

こんにちは、AINOW編集部です。
みなさんは、機械学習の分類についてご存じでしょうか?分類は機械学習の3つのグループの内の1つに属しています。初学者にとって、機械学習の3つのグループを把握することが最初の難関です。
本記事では、初学者から中級者までを対象に、機械学習の分類の属するグループについてや分類について説明していきます。
後半では、機械学習の分類について学べるコンテンツも紹介しているので、最後までご一読ください。
▼AIについて詳しく知りたい方はこちら

目次
機械学習の分類とは
まずは、機械学習の分類について説明します。
そもそも機械学習は、データのタイプや状況によって、教師あり学習・教師なし学習・強化学習の3つに大きく分けられます。その中でも分類は、「教師あり学習」に属する手法です。
そこで、まずは機械学習と教師あり学習について説明し、その後「分類」について解説していきます。
機械学習とは
まずは「そもそも機械学習が何か分からない」という方のために、機械学習の概要を説明します。
機械学習とは、「コンピュータに大量のデータからパターンやルールを発見させ、それをさまざまな物事に利用することで分類や予測をするAI技術のひとつ」です。
一般的には、大量の画像データを学習させた画像認識のアルゴリズムや、大量のテキストを学習させた自然言語処理のアルゴリズムなどが流通しており、社会のさまざまな面で機械学習の活用が進んでいます。
▼機械学習、教師あり学習の詳しい解説はこちら

▶画像認識とは|機能・事例・仕組み・導入方法など徹底解説>>
▶自然言語処理についてはこちらの記事でも詳しく解説しています>>
教師あり学習とは
ここからは、分類が所属する「教師あり学習」について説明します。
教師あり学習とは、コンピュータに事前に正解となるデータを教えた後、新たなデータを与えた際に正解か否かを判断する方法のことです。
