

近年、私たちの生活とAIは切っても切り離せない関係になりつつあります。そんなAIの得意分野の一つが「画像認識」です。
画像認識とは、その名の通り画像からパターンを認識して「何が映っているか」を特定する技術を指します。2012年、画像認識はディープラーニングにより精度が大きく向上し、それ以降さまざまな場面で活用されるようになりました。
しかし、画像認識の概要を知らない方や、大まかにしか理解していない方も多いでしょう。
そこで今回は、「画像認識とは」を詳しく解説しつつ、画像認識の歴史や活用事例、導入におけるポイントまで紹介していきます。
▼AI(人工知能)について詳しく知りたい方はこちら

目次
画像認識の活用事例
画像認識技術といっても、画像の種類によって対象の形状や色、複雑さ、データの数などが違ってきます。そのため扱う画像データによって技術領域を分けることができ、主に以下の5つがあります。
順番に解説していきます。
物体認識
まず1つ目が物体認識です。物体認識とは、特定の物体と同一のものが画像中に存在するか検証するときや、画像に映っている物体のカテゴリを見分けるなど、画像に含まれている物体の情報を抽出する技術です。この技術は様々な分野で利用されています。
それぞれについて解説します。
物流
その1つが物流です。物流には物を移動させる業務だけでなく、その過程で包装や保管といった業務も含まれます。そのため、倉庫への入庫作業なども物流に該当します。
従来は人間が行っていた目視による確認とシステム入力作業、さらに複雑な仕分けを自動化させることで、検品業務の時間を短縮し、人件費も削ることができました。
▶関連記事|物流DXはハードルが高い?5分でわかる定義から導入まで>>
密を回避
最近は新型コロナウイルスの流行に伴い3密を避けることが重要とされています。その中で人数を数えて「密」の状態を回避するカメラが開発されました。
自動運転
自動運転では、センサーや画像認識AIなどによって人や障害物がないか、自動車周辺の情報を把握しながら走行します。
また、センサーや画像認識によって全方向の視覚情報を拾うことができるため、目線の方向しか見ることができない人間が運転するよりも安全に運転することができます。
また、車内においても画像認識の技術活用が進められようとしています。ドライバーの眠気を察知して事前にアラートを出すような仕組みをオムロンが研究しています。詳しくは、以下のリンクから参考にしてください。
▶関連記事|眼底の画像認識で眠気の予兆を察知するオムロンの取り組み>>
PC操作の自動化
従来は、マウスの座標や高レベル記録で取得した要素を使ってクリック操作をしていましたが、その場合、クリックしたい場所の座標は色々な条件で変化してしまって不安定になりがちでした。ところが、UWSCというパソコンのキーボード・マウス操作を自動化するソフトを使えば、PCによる画像の自動クリックが可能になります。
画像認識を活用することで、「特定の画像が現れたらその画像を自動でクリックする」といったPC操作の自動化ができるのです。
車両種別の判別
車両種別の判別では、AIを活用して防犯カメラに写っている自動車の画像から車種を区別していきます。画像認識AIを活用することで、画像が不鮮明であっても車のタイプや車種、年式などを判別できるようになりました。
無人レジ
無人レジは、AIに「来店した客の属性」「購入した商品」「手に取った商品」などの情報を学習させることで可能になります。また、これにより発注や在庫管理の精度向上など、マーケティング分析にもつなげることができます。
