

機械学習をしていくうえで、一度は直面する過学習(過剰適合)をご存じですか?
過学習が起きてしまうと、予測したいモデルに良からぬ影響をもたらしてしまいます。では、どうすれば過学習を未然に防ぐことができるのでしょうか?
本記事では、過学習とはなにか、その具体例から原因、対策などをご紹介しています
目次
機械学習における過学習(過剰適合)とは
過学習(Overfitting)「別名:オーバーフィッティング / 過剰適合」は、データ分析で陥りやすいトラブルの1つです。
過学習とは、機械学習を行う際にあらかじめ用意してある訓練データをコンピュータが学習しすぎた結果、その訓練データに過剰に適合しすぎ、未知データ(テストデータ)に対しては適合できていない(汎用性がなくなった)状態のことを指します。
この表現だと少し分かりづらいかもしれないため、身近に置き換えて分かりやすい例を挙げてみます。
「学校のテスト」をイメージしてください。テスト前のテスト対策として「過去問」を解くと思います。Aさんはこのテスト対策でひたすら似たような過去問ばかりを解いており、「問題」と「答え」の組み合わせだけしか覚えておらず、いざ本番のテストを受けてみると過去問には出題されていなかった新規の問題ばかりで全く解けないといった状況があったとします。これがいわゆる過学習の状態です。

▼関連記事
・機械学習におけるモデルとは?|モデルの種類や「よいモデル」とは何かについて
・機械学習に欠かせない、特徴量とその選択手法とは
機械学習で起きてしまう過学習の具体例
では一体、過学習となってしまった場合どのようなモデルが作成されるのでしょうか?
①学習不足、②適切、③過学習の3つを見ていきましょう。
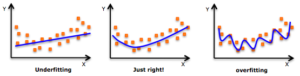
こちらのグラフは、左から①学習不足、②適切、③過学習と並んでいます。
一見すると、右のグラフが一番与えられたデータに沿っているように見えますが、これこそが過学習となったモデルであり、過剰適合してしまっています。
このようになってしまうとまったく使い物にならない機械学習モデルとなってしまうため、即座に対応が必要です。
- 学習不足:訓練データの特徴を捉えるだけでモデルの複雑さがない
- 適切:訓練データの特徴を十分に捉えている
- 過学習:訓練データに過剰適合してしまい未知データに汎化されない
機械学習で過学習が起こる3つの主な原因
過学習がデータ分析で陥りやすいトラブルの1つであり、データサイエンティストにとって厄介な現象です。過学習の存在を知っていても過学習を回避できずに引き起こしてしまうのは一体なぜでしょうか。その主な原因3つを紹介していきます。
①訓練データの不足
過学習の大きな原因の1つとして、訓練データが不足しているケースです。
過学習と聞くと、過度に学習しすぎてしまったもの(データが多い)と誤解されやすいですが、実はデータが不足しているせいで正常な学習を妨げてしまっているのが原因です。
人間は新たに仕事が割り振られても、必要なデータ以外にこれまでの経験や常識などからある程度対応できたり効率的に学習を進めたりすることができますが、機械学習は訓練時に得られるデータが全てです。
つまり、与えられるデータが少なければ、その少ないデータから分析をしていくことしかできずに偏ったデータにのみしか対応できません。
そのため、正しいデータの分析を実現するためには目的に合わせて十分な量のデータを確保し、学習させる必要があります。
▶テキストAIの学習データ不足 ―アメリカに遅れを取る日本が講ずべき対策
②偏ったデータの学習
データを学習させる際に注意すべきこととしてもう1つ重要なことが、偏ったデータを学習させてしまうことです。
①でも述べた通り、機械学習が与えられたデータからしか分析を行うことはできません。そのため、フラットな分析を行うために本来であればなるべく偏りがなく豊富なデータを学習させる必要があります。
不十分なデータでモデルを構築したり、都合の良いデータだけを学習させるなど、偏ったデータばかりを学習させてしまうと、その機械学習モデルは客観性に欠け、偏った分析・予測しかできず、モデルの構築そのものに悪影響を及ぼしてしまいます。
正しいデータ分析をするためには、正しく豊富なデータを用意しましょう。
③作りたい機械学習モデルの目的が不明確
モデルを構築する前段階として、「どんなモデルを構築するのか?」という目的が絶対条件として必要です。
機械学習のみに限らずAIは基本的にシングルタスクに特化した実用性しか持っておらず、1つのデータから様々なタスクを汎用的に実行することはできず、人間側でコントロールしてあげなければいけません。
店舗の売り上げを予測したいのか、人口増加率を予測したいのか、何をしたいのか不明確な状態のままでモデルの構築をしてしまうと、不必要なデータを学習させてしまったり偏ったデータを学習させてしまう原因になります。
「店舗の売り上げを予測するモデル」を構築する。などというように目的を明確化していれば、その予測に必要なデータを幅広く収集し学習させることができます。
そのため、どんなモデルを構築するのか目的を具体的に明確化し、それに適したデータを学習させることで過学習を防ぐことができます。
過学習に気づくためにすべきこと
万が一過学習に陥ってしまった場合、すぐに気づいてモデルの改善をする必要があります。
過学習に気づかずに学習・予測を進めても無意味なモデルと無意味なデータしか誕生しません。
「無意味なモデルの構築→無意味な予測値の算出」ということにならないよう、「モデルの構築→検証→改善→モデルのグレードアップ」というプロセスを踏むことが重要です。
