の違い
では、ディープラーニングと普通の機械学習の学習の違いは何なのでしょうか。
そもそも、ディープラーニング(深層学習)と機械学習は対比するものではなく、両者は包含関係にあり、上記でもあるように機械学習の1つの技術としてディープラーニングがあることを前提におきます。
最も分かりやすい両者の違いは、学習するデータを自動で選択することができるか、そうではないかです。ディープラーニングは先ほど紹介したように、コンピュータが自動でデータを集めて学習します。一方、機械学習では、人間がデータを選択してコンピュータに学習させる必要があります。
なぜディープラーニングを使うのか
では次に、なぜ機械学習ではなくディープラーニングを使うことが増えてきているのかを紹介します。
理由は主に2つあります。
音声・動画のような非構造化データにも対応できる
1つ目の理由は、音声や動画のような非構造化データにも対応できるということです。構造化データとは、検索エンジンがその内容を理解しやすくなっているデータ形式のことで、非構造化データはその逆です。映像などの処理が可能になることで、リアルタイムで分析できるようになりました。
スマートフォン、エッジデバイスでも利用できる
スマートフォンなどに搭載されているAIをエッジAIと呼びます。従来はクラウドにすべてのデータを送って処理をしていましたが、エッジAIではその必要がありません。そのため、AIに必要な学習モデルやデータベースをすべて備えた状態で提供されるクラウドAIに比べると、より素早く、リアルタイムで処理ができるようになりました。
ディープラーニングを生かした画像認識に集まる注目
このディープラーニングを活用した画像認識は、現在幅広く活躍しています。
ILSVRC 2012でディープラーニング を生かしたモデル「AlexNet」が優勝
ILSVRC (ImageNet Large Scale Visual Recognition Challenge)とは、AIによる画像認識の競技形式の研究集会で、出場したチームは自分たちで開発した画像認識システムで認識精度を競います。
2012年、トロント大学のチームによって初めてディープラーニング を活用したモデル「AlexNet」が活用されました。その認識精度はエラー率17%弱と、他のチームが26%ほどだったのに比べて高い精度で優勝しました。
従来使われていたサポートベクターマシンなどの手法から大きなブレイクスルーとなり、ディープラーニングは世界的に注目を集める技術となりました。
ディープラーニング による画像認識が始まる
ILSVRCにおけるAlexNetの優勝以降、ディープラーニング はあらゆる分野で活用されるようになりました。