例えば、高輪ゲートウェイ駅には、「TOUCH TO GO」という無人AI決済店舗があります。TOUCH TO GOは、ウォークスルー型の完全キャッシュレス店舗です。
天井などに無数に設置されたカメラの映像をAIが認識し、入店した来店客と手に取った商品をリアルタイムに認識し、決済エリアに来店客が立つとタッチパネルに商品と購入金額を表示します。
▶関連記事|高輪ゲートウェイに無人AI決済店舗が3/23にオープン −今後はサブスク展開も視野に>>
未来の肌をシミュレーション
オルビス株式会社はAI 未来肌シミュレーションというサービスを提供しています。このAIは複雑な美容理論を学習しているため、20兆以上の評価パターンから一人ひとりの肌トラブル進行パターンを導き出し、深層学習による顔画像生成によって未来の肌をシミュレーションすることができます。
顔認識
画像認識の分類の2つ目は顔認識です。これは文字通り人の顔を識別する技術です。
- 顔認証システム
- セキュリティ
- 不審者抽出
上記3つについて解説していきます。
顔認証システム
顔認証システムはスマートフォンなど、最も身近なところで使われている画像認識の一つです。また、顔認識を利用すれば、顔の識別、照合や似た顔の検索、顔のグループ化なども行えます。そして、現在人間の表情から感情を読み取る感情認識についても研究が進められています。
▶AI × 顔|顔生成・顔診断・顔交換のサービスを紹介!>>
セキュリティ
顔認識の技術を活用することで、多数の人物やものが写った画像や映像から事故や犯罪行動パターンをリアルタイムで自動検出できます。万引きや事故の防止、侵入者の検知に活用されています。
不審者抽出
大規模なイベントなどでは、どうしても人の目が届かない場所が出てきてしまうでしょう。
そのため、画像認識AIを搭載した防犯カメラを活用してイベント会場全体を監視することで、イベントでの不審点の抽出を高精度で実行することができます。
実際に三菱電機が商業施設にいる不審者や社会的弱者を監視カメラでとらえるシステムを開発し、東京オリンピック・パラリンピックで実用化されました。
文字認識
そして、画像認識の分類の3つ目が文字認識です。文字読み取り技術は「OCR(Optical Character Recognition)」とも呼ばれます。
文字認識とは、紙に書かれた手書きの文字や、印刷文字などを判別する技術で、最近は自然言語、つまり人間が普段使っている言語をコンピュータに理解しやすくする自然言語処理の発展に伴い、多くの場面で活用されるようになりました。
▶《2022年決定版》AI OCRツールのおすすめ5選を比較!選び方のポイントも紹介>>
郵便区分機
文字認識が活用されるものの1つが郵便区分機です。郵便区分機とは、文字認識(OCR)により定形郵便物などの郵便番号とあて名住所を読み取り、指定された区分け口に自動的に仕分け、集積する機器です。
機械学習ではありませんが、世界最大規模の文字認識システムは郵便局の郵便区分機だとされています。
翻訳
そしてもう1つが翻訳です。Google翻訳などを使ったことがある人も多いのではないでしょうか。Google翻訳アプリには、カメラを使ってテキストをリアルタイムに翻訳する機能が実装されています。
これは、近年非常に高い精度で自然言語処理を行えるようになってきているため可能になりました。
▶使うべきAI翻訳は?【翻訳機など7サービスとメリットを紹介】>>
物体検出
画像認識の分類の3つ目が文字認識です。物体検出とは、画像や動画から物体を検出する技術です。物体検知なら、画像や動画の中に特定の物体が確認された場合に位置や種類、個数を特定することができます。