教師あり学習では、教師データを既知の情報として学習に利用し、未知の情報に対応することができる回帰モデルや分類モデルを構築します。
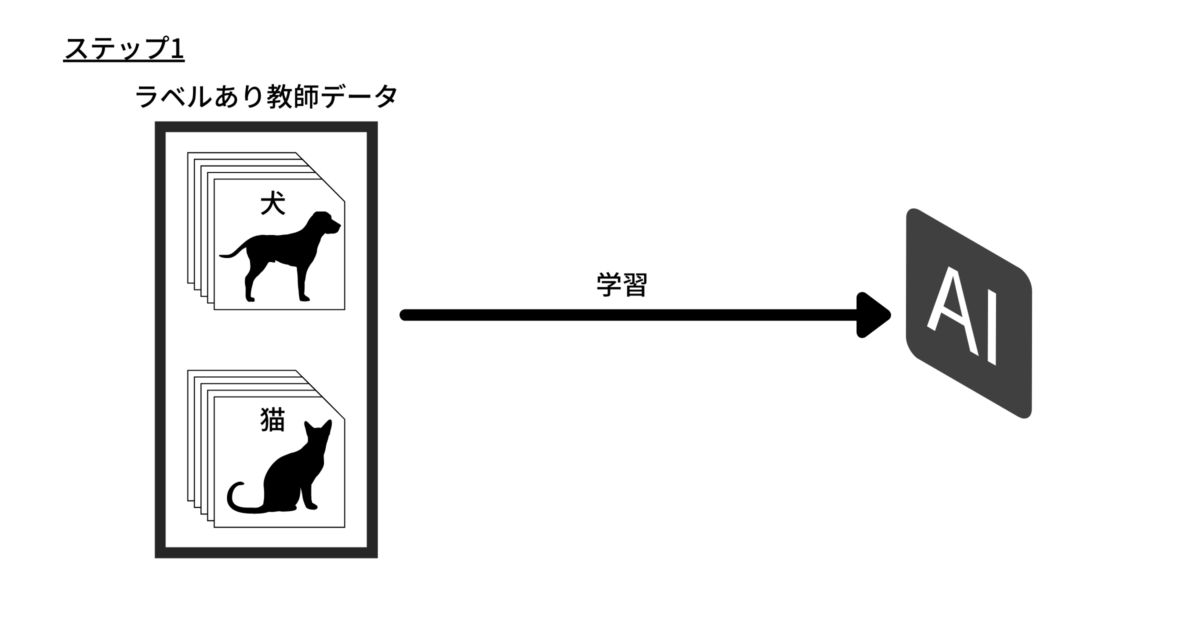
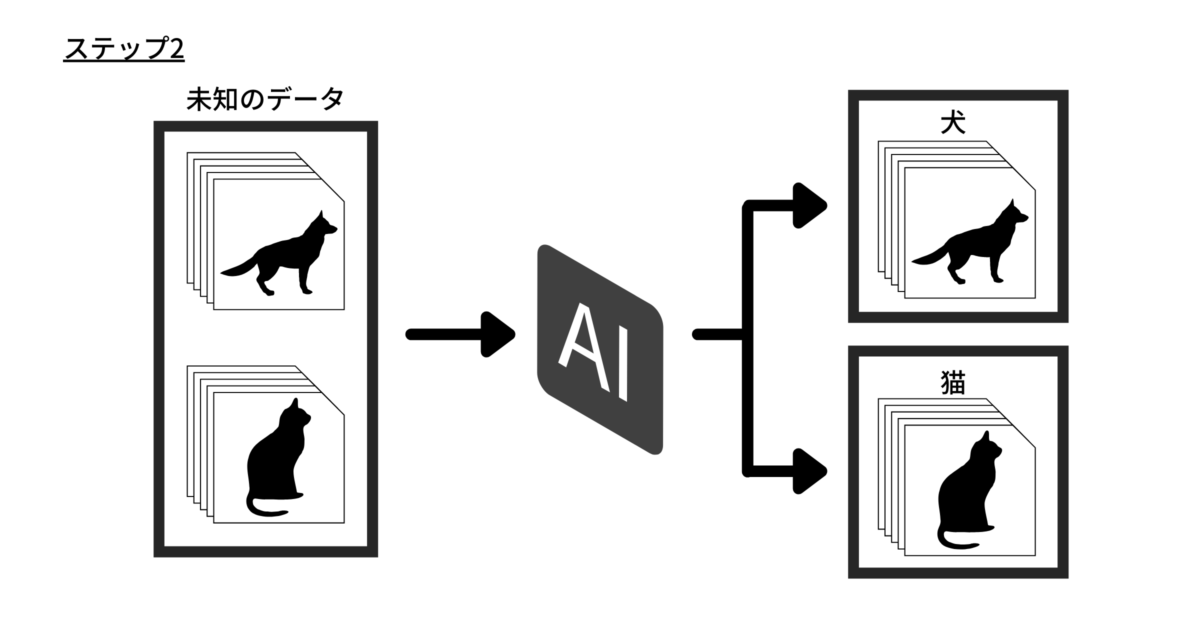
例えば、事前に「犬」や「猫」というラベル(教師データ)が付けられた大量の写真をコンピュータに学習させて、モデルを構築するとします。
ラベルのない写真が与えられた場合、モデルはその画像に一番近い特徴を持つ学習済みの画像に貼ってあるラベルを出力します。
そして、このモデルは与えられた画像が「犬」または「猫」であることを検出できるようになる、という仕組みです。
AINOW編集部作成
AINOW編集部作成
教師あり学習に属しているものとして回帰や分類があり、ニューラルネットワーク・ディープラーニングは、この「教師あり学習」を発展させたものになります。
▼ディープラーニングについて詳しく知りたい方はこちら

▶機械学習におけるモデルとは?|モデルの種類や「よいモデル」とは何かについて>>
分類とは
機械学習の分類とは、言葉のとおり「さまざまなものを分類する」ということです。
具体的には、犬、猫といった2種類の動物の写真があった場合、それぞれに0,1などの離散値を付けます。そして、新たに読み込んだ写真があった場合、0,1のどちらの数値に近いのかで分類するといったものです。
代表的な機械学習の分類アルゴリズム4種類
機械学習の分類を考える上でアルゴリズムは重要です。どのアルゴリズムを使えばいいかは後ほど説明しますが、ここでは各アルゴリズムの簡単な説明をしたいと思います。
今回紹介する代表的な機械学習の分類アルゴリズムは以下の4つです。
それぞれ解説していきます。
決定木