その中でも特に活用が進んでいる領域が画像認識です。AIが人間の目のような働きができるようになったことで、ロボットに搭載したカメラの映像を通して自律的な行動が可能になります。
非構造化データにも対応できる
画像認識技術は動画のような非構造化データにも対応することができます。
※非構造化データ:エクセルなどのように表形式で構造化されたデータではなく、音声や動画のように構造化できないデータ。
例えば、防犯カメラにAIを搭載し、不審者がカメラに映ると管理者に知らせるシステムなどが実際に導入されています。
そのように、画像認識によってリアルタイムな分析が可能になったことで活用の幅が広がりました。
技術発展でスマートフォンやエッジデバイスでも処理可能に
画像認識はクラウドを離れ、スマートフォンやエッジデバイスでも利用できるようになっていて、これをエッジAIと呼びます
エッジAIならデータをクラウドに送って処理する必要がなくなり、クラウドAIに比べてよりリアルタイムに処理することができます。
エッジAIは工場での品質検査やスマホアプリなどあらゆる部分で活用されています。
ディープラーニングを活用した画像認識にできること
次に、ディープラーニングを活用した画像認識に何ができるのかを紹介します。
学習用データに基づいて半自動的に仕組みを構築
1つ目は学習用データに基づいて半自動的に仕組みを構築することができるということです。このため、継続的にデータの取得できる体制さえ作っておけば、継続的な精度向上、維持が簡単に行えます。
低コストで高精度な画像処理
2つ目は低コストで高精度な画像処理ができることです。
コンピュータが自動的にデータを集めて処理するためコストもかからず、継続的に高い精度を維持できるため、高精度な画像処理が可能になります。
ディープラーニング で画像認識ができる仕組み
大量の画像データをもとに学習
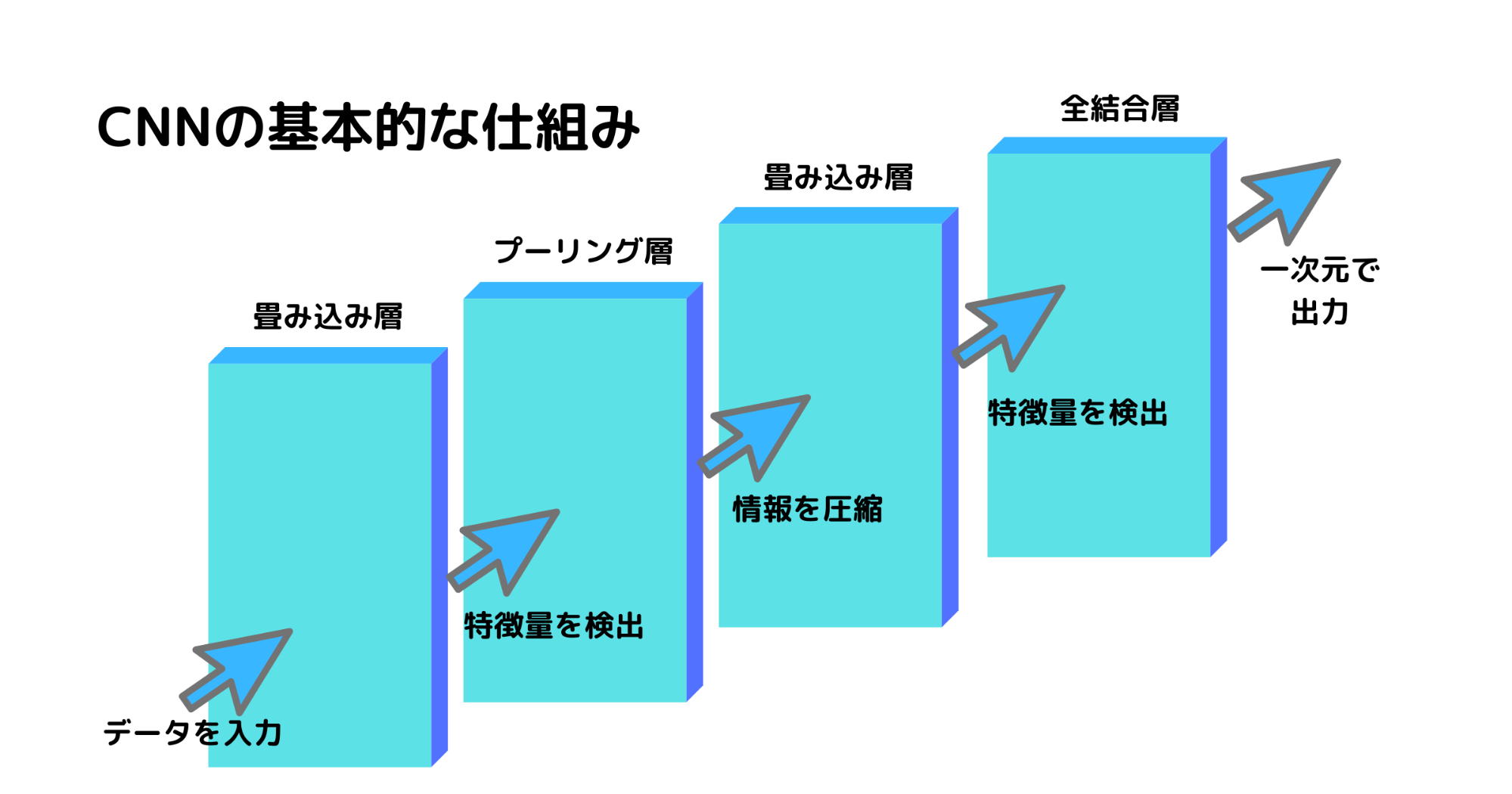
ディープラーニングを生かした画像認識には主にCNNという仕組みが使われています。
CNNは主に畳み込み層とプーリング層が交互に存在する形で成り立つモデルです。
CNNに画像データを入力すると、まずは畳み込み層で特徴量の検出が行われます。
そして、その特徴量の情報はプーリング層に送られ、情報を圧縮します。圧縮した情報は次の畳み込み層に送られ、その手順が何回か繰り返されます。
最後に、画像データを「猫or犬」などというふうに一次元の形で出力するための全結合層を経由したのちに、出力されます。
畳み込みニューラルネットワーク(CNN)
畳み込みニューラルネットワークはCNN(Convolutional Neural Network)と略されており、画像認識をする際によく使われている形式で、他にも物体検出、領域推定などの画像分野で活躍しています。CNNはその名の通り、特徴とデータを一緒に畳み込んで蓄積していきます。畳み込みとは画像から”特徴を抽出する操作”のことを指します。また、CNNは中間層が畳み込み層とプーリング層で交互に構成されていることが特徴です。