- 不良品検知
- 画像検索の精度向上
- SNSマーケティング
上記3つのことを解説していきます。
不良品検知
物体検出が活用される分野の1つに不良品検知があります。
主に工場の製造ラインで利用され、不良データがない場合にも、正常時の画像データを数百枚学習することで正常ではないと判断された画像に対して「不良」と判定する外観不良検知アルゴリズムを構築します。
画像検索の精度向上
画像認識は、画像検索の精度向上においても活用されます。従来は似たような画像を分類することが困難でしたが、物体検出の技術が向上したことで、この精度が上がりました。
Googleレンズは画像検索の精度が向上したことで可能になったアプリです。Googleレンズは、スマホ内に保存してある写真や画像をそのままGoogleの画像検索に載せ、類似結果を表示してくれます。
SNSマーケティング
一般の消費者が投稿したSNSの画像から、画像認識技術を利用して自社の商品が写っている画像のみを判別して抽出することができます。
また自社商品と一緒に撮影されている背景・物体・人物についても解析することで商品の利用実態を把握することが出来るようになりました。
▶徹底解説!進化してゆくAI×マーケティングの無限の可能性について>>
画像キャプション生成
画像認識の分類の4つ目は画像キャプション生成です。
画像キャプション生成とは、1枚の画像を入力としてその画像中で行われている出来事や人物・動物などの振る舞いなどを説明するキャプションの文章を生成する技術です。
画像中の各要素をそれぞれ画像認識モデルで認識した後、その画像特徴量や識別されたラベルをもとに、言語モデルを用いてキャプションを生成します。
Seeing AI
出典:Seeing AI
Seeing AIは、Microsoftが開発する視覚障碍者向けのカメラアプリです。このアプリでは、カメラを通して映し出したもののキャプションを生成しており、これにより目の見えない人が目の前にあるものを把握する手助けをしています。
▼ダウンロードはこちらから
「Seeing AI」をApp Storeで (apple.com)
画像認識とは
画像認識とは、簡単に言うと「画像から何が映っているのかを認識する技術」です。
ディープラーニングと呼ばれる手法によって精度が格段に向上し、現在の画像認識は、ときに人間を超える能力を発揮します。
画像認識について理解するのにぴったりな画像があります。

こちらは、アトムテック株式会社が2020年12月に正式提供を開始した「AI人数カウントサービス」の画像です。
AI人数カウントサービスでは、ディープラーニング技術により画像から人間を特定してカウントすることで、コロナ禍の3密を可視化できます。
椅子や柱は検出されることなく、人間だけをうまく検出していますよね。
このように、画像認識は対象物の特徴を捉えたものを検出し、それが何かを特定することが可能です。
画像認識の歴史
次に、画像認識の歴史について紹介します。画像認識技術は以下3つのポイントを迎えながら進歩してきました。
それぞれ解説していきます。
▶関連記事|【7分でわかる】AI研究、60年の歴史を完全解説>>
コンピュータによる画像認識研究
コンピュータによる本格的な画像認識研究が始まったのは1960年代です。
対象は 宇宙開発、核物理学、医学などの先端分野に限られており、当初は人工衛星画像の画質改善や、印刷物の文字を表す2値画像の認識などに活用されていました。
コンピュータによる画像認識は、非常に高度かつ複雑な処理が必要になります。そのため当時は、技術が足りず研究が難航する状態が続きました。