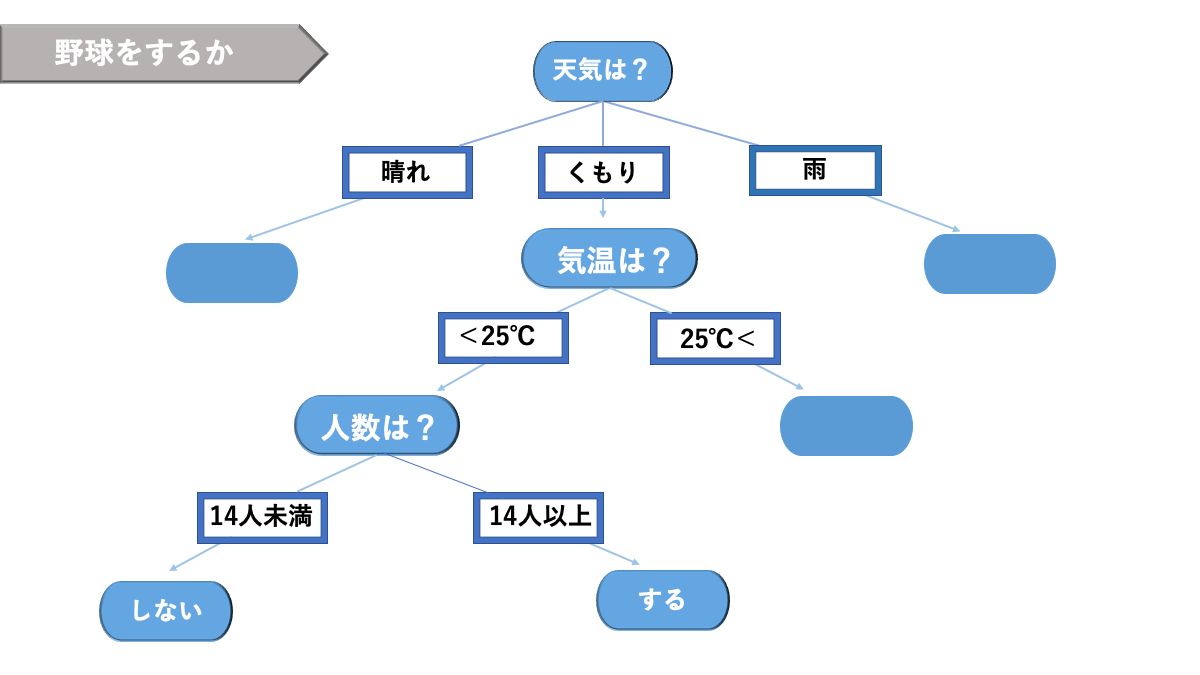
決定木とは、条件分岐によってグループに分けられる木の構造をしたもののことで、回帰に使える回帰木、分類に使える分類木を総称したものです。
決定木は、樹木形をした以下のグラフのようなものであり、リスクマネジメントをはじめ、何かしらの決定をする際に利用されます。
-

AINOW編集部作成
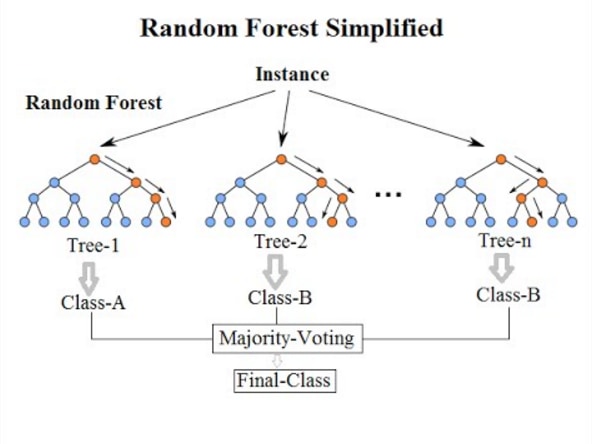
また、複数の決定木を使い、平均や多数決を算出するランダムフォレストという発展があります。
ランダムフォレストは、学習範囲が異なる複数の決定木を集めて分析する手法であるため、単独の決定木より優れた分析結果を出すことが可能です。
ロジスティック回帰
ロジスティック回帰は、線形回帰という手法を応用したもので、名前に回帰とついていますが、実際は分類問題に使用される手法です。
基本的には、「ある事柄が起きるか起きないか」を分類するために使われます。
このモデルは、線形回帰で使われる線形多項式に、ロジスティック関数(もしくはシグモイド関数とも呼ばれる)を適用することで、分類問題を解けるようにしただけの手法です。
そのため、分類問題に対して最も簡単なモデルの一つと言っていいでしょう。
サポートベクターマシン(SVM)
サポートベクターマシン(SVM)とは、データを境界線で分けるアルゴリズムです。回帰と分類の両方で使えますが、主に分類に用いられます。
サポートベクターとは「データを分割する直線に最も近いデータ」です。「マージン最大化」と呼ばれる考え方を使い、正しい分類基準を見つけます。
SVMは、データの次元が増加しても識別精度が良いことや、試行回数が少なくて済むなどのメリットがあり、株価予測や異常値検出の分野で応用されています。