そして、過学習の原因でも紹介したように、偏りなく十分なデータを事前に準備する必要があります。また、あらかじめ訓練データ、検証データ、テストデータを分けて区別しておくことで、モデルの精度を評価する際に困らなくなるでしょう。
そんな過学習は「バイアス」と「バリアンス」の関係性が深く、重要な考え方になるため知っておくとなおいいでしょう。
- バイアス:予測結果と実測値の差
- バリアンス:予測結果のばらつき
基本的に、バイアスとバリアンスはトレードオフの関係にあるため、いかにバランスをとれるかがとても大切です。
予測をするモデルとしてはバイアスが低い方が優秀なのですが、バイアスが低すぎると逆にノイズ(本来無視する邪魔なデータ)に対しても適合してしまうため、予測結果のばらつきが大きくなり、その結果バリアンスが大きくなっていきます。他にも、複雑なモデルを様々なデータに適合させようとしても予測値がばらつき、バリアンスが大きくなってしまいます。
傾向として、バイアスが低くバリアンスが高い状態は過学習に陥っている可能性が高いため、注意して観察するといいでしょう。
機械学習で過学習を起こさないための手法3選
過学習の発生原因を知っており、しっかりと気を付けていても過学習を引き起こしてしまう可能性は十分にあります。
では、どうすれば過学習を回避することができるのでしょうか。
過学習を引き起こさないための手法を3つ紹介していきます。
①ホールドアウト法(hold-out)
ホールドアウト法とは機械学習におけるデータのテスト方法の1種であり、モデル評価の中で最もシンプルな手法です。
ホールドアウト法では、全てのデータセットの中からモデルを作る訓練データ(x_train, y_train)と、モデルを評価するテストデータ(x_test, y_test)に分割して学習済みモデルの精度を評価します。
100個のデータを持っていれば6:4や7:3などランダムに分割し、訓練データを60個、テストデータを40個などというふうに分けます。(テストデータを少なく割り振る方が多い)
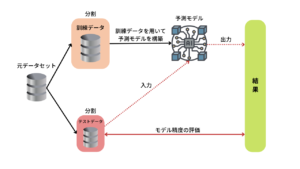
AINOW編集部作成
このようにデータを分割してモデルを構築することによって、未知のデータに対する性能(汎化性能)を向上させることができ、過学習の起きにくいモデルを作成することが可能ですが、元データ(サンプル数)が少ない場合は評価値にばらつきが発生するのが欠点です。
②交差検証(cross-validation)
交差検証法とは、ホールドアウト法と同じく訓練データとテストデータ(検証データ)を分割する手法の1つですが、ホールドアウト法とは少し違った分割方法でモデルの構築を行います。
ここでは交差検証の中でもよく利用されるK-分割交差検証をご紹介します。
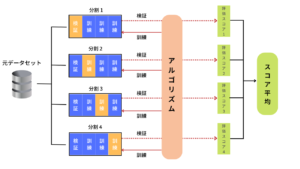
AINOW編集部作成
K-分割交差検証法では、元データをk個のデータセットにランダムに分割します。分割されたk個のデータセットの1つをテストデータ、残りを訓練データとしてモデルの構築を行います。
そして、分割された全てのデータセットは順番にテストデータとして検証されていきます。検証するデータセット間に重複のないことから、ホールドアウト法をk回繰り返すよりも信頼性の高い評価方法とも言えますが、k通りの分割と検証を実行する分、データ量が10万以上など膨大な量になるとCPUに計算負荷がかかり計算に時間がかかるという欠点があります。
③正則化(min-max normalization)
正規化とは、過学習に伴い複雑化してしまったモデルをより単純なモデルにしていく手法で、回帰や分類などの分析手法においても使える汎用性の高い過学習対策手法の1つです。
用意してあるデータの中から複雑なデータ、滑らかでないモデルにペナルティを与えて重みを下げたり、孤立したデータを無視するなどでモデルを単純化しています。
(機械学習分野では過学習改善のための工夫を総じて正規化と呼んだりもします。)
正規化には2つの手法があり、それぞれ目的別に使い分けます。
- L1正規化:必要な説明変数をはっきりさせる(必要のない説明変数の影響を0にする)
- L2正規化:予測モデルを滑らかにする(モデルを複雑化させている影響を小さくする)
使い分け方として以下の方法があります。
| データ数&説明変数の数も多い場合 | L1正規化を用いて説明変数の数を減らす |
| データ数&説明変数の数も多くない場合 | L2正規化を用いて偏回帰係数を最適化する |
正規化についてはQiitaで詳しく解説されていますので、詳しく知りたい方はチェックしてみてください。(Qiita記事:機械学習でなぜ正規化が必要なのか)
▼関連記事
・機械学習の手法13選 ー 初級者、中級者別に解説!
・SVM(サポートベクターマシーン)とは|仕組み・メリット・勉強方法
・正確な予測で無駄を削減!AI予測の活用事例まとめ
まとめ
いかがでしたでしょうか。
本記事では、機械学習における「過学習」について紹介していきました。
機械学習を使ってデータ分析等を行う際は過学習が付きものであるため、しっかりと対策をしていかなくてはいけません。
ホールドアウト法、交差検証、正規化、今回紹介していない手法以外にも過学習を防ぐための対策がしっかりとあるため、機械学習でデータを扱う際は目的に合った手法を使って正しく精度の高いモデルを作成していきましょう!


