▶CNN(畳み込みネットワーク)とは?図や事例を用いながら分かりやすく解説!>>
敵対的生成ネットワーク(GAN)
敵対的生成ネットワークはGAN(Generative Adversarial Network)と略されます。GANは2つのネットワークで構成されており、1つは生成器(ジェネレータ)でもう1つは識別器(ディスクリミネータ)と言います。
- ジェネレータ:ある値を入力値として受け取り、画像データを出力する。
- ディスクリミネータ:ジェネレータが出力した画像データを受け取り、本物か偽物かを予測して出力する。
ジェネレータはディスクリミネータが間違えるような画像を作るように学習していき、ディスクリミネータは偽物をきちんと見抜けるように学習していきます。この2つのネットワークをイタチごっこさせることで、画像認識の精度をアップさせていくシステムです。GANは、偽物の画像を作るニューラルネットワークと、それを見破るニューラルネットワークで構成されています。
▼関連記事
・敵対的生成ネットワークの台頭【前編】>>
・敵対的生成ネットワークの台頭【後編】>>
画像認識におけるディープラーニング モデルの変遷
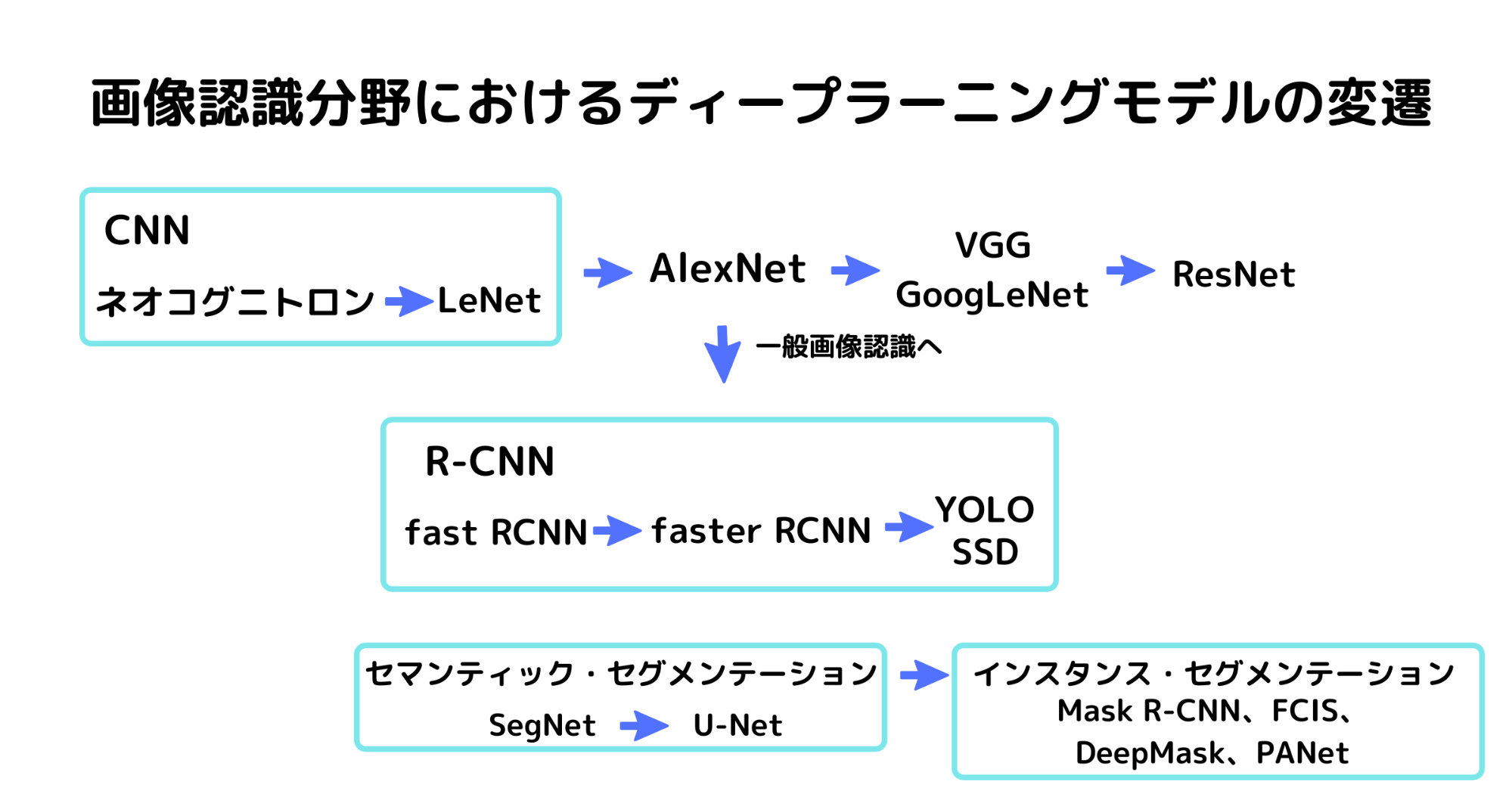
AINOW編集部作成
CNNを核として、あらゆるモデルが開発され続けています。
まず、CNNのきっかけはネオコグニトロンです。ネオコグニトロンとは、1982年に日本人研究者の福島邦彦氏が発表したCNNの初期のモデルです。ネオコグニトロンを起源にCNNの原型となるLeNetが開発されました。
こうして生まれたCNNが改良されてAlexNetとなり、VGG、GoogLeNetへと続きます。
そして、それらが改良されResNet(Residual Network)へとなります。
ILSVRCに出場するモデルでの画像認識では限られたカテゴリーでの分類でしたが、それを一般画像認識へと応用する取り組みが始まり、R-CNNが生まれました。
入力された画像から検出したい物体がある部分など切り出すべき関心領域(Region of Interest:ROI)を特定し矩形(バウンディング・ボックス)で切り出して分析することで、物体検知が可能になります。
▼草むらに潜むイモムシを物体検知(赤線がバウンディング・ボックス)

AINOW編集部作成