1970年代からはコンピュータが大学や研究室に普及しだし、それに伴って画像認識技術も発達していきました。
機械学習の登場
2000年代に入ってからは、計算機やデジタル機器の技術革新で、データの高速処理が可能になり、画像認識がさらに発展していきます。
インターネットの普及も相まって、画像認識技術は一般的な存在として世の中に広がっていきました。「デジタルカメラ」や「ネットでの画像検索」などが、その最たる例です。
また、大量のデータからパターンを見つける「機械学習」を、画像認識に応用することで、より効率的かつ正確な画像認識ができるようになりました。
▼機械学習について詳しく知りたい方はこちら

ディープラーニングの登場
2012年、ILSVRCという大規模な画像認識コンテストにてトロント大学のチームが圧勝したことをきっかけに、画像認識はさらに躍進します。
このコンテストは2012年以前、毎年1%~2%単位でエラー率を減少させていました。
しかしこの2012年のトロント大学は、ディープラーニングの手法の一つである「CNN(畳み込みニューラルネットワーク)」を活用したことにより10%程度もエラー率を改善したのです。
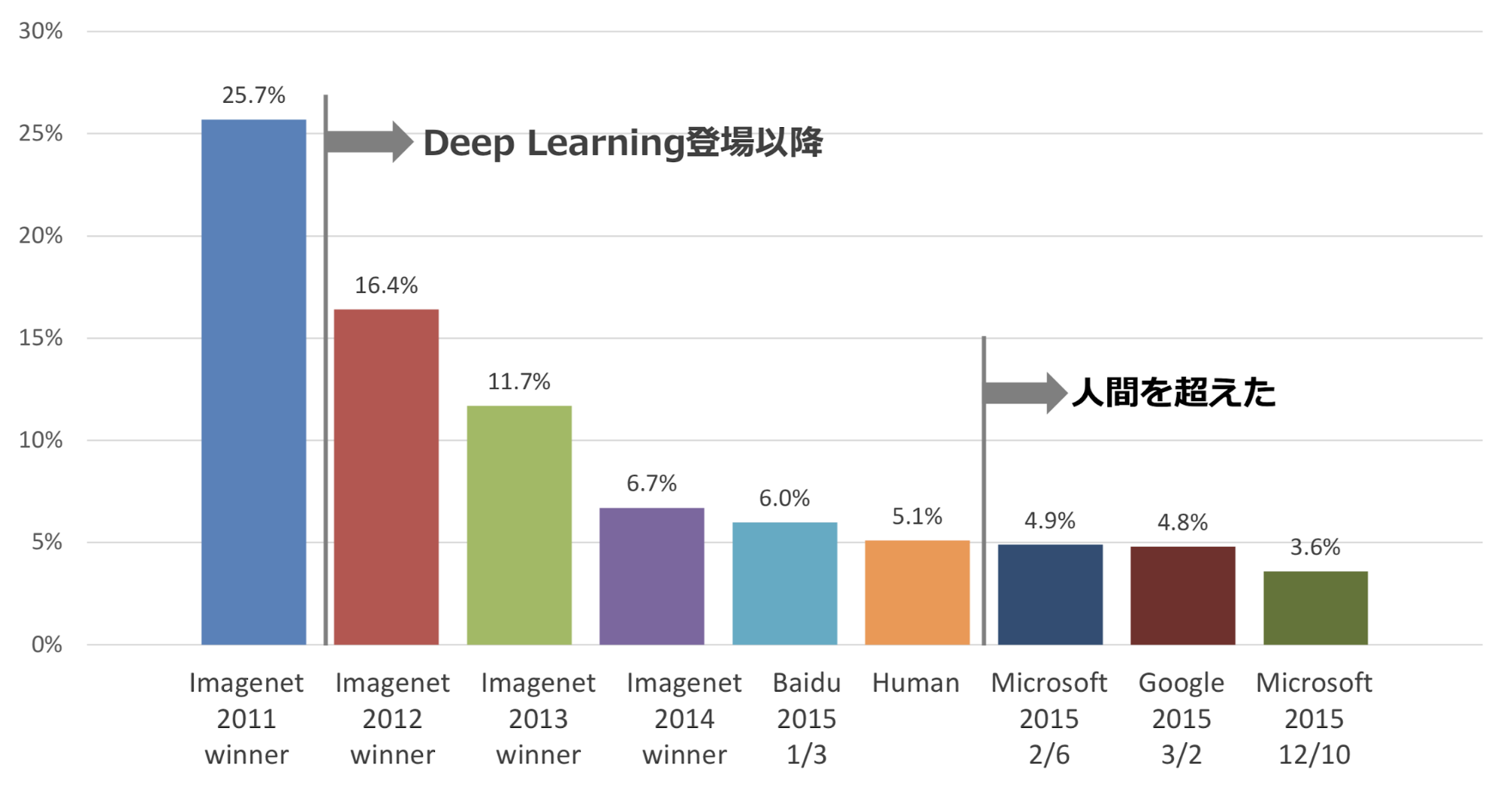
2012年以降の画像認識におけるエラー率の推移
この衝撃の結果がディープラーニングへの注目を集めAIブームを引き起こすきっかけになりました。それ以来、画像認識は今でもディープラーニングのメジャーな活用方法となっています。
現在の画像認識コンテストでは、上位のほとんどのモデルがディープラーニング(CNN)を利用しており、正答率は95%以上と、すでに人間のレベルを超える領域に達しています。
ディープラーニングの魅力は「人間がデータ内の特徴を指定しなくてもAIが自動で画像から特徴を取り出して、アルゴリズム作成までしてくれる」という点です。
ディープラーニングが登場して以降、技術者がいなくても比較的容易に画像認識ができるようになったため、現在はさまざまな場面で画像認識の活用が進んでいます。
▶CNN(畳み込みネットワーク)とは?図や事例を用いながら分かりやすく解説!>>
▼ディープラーニングについて詳しく知りたい方はこちら

画像認識の仕組み
ここからは「コンピューターやAIがどのようにして画像認識をしているのか」ということについて解説していきます。
画像認識を行うには、まず画像処理(画像から対象物を抽出)をしなければなりません。
私たちは、容易に画像に写っている対象物が何なのかを判断できます。例えば、下記の画像を見たとき、犬が1匹写っていることは一瞬で理解できますよね。

私たちが画像の犬を視覚で理解できる一方で、コンピュータは以下のように画像データを「ピクセル毎の情報(色合い、明るさ)の集合体」として捉えます。
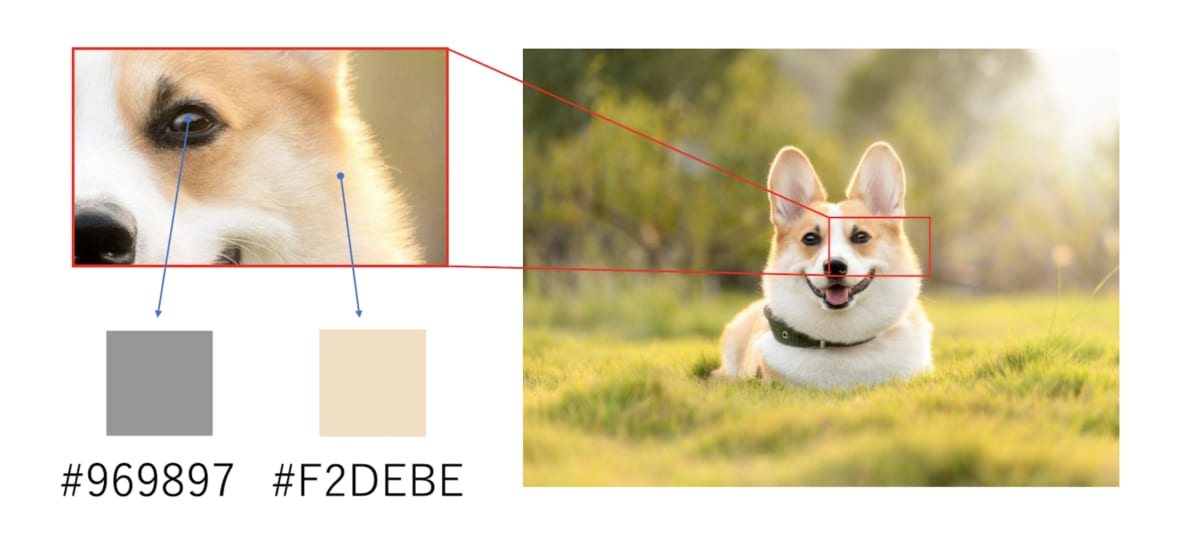
AINOW編集部作成
画像の対象物はさまざまな角度、大きさ、明るさ存在しており、ノイズだらけの情報から対象物を認識しなければなりません。
そのため、「この画像に何が写っているのか」を理解しやすくなるように、4つの処理を行います。
- 画像のノイズや歪みを除去
- 明るさや色合いを調整
- オブジェクトの輪郭を強調
- オブジェクトの領域を切り出す(領域抽出)
このようなステップを踏むことで、コンピュータは画像処理を行い、画像の情報(色・明るさなど)を抽出します。
領域抽出が完了したら、次は画像認識です。
従来の画像認識では、機械学習が使われていました。