▶SVM(サポートベクターマシーン)とは|仕組み・メリット・勉強方法>>
ナイーブベイズ
ナイーブベイズとは、ベイズの定理を用いたアルゴリズムのことです。ベイズの定理とは、ある事象の起こった確率から、原因となる確率を求められる定理であり、統計学の基礎として頻繁に用いられています。
ナイーブベイズは、計算量が少なく処理が高速であるため、大規模データにも対応できますが、やや精度が低いといった問題があります。
それぞれのクラスに分類される確率を計算し、最も確率の高いクラスを結果として出力するため、スパムフィルターなどテキスト分類のタスクに活用されています。
▶機械学習の代表的なアルゴリズム12選|機械学習の学習手法まで紹介!>>
機械学習の分類のメリット
分類のメリットは、「カテゴリー分けできる」ということです。例えば、初めの方にも出てきた犬・猫の分類を考えてみたいと思います。
教師あり学習では、はじめにこの写真が犬、この写真が猫といったように答えを一緒に入力します。そして、新たな写真を読み込んだ時、犬、猫を判別します。
こうしたカテゴリーを2つに分類するものを2値分類といい、それ以上のものを多値分類( 多クラス分類)といいます。
こうしたカテゴリーに分けることは、分類のメリットであり、機械学習の得意とすることの一つです。
機械学習の分類のデメリット
前述ではメリットについて説明しましたが、今回は分類のデメリットについて説明します。
分類のデメリットは、「数値予測といった連続値の予測ができない」ということです。分類はその名の通り分類することを得意としているからです。連続値の数値を予測することは、回帰の分野となります。
▶AIによるメリット・デメリットは?人工知能の問題点と解決策も紹介>>
Pythonで分類を行うためには?
機械学習によく使われるPythonで分類を行うにはどうしたらよいのでしょうか?