fast R-CNNでは、バウンディング・ボックスの設定と切り出した画像の画像認識を同時に行うことができます。そして、fast R-CNNのバウンディング・ボックスの切り出し方を工夫することで高速化したのが、faster R-CNNです。現在では、物体検知の技術はさらに進歩しYOLO(You only Look Once)やSSD(Single Shot Detector)などが主流になっています。
同時に、画像からROIをバウンディング・ボックスで切るのではなく、画素レベルで分析する手法も生まれました。
セマンティック・セグメンテーション は輪郭として物体を検出します。ただし、その方法では同じジャンルの物体を検出することはできても、複数の物体を分けて検出することはできません。
具体的に言うと、画像の中から「人」を検出することはできても、Aさん・Bさんのように人を分類して分析はできません。
そこで登場したのが、インスタンス・セグメンテーション です。インスタンス・セグメンテーション では同じジャンルの物体をそれぞれ分類しながら検出することができるようになりました。
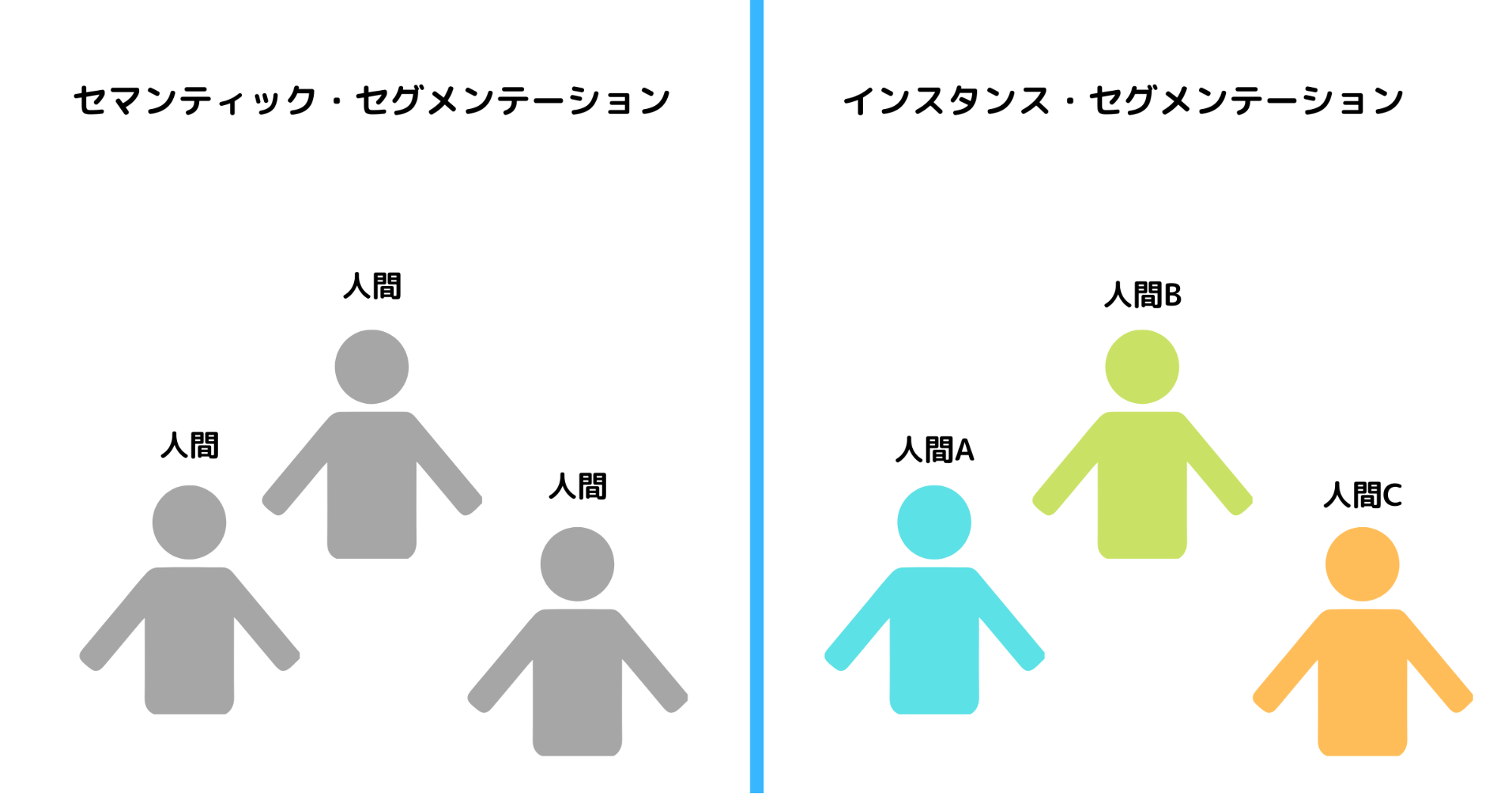
AINOW編集部作成
ディープラーニングによる画像認識の実用例8選
次に、ディープラーニングによる画像認識が、実際にはどのように活用されているのか、例をあげていきます。
①顔認証システム
まず、顔認証システムです。
顔認証システムは、画像認識を活用し、カメラやスマートフォンなどに映った顔を認証して、登録されている顔と一致するかどうかを判断します。これは扉やスマートフォンのロック解除、本人確認などによく使われており、入退室管理が自動で行われるため人件費の削減につながったり、端末使用者を顔認証することで不正利用を防止したりします。
②自動運転
近年開発が進んでいる自動運転にも画像認識が利用されています。
ディープラーニングの技術を利用して、標識や信号機、歩行者などの認識や検出を行います。自動運転では人間の不注意による事故を減らすことができると期待されています。
③不良品の検知
不良品の検知にもディープラーニングを活かした画像認識が利用されています。
様々な画像を学習させてパターンを認識させることで、不良品や不純物を検知できます。食品に付いた微細なゴミや衣類の汚れ、製造した商品の細かなひび割れや欠けなどの検知が可能です。
④護岸の検査
護岸の検査でも画像認識が利用されています。
日本国内には35,462本もの河川があり全ての護岸を整備するには人手が足りません。そこで、画像認識技術を使って護岸の検査を自動化することで、より効率的にひび割れや欠損を見つけられるようになりました。
⑤がん細胞の検出
がん細胞の検出にも利用されています。
高精度な顕微鏡とディープラーニングを組み合わせることで、人間の目では捉えることのできないような微細ながん細胞も自動的に検出できます。その他の医療分野でも活用されており、病気の早期発見・早期治療にも繋がることが期待されています。