機械学習では、大量の画像データとラベル(画像データが何を表すか)を与え、その組み合わせをもとにして自動でラベル毎の画像データの特徴を学習します。
しかし、従来の機械学習では、画像から特徴を抽出することをコンピュータのみで行うのは困難であり、特徴データを人間が与える必要がありました。
そこで登場したのが、前述にもあったディープラーニングです。
ディープラーニングを利用した画像認識
ディープラーニングを利用する画像認識では、大量の画像データさえ与えれば、そこから自動で特徴データを抽出できます。
例えば、猫の画像を従来のシステムが猫と判断するには、耳の形や髭の本数、顔の形や色など、細かい部分までエンジニアが定義しなければなりませんでした。
しかし、ディープラーニングでは、大量の画像を学習することで特徴を自動的に取得し、それが猫なのか、犬なのかを判断することができるのです。
その際、畳み込みニューラルネットワークと呼ばれるネットワークモデルが使用されます。
畳み込みニューラルネットワークは、人間の脳内の神経回路網を表現したニューラルネットワークと呼ばれるネットワークモデルを発展させたものです。
畳み込みニューラルネットではまず、画像データの一部分にフィルタをかけ演算し、その領域をスライドさせて繰り返していく「畳み込み」を行い、特徴マップを生成します。
この処理によって、画像が持つ局所的な特徴を抽出できるようになります。このようにしてコンピュータは画像の特徴を繰り返し抽出し対象物を推測し、また正解データで答え合わせをして学習しながら、画像認識の精度を高めていくのです。
ディープラーニングの学習能力は、特徴の識別が難しい画像認識の分野で特に恩恵を受けやすいため、物体認識の精度向上に大きく役立っています。
▶関連記事|画像認識で機械が眼を持つ!? ディープラーニングの可能性と画像認識の事例5選>>
画像認識技術を使ったアプリ
この画像認識の技術を活用したアプリやサイトもあります。
それぞれ説明していきます。
Computer Vision API
Computer Vision APIは、画像や動画を解析して様々な情報を返してくれるサービスです。
主な機能は以下の6つです。
- 画像の解析
- 画像内のテキスト読み取り
- 画像からの手書き文字の読み取り(プレビュー/プレビューはアルファベットのみ対応)
- 著名人の認識
- ほぼリアルタイムで動画を分析
- サムネイルの生成
▼サイトはこちら
Google翻訳
 出典:Google[/caption]
出典:Google[/caption]
Google翻訳を使ったことがある人は多いのではないでしょうか。
Google 翻訳はGoogleが提供する翻訳サイトで、テキスト(5000字以内)、もしくはウェブページ全体を他言語に翻訳するサービスです。文章の言語識別や、入力した文字を即座に反映させるリアルタイム翻訳、音声入力機能があります。
AIメーカー
 出典:AIメーカー[/caption]
出典:AIメーカー[/caption]
AIメーカーとは、画像を認識・分類するAIを誰でも簡単に作れるサービスです。Twitterアカウントと連携させた上で、識別させる画像のタグを入力し、学習データとして各タグに対応した画像データをアップロードするか、画像検索機能を使って手作業で追加し、学習させれば画像を判別するAIを作成できます。
▼サイトはこちら
[btn]AIメーカーImageJ
出典:ImageJ