Pythonには、Scikit-learnライブラリというものがあります。Scikit-learnライブラリは、サンプルのデータセットが付属しているため、初学者でもすぐに始めることが可能です。
Scikit-learnライブラリでは、分類や回帰も行えるので、興味のある方は始めてみると良いでしょう。
▶3ステップで学ぶPythonによるAI開発 – おすすめの勉強法も紹介!>>
アルゴリズムを判別できる3つのチートシート
分類の学習・活用をする上で、「このデータはどのようなアルゴリズムを使えばよいのだろう」と思うときもあるでしょう。そんな時におすすめなのが「アルゴリズムを判別できるチートシート」です。
以下で紹介している3つのチートシートを活用すれば、質問に答えていくだけで最適なアルゴリズムを見つけられます。
Scikit-learn
Scikit-learnの公式チートシートです。表記はすべて英語ですが、公式が配布しているため、信頼性は高いでしょう。カラフルに色分けされているのが特徴です。
SAS Institute Japan
アメリカに本社を置く統計解析ソフトを作っているSAS Instituteの日本法人です。日本語のチートシートを公開しています。教師あり、教師なしで分かれていることが特徴です。
機械学習アルゴリズムチートシート-Azure Machine Learning
Microsoftが公開しているチートシートです。細かいカテゴリに分かれていることが特徴です。MicrosoftのクラウドサービスMicrosoft Azureを使う方にとって親和性が高いでしょう。
機械学習の分類の代表的な評価指数
ここからは少しレベルを上げてみましょう。この章では、各アルゴリズムがどれだけの結果を出しているのかなどを評価をする確認の数値を見ていきます。
正解率(Accuracy)
正解率は学習を行って予測した結果がどれだけ正解したかの数値になります。つまり、予測結果すべての内、どれだけ正解したかを表します。
適合率(Precision)
適合率は学習を行って正解と予測したものの内、本当に正解だったものの割合です。つまり、予測結果の正解の内、どれだけ正解したかを表します。
再現率(Recall)
再現率は、本当に正解だったものの内、正解と予測したものになります。つまり、正解データの内、予測結果が正解と判断されたものを表します。
機械学習の分類について学べるコンテンツ
機械学習を学ぶためには、さまざまな方法があります。この章では、機械学習の分類について学べるコンテンツを3つ紹介します。
専門書
1つ目は、「専門書で学ぶ」という方法です。専門書は、各出版社によって中身がきちんと校閲されているため、内容に信頼性があります。
さらに、より詳しく分類を学びたい方は、「図解即戦力 機械学習&ディープラーニングのしくみと技術がこれ1冊でしっかりわかる教科書」など、専門家が執筆している書籍を読むと良いでしょう。
さらに、専門家が執筆している専門書もありますので、詳しく分類を学びたい場合におすすめです。
▶【2021年版】AI関連のおすすめ本15冊をランキング形式でご紹介>>
学習サイト
2つ目は、「学習サイトで学ぶ」という方法です。学習サイトによっては、動画コンテンツやエンジニアの方に質問ができるといったことまで理解度が高まる仕組みがあります。
無料から有料のものまで、さまざまな形態があります。例えば、paizaやUdemyでは、機械学習について詳しく学べるコンテンツが揃っています。
スクール
3つ目は「スクールで学ぶ」ということです。
スクールは第一線で活躍するエンジニアの方から学べたり、質問ができたりという特徴があります。未経験や初学者でも学びやすい「AIジョブカレ」などがあります。
▶AIを学べるスクールおすすめ5選|メリット・デメリット、選び方まで紹介>>
この他にも、講座や大学・専門学校で学ぶなど、さまざまな方法があります。自分に合った学習方法を探して機械学習を学んでいきましょう。
▶【AI Lab Map 2018】約300件!AI関連の大学研究室を分野・地方別にマップ化>>
▶未経験からAIを学べる講座23選|無料からオンラインまで徹底比較>>
まとめ
いかがだったでしょうか。本記事では機械学習の分類からその周辺情報までお伝えしてきました。
機械学習の分類は回帰と一緒に学習することをおすすめします。分類と回帰の違いを確認しながら学習することが良いでしょう。
AINOWでは、AIについて他にもさまざまなコラムがあります。そちらも一緒にご覧いただくとより機械学習や分類について理解できるようになるでしょう。



