⑥農業用ロボット
農作物と雑草を自動で判別するロボットや、農薬を散布するためのロボットとしても活躍しています。
現在、農業分野では高齢化に伴い人手不足も進んでいるため、このディープラーニングを活用した画像認識は注目を集めています。
▼関連記事
・【農業×AI】農家が抱える課題を解決する農業AIまとめ>>
・AI搭載のドローンって何?|できること・活用例・今後など詳しく解説!>>
⑦建設現場での機械の安全使用
建設現場では重機などの危険な機械も使われており、作業員の安全性を確保することが重要な課題でした。
そのため、このディープラーニングによって、重機の周りや危険な場所に作業員などが侵入したときに自動で検出し、重機の動作を止める機能が実用化されています。
⑧空港の出国ゲート
また、空港の出国ゲートでも利用されています。成田空港では出国ゲートにAIの顔認証システムを導入しています。
今までは出国ゲートにスタッフが立ち、顔写真との見比べや出国の押印をしていました。そのため、一人ひとりの処理に時間がかかったことから常に長蛇の列が発生していたことが課題でした。そこで、顔認証システムで旅行者がカメラの前に数秒立つだけで手続きを完了できるようになったことからスムーズな手続きが可能になりました。
おすすめの画像処理サポート
次に、おすすめの画像処理サポートを紹介します。
画処ラボ – あらゆるケースの画像処理の相談を
(出典:https://gasho-labo.jp/)
「画処ラボ」は2020年2月、画像処理検証施設として神奈川県相模原市で開所しました。組み合わせ技術を有するシステムインテグレーターとして、マルチメーカーでの機器選定・判断プログラム選定・周辺設備含めた装置構想まで提案できます。画処ラボを窓口として、装置製作からアフターサポートまで一括での対応も可能です。
ルール型画像処理からAIによる画像処理まで幅広く対応が行えるのが特徴です。
株式会社日立ソリューションズ – 目視作業の自動化

(出典:https://www.hitachi-solutions.co.jp/smart-mobility/sp/column/column2021082501/?cid=yjl_10250748)
様々な脅威に対応する多彩なソリューションを持っており、個別の課題にそれぞれピッタリの解決方法を提示できます。
デジタルカメラ開発や自動車の物体認識機能など、画像処理技術と最新の機械学習技術で、顧客のデジタルトランスフォーメーションを推進し、自動化システムの導入を支援しています。
株式会社ブレインパッド – 伝統工芸品×AI