ImageJはオープンソースでパブリックドメインの画像処理ソフトウェアです。Javaの仮想マシン上で動作し、プラグインやマクロによる拡張性が高いことが特徴となっています。科学研究における画像解析に広く利用され、生物学ではデファクト・スタンダードの解析ツールです。
▼ダウンロードはこちらから
OpenCV
出典:OpenCV
画像処理・画像解析および機械学習等の機能を持つC/C++、Java、Python、MATLAB用ライブラリで、さまざまな機能があります。
▼サイトはこちら
画像認識導入のプロセス
ここまで画像認識の活用事例を紹介してきましたが、実際に画像認識を導入したい場合はどうすれば良いのでしょうか。
画像認識モデルの作成には大きく3つのプロセスがあります。
- 目的とそれに応じた認識モデルの精度を決定
- それを基にデータを収集してモデルを作成
- 開発したモデルの評価を繰り返して精度を向上
このようなプロセスを経るAI導入では、3つの躓きやすいポイントがあります。
- 開発技術が自社にない
- 既存の業務、事業の定義が不足している
- データの量の不足や整理の不足
特に開発技術が自社にない場合の多くは、導入受注企業などと相談しながら解決してくことになります。
つまり、画像認識モデルの作成における3つのプロセスで最も大事なことは、「目的の設定」です。
人の命が関わる産業なのか、費用が削減できれば良いのか、どのくらいの予算規模で開発するのかなど、既存の事業のあり方によって画像認識を含めたAIに求められる役割も変わります。
そのため、目的の部分を開発サイドに丸投げせずに、自社でもきちんと考えることが重要です。
画像認識の今後
画像認識には現在以下のような課題があります。
- バイアスの問題
- データ量の問題
- 説明可能性の問題
バイアス問題とは特定の要素がAIのアルゴリズムに影響を与えてしまうというもので、Googleが開発した画像認識システムが、黒人男性の画像を「ゴリラ」と判別したことが例として挙げられます。
また、機械学習には大量のデータが必要とされますが、あらゆる分野や用途において常に大量データが集まるとは限りません。そのため、少ないデータのみでの機械学習が可能になれば、さらにAIの応用分野が広がっていくでしょう。
説明可能性の問題とは、なぜAIがそのような結論を導き出したのか、人間に理解できるように説明する技術のことを指します。ディープラーニングのアルゴリズムは極めて複雑であるため、AIが示した結果までの思考過程がわかっていないままAIの導き出した答えを盲信してしまう危険があります。
その一方で、2025年の画像認識関連技術の国内市場は、2018年の3.1倍である746億円になると予想されています。
今後は画像認識技術の活用分野を広げていくと同時に、課題の解決にも尽力していく必要があるでしょう。
まとめ
今回は、「画像認識」について解説してきました。いかがだったでしょうか。
人間の目によって行われている仕事は膨大にあるため、画像認識は技術の進歩と発想次第で、さまざまな活用の可能性が秘められています。
画像認識は、AIの中でも特に市場が拡大している分野です。
異常検知や顔認証などのメジャーな活用事例はもちろん、最近ではカメラで手書き文字を認識して、文字データに変換する技術「AI-OCR」の活用も進んでいます。
今後も活用の幅を広げ、より私たちの身近な存在になるであろう画像認識の動向には目が離せません。
▼YouTubeでもこの記事について解説中!
◇AINOWインターン生
◇Twitterでも発信しています。
◇AINOWでインターンをしながら、自分のブログも書いてライティングの勉強をしています。



