(出典:https://www.brainpad.co.jp/ai/people/story5/)
ブレインパッドは、データを活用してビジネス創造と経営改善を支えてきました。データ活用に強みのある会社です。
不良品検知のアルゴリズム完成に伴い行われたプロジェクト報告会で、ブレインパッド開発チームはアルゴリズムの業務運用方法を提案しました。その1つが「不良品検知プロダクト」です。熊野筆は熟練の職人による手作りのため、筆先の大きさや膨らみなどがひとつひとつ微細に異なります。そこで、完成した筆がブランド基準を満たしているかどうか、最終工程で職人が目視で検品をしています。
検品は職人の経験、感覚に委ねられているため、判断が難しい場合には良品、不良品の判定が人によって異なることがあります。そこで、このチェックにAIの画像認識を活用することで、どんな時にも判定がぶれない正確な検品体制を構築することができるようになりました。
ディープラーニングを活用した画像認識モデルを作成する方法
ディープラーニングモデルを作成する手順は以下の通りです。
- データを観察する
- 大雑把に方針を決める
- ベースラインのコードを作る
- パラメータを変えながら学習を走らせてみる
- 学習されたモデルの比較評価
データの観察ではまず、写っているものが何なのか、データの多様性はどれくらいかなどを考えます。そこから技術要素や難しそうなポイントを想像し、どのような方法でとけばよいのか大雑把に決めます。そして基礎となるコードを作り、パラメータのセッティングを変えながら実験していきます。最後に、最も良いと判断されたモデルを最終版とします。
また、ディープラーニングモデルを作成する代表的な方法は主に以下の3つです。
- 「0の状態から学習させる」
- 「学習済みのモデルを転移・調整する」
- 「特徴抽出する」
0から学習させる場合には、ラベリングされた大量のデータやネットワーク設計が必要になるため時間やコストがかかります。
そして、学習済みモデルを転移する場合は、他の分野を学習したモデルに学習していないデータを与えることで、新しいタスクが行えるようになります。0から学習するのに対して必要なデータ数や計算時間が少なく済みます。
特徴抽出は、ネットワークを特徴抽出のために使用する方法で、抽出した特徴を取り出して機械学習モデルに取り入れます。
まとめ
この記事ではディープラーニングを活用した画像認識について概要や仕組み、実用例を紹介しました。ディープラーニングを画像認識に活用するときの参考にしてみてください。
慶應義塾大学商学部に在籍中
AINOWのWEBライターをやってます。
人工知能(AI)に関するまとめ記事やコラムを掲載します。
趣味はクラシック音楽鑑賞、旅行、お酒です。



























